Agents in generative AI applications provide powerful techniques for coordinating an AI system and augmenting it with additional capabilities. NVIDIA NIM™, a set of microservices for deploying AI models, supports agents using models that are trained for agentic behavior. NIM microservices integrate with many frameworks like LlamaIndex and LangChain to support using NIM for agentic applications. In this example, we’ll show you how to use them with LlamaIndex.
NVIDIA NIM for Agents
An agent is an entity that uses the capabilities of an LLM to perform a set of actions, or use tools, within a system state to achieve a desired outcome. They often involve reasoning, planning, executing, and responding to changes in the environment.
NIM microservices provide a route to deploying production-ready, best-performance agents anywhere. They are part of NVIDIA AI Enterprise, a set of easy-to-use microservices designed for secure, reliable deployment of high-performance AI model inferencing across the cloud, data center and workstations with industry-standard APIs.
NIM microservices are available to test for free from NVIDIA’s API catalog to build agents with LlamaIndex.
Why Use Agents?
Agents are powered by LLMs to perform complex tasks using data and reasoning to inform their decision-making process. With agents, a goal is set by a human and an agent reasons and makes decisions, choosing what actions are needed to accomplish them. They excel in complex systems that may require splitting out subtasks to other models or tools.
Let’s talk about agents in an example use case. Retail chatbots are used to assist customers in their product experience. A retail chatbot equipped with an agent may provide customers with more insight and value than a chatbot without an agent. For instance, an agent could recognize when to use a tool to search through customer reviews to provide information to a user query like, “What is the fit of this clothing?” While information about the fit of the clothing may not be available in descriptions of the product, it may be available in reviews. A chatbot without an agent would be restricted to just looking at the description, whereas an agent-equipped chatbot could reason that it should look at reviews to get the best answer to the customer’s question. With agents, systems like retail chatbots can make better decisions to assist shoppers.
Complex user queries can also be handled by agents; agents can break down these queries into smaller questions and route them to appropriate query engines. This is commonly known as “router agents” and results in more accurate responses. Suppose you are building a chatbot for 10-K reports (annual financial disclosures for public companies in the United States). We’ll take NVIDIA as an example. When a user asks, “How do NVIDIA’s earnings for the third quarter of 2023 compare to now?” An agent could be equipped to break down this query into subqueries like:
- What were NVIDIA’s earnings?
- What were NVIDIA’s most recent earnings?
- What were NVIDIA’s earnings in the third quarter of 2023?
Then these sub-questions can be answered and, if applicable, the agent will use the retrieved answers to form a full response.
The agent also can be provided with a set of tools that can help answer some of the sub-questions. For example, there could be a set of tools, where each tool is responsible for answering questions about NVIDIA’s financials for a specific year. By leveraging tools in this way, it can be assured that the agent routes queries about a given quarter to the appropriate fiscal year’s information.
In this blog, we’ll cover how to use LlamaIndex with NIM to build a query router for answering questions related to San Francisco city budget data.
Query Routing Agent with LlamaIndex
The full code for this blog is in this notebook, but snippets are explained in this post as well. In this example, we’ll use an agent enhanced query engine with LlamaIndex. This query engine will first break down a complex query about San Francisco’s budget into subqueries. Because the subqueries are best answered by different source documents, the agent is equipped with tools to reference the correct source document. Once all the relevant queries have been answered, the agent will coalesce the information into a comprehensive response.
Let’s get into the technical details of how this is done!
Getting Started
Two sets of NVIDIA NIM are used in this example:
- NV-EmbedQA-E5-v5 NIM microservice is used to convert document chunks and the user query to embeddings with LlamaIndex.
- Llama 3.1 8B NIM microservice is used to power the agent with LlamaIndex.
To get started quickly, access the NIM microservices as hosted APIs at https://build.nvidia.com. Or, if you’d like, you can host the NIM microservices yourself by downloading them through https://build.nvidia.com and following documentation.
Using NIM Microservices with LlamaIndex
NIM microservices are easy and flexible to deploy as well as simple to use with LlamaIndex. Once they’re deployed, to use them with LlamaIndex, you will need to install the NVIDIA LlamaIndex packages.
sh
pip install llama-index-llms-nvidia llama-index-embeddings-nvidiaNext, declare the NIM you will use. An API key is required if you are using NIM hosted by NVIDIA. It is assumed that your NVDIA API key is stored as an environment variable within the operating system. More documentation on using NIM with LlamaIndex is available here.
python
from llama_index.llms.nvidia import NVIDIA
from llama_index.embeddings.nvidia import NVIDIAEmbedding
Settings.embed_model = NVIDIAEmbedding(model="nvidia/nv-embedqa-e5-v5", api_key=os.environ["NVIDIA_API_KEY"],truncate="END")
Settings.llm = NVIDIA(model="meta/llama-3.1-8b-instruct", api_key=os.environ["NVIDIA_API_KEY"])Sub-Question Query Engine
A query engine is a concept in LlamaIndex that takes in natural language and returns a rich response. In this example, we create a sub-question query engine. It takes a single, complex question and breaks it into multiple sub-questions, each of which can be answered by a different tool.
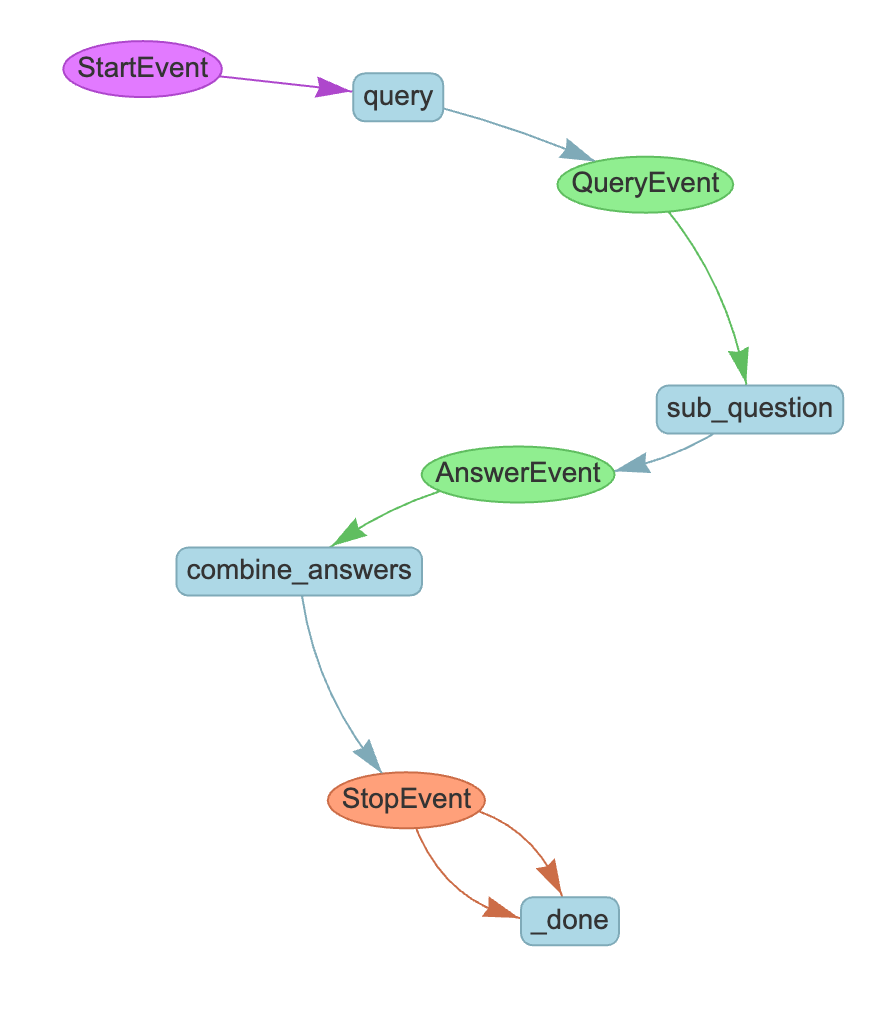
This query engine is declared as a Workflow, which is another concept in LlamaIndex. Workflows are event driven and are used to chain together several events using steps. Workflows use the @step decorator on individual functions to define steps. Each step is responsible for handling certain event types and emitting new events. This decorator also infers input and output types for the step.
There are 3 steps in this query engine that connect to one another through the event stream. Let’s break these down.
Step 1: Break down original query
query : takes an original query and splits it into subquestions.
Step 2: Generate subquestions
sub_question : for a given subquestion, generate a response from a ReAct agent equipped with tools.
If you recall from earlier, the tools are useful for providing the agent with more unique ways to pull from data. ReAct (reasoning and acting) is a common agent implementation that uses prompting to guide an LLM to dynamically create, maintain, and adjust plans through explaining reasoning and actions. If you want to see what the prompt for this example looks like, you can view it in LlamaIndex’s source code here!
An answer for each individual subquestion is generated.
Step 2: Combine answers
combine_answers : combine the individual answers into a full response.
Check out the sub-question query engine code below!
python
class QueryEvent(Event):
question: str
class AnswerEvent(Event):
question: str
answer: str
class SubQuestionQueryEngine(Workflow):
@step
async def query(self, ctx: Context, ev: StartEvent) -> QueryEvent:
if hasattr(ev, "query"):
await ctx.set("original_query", ev.query)
print(f"Query is {await ctx.get('original_query')}")
if hasattr(ev, "llm"):
await ctx.set("llm", ev.llm)
if hasattr(ev, "tools"):
await ctx.set("tools", ev.tools)
response = (await ctx.get("llm")).complete(
f"""
Given a user question, and a list of tools, output a list of
relevant sub-questions, such that the answers to all the
sub-questions put together will answer the question. Respond
in pure JSON without any markdown, like this:
{{
"sub_questions": [
"What is the population of San Francisco?",
"What is the budget of San Francisco?",
"What is the GDP of San Francisco?"
]
}}
Here is the user question: {await ctx.get('original_query')}
And here is the list of tools: {await ctx.get('tools')}
"""
)
print(f"Sub-questions are {response}")
response_obj = json.loads(str(response))
sub_questions = response_obj["sub_questions"]
await ctx.set("sub_question_count", len(sub_questions))
for question in sub_questions:
self.send_event(QueryEvent(question=question))
return None
@step
async def sub_question(self, ctx: Context, ev: QueryEvent) -> AnswerEvent:
print(f"Sub-question is {ev.question}")
agent = ReActAgent.from_tools(
await ctx.get("tools"), llm=await ctx.get("llm"), verbose=True
)
response = agent.chat(ev.question)
return AnswerEvent(question=ev.question, answer=str(response))
@step
async def combine_answers(
self, ctx: Context, ev: AnswerEvent
) -> StopEvent | None:
ready = ctx.collect_events(
ev, [AnswerEvent] * await ctx.get("sub_question_count")
)
if ready is None:
return None
answers = "\n\n".join(
[
f"Question: {event.question}: \n Answer: {event.answer}"
for event in ready
]
)
prompt = f"""
You are given an overall question that has been split into sub-questions,
each of which has been answered. Combine the answers to all the sub-questions
into a single answer to the original question.
Original question: {await ctx.get('original_query')}
Sub-questions and answers:
{answers}
"""
print(f"Final prompt is {prompt}")
response = (await ctx.get("llm")).complete(prompt)
print("Final response is", response)
return StopEvent(result=str(response))Run the Agent Enhanced Subquestion Query Engine
We’ve skipped over creating the query engine tools, but this is available in the full notebook for reference. In short, each tool is an individual query engine based on a singular, but lengthy (300+ pages) SF budget document.
python
engine = SubQuestionQueryEngine(timeout=120, verbose=True)
result = await engine.run(
llm=Settings.llm,
tools=query_engine_tools,
query="How has the total amount of San Francisco's budget changed from 2016 to 2023?",
)
print(result)In the results, we can see that sub questions are generated and the ReAct pattern is used across the sub questions. The full output is truncated for readability, but run the notebook to view the full answer!
text
Sub-question is What is the budget of San Francisco in 2016?
> Running step 543e99b5-0b95-40a1-969c-f2ccecbcf405. Step input: What is the budget of San Francisco in 2016?
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: budget_2016
Action Input: {'input': 'What is the budget of San Francisco in 2016?'}
Observation: According to the provided information, the budget of San Francisco in 2016-17 is $51,569,787.
> Running step fc16dc8e-de61-4221-9cd9-0e2831a20067. Step input: None
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: The budget of San Francisco in 2016 is $51,569,787.
Step sub_question produced event AnswerEvent
Running step sub_question
Sub-question is What is the budget of San Francisco in 2023?
> Running step 6eca7b14-7748-4daf-a186-8338995605ef. Step input: What is the budget of San Francisco in 2023?
Observation: Error: Could not parse output. Please follow the thought-action-input format. Try again.
> Running step d8fed16d-6654-4b15-bc4d-3749e0d600de. Step input: None
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: budget_2023
Action Input: {'input': 'What is the budget of San Francisco in 2023?'}
Observation: The budget of San Francisco in 2023 is $14.6 billion.
> Running step 90f90257-aca3-4458-a7f6-f47ea3e10b48. Step input: None
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: The budget of San Francisco in 2023 is $14.6 billion.
...You can see the final response below.
text
The budget of San Francisco in 2016 was $51,569,787, and the budget in 2023 is $14.6 billion. Therefore, the total amount of San Francisco's budget has increased significantly from 2016 to 2023, with a change of approximately $14.6 billion - $51,569,787 = $14,548,213,213.Next Steps
Check out the Jupyter notebook with the full code for LlamaIndex and NVIDIA NIM. You can ask multi-step queries about SF housing data or you can adapt it to work on your own information.
Head to build.nvidia.com to get started with NIM microservices in the notebook!