We’re pleased to be introducing a brand-new beta feature of LlamaIndex: workflows, a mechanism for orchestrating actions in the increasingly-complex AI application we see our users building.
What started as a trend with the advent of LLMs is now a de-facto standard: AI applications are made of multiple tasks implemented by different components. Open source frameworks in the market strive to make the life of AI engineers easier by providing easy-to-use abstractions for foundational components like data loaders, LLMs, vector databases, and rerankers, all the way up to external services. Meanwhile, all of those frameworks are also on a quest to find what’s the best abstraction to orchestrate such components, researching what’s most intuitive and efficient for an AI developer in order to implement the logic that keeps together a compound AI system.
Two of those potential orchestration patterns are chains and pipelines, both of which are implementations of the same Directed Acyclic Graph (DAG) abstraction. We took a stab at this with our Query Pipelines release at the beginning of the year - it was a declarative API that let you orchestrate simple-to-advanced query workflows over your data for different use cases, like QA, structured extraction, and agentic automation. But as we tried to build upon it and experimented with adding cycles to better support more complex workflows, we noticed several issues, causing us to reflect on why a DAG may not be the right fit for an agentic landscape, and what alternatives we could introduce in the framework.
Limitations of a Graph-based UX
A fundamental aspect of DAGs is the “A” in DAGs: they are acyclic, meaning there are no loops. But in a world that’s more and more agentic, the inability to perform loops in an AI application’s logic is simply unacceptable. For example, if one component provides bad results, an AI developer should have a way to tell the system to self-correct and try again.
Even without adding cycles and loops to a DAG, the query pipeline suffered from a few noticeable issues:
- hard to debug when things go wrong
- they obscure how components and modules are being executed
- our pipeline orchestrator became increasingly extremely complex and had to handle a ton of different edge cases
- they were hard to read for complex pipelines
Once we added cycles to query pipelines, these developer UX issues around graphs were amplified. We experienced first-hand developer pain in areas like:
- A lot of core orchestration logic like
if-elsestatements andwhileloops get baked into the edges of the graph. Defining these edges becomes cumbersome and verbose. - It became hard to handle edge cases around optional and default values. It was hard for us as a framework to figure out whether a parameter would get passed from upstream nodes.
- Defining graphs with cycles didn’t always feel as natural to developers building agents. An agent encapsulates a general LLM-powered entity that can take in observations and generate responses. Here the graph UX enforced that “agent” node had the incoming edges and outgoing edges explicitly defined, forcing users to define verbose communication patterns with other nodes.
We asked: are graphs really the only abstraction we can use to orchestrate components in a compound AI system?
From Graphs to EDA: go event-driven
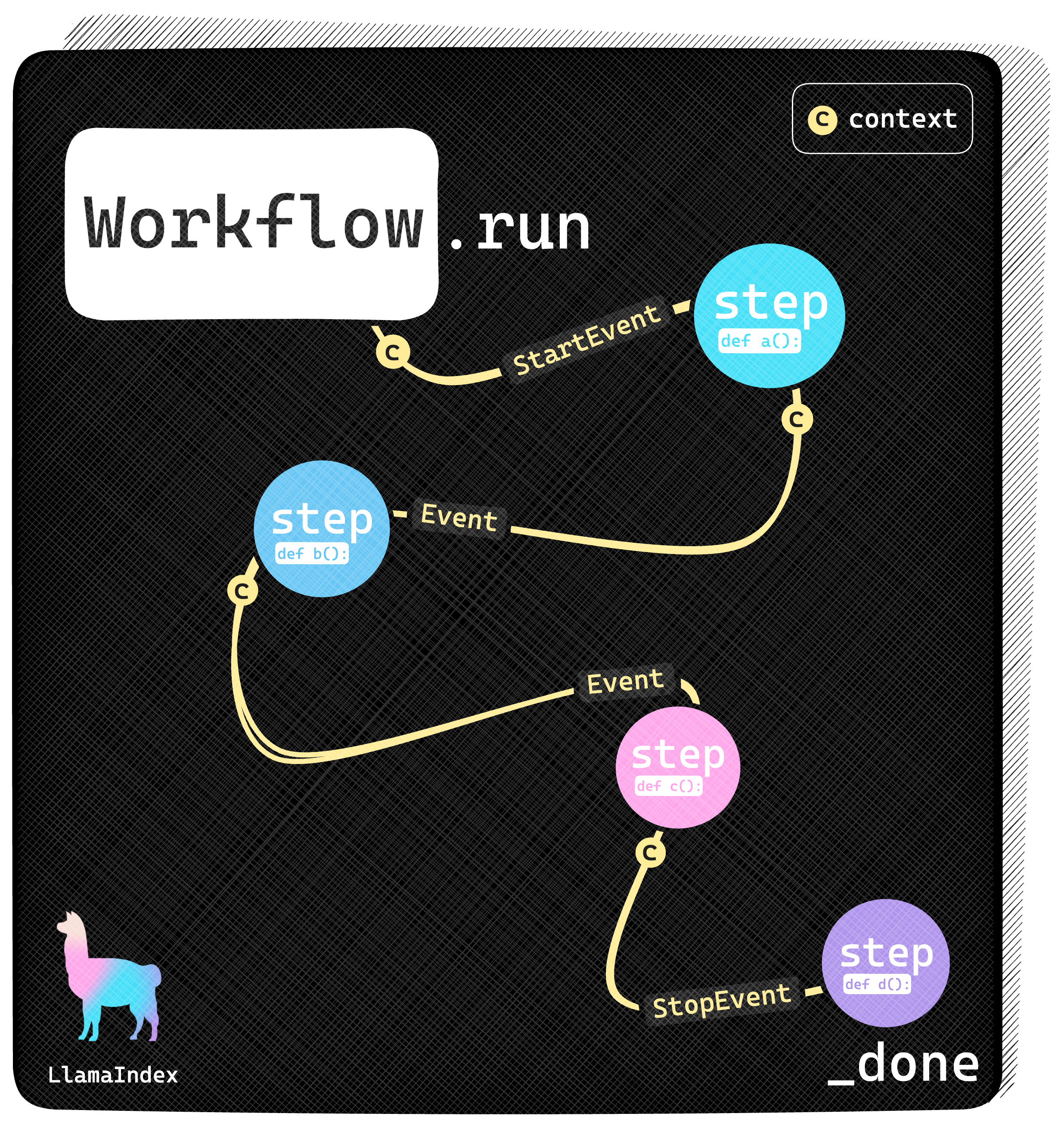
A compound AI system can be implemented with a LlamaIndex workflow. The workflow dispatches events back and forth through a collection of Python functions called steps. Each step can be seen as one component of your system: one to process a query, one to talk with an LLM, one to load data from a vector database and so on. Every step receives one or more events to process and can optionally send back events that will be relayed to other components if needed.
Moving to an event-driven architecture causes a fundamental shift in design. In many graph implementations the graph traversal algorithm is responsible for determining what component should run next and what data should be passed. In an event-driven architecture, the component subscribes to a certain types of events and it’s ultimately responsible for deciding what to do based on the data it received.
In an event-driven system, concepts like optionality of inputs and default values are sorted out at the component level, dramatically simplifying the orchestration code.
A workflow primer
To help clarify this idea, let’s look at an example. A minimal LlamaIndex workflow looks like this:
python
from llama_index.core.workflow import (
StartEvent,
StopEvent,
Workflow,
step,
)
from llama_index.llms.openai import OpenAI
class OpenAIGenerator(Workflow):
@step()
async def generate(self, ev: StartEvent) -> StopEvent:
query = ev.get("query")
llm = OpenAI()
response = await llm.acomplete(query)
return StopEvent(result=str(response))
w = OpenAIGenerator(timeout=10, verbose=False)
result = await w.run(query="What's LlamaIndex?")
print(result) The generate function is marked as a workflow step using the @step decorator and it declares which events it wants to receive and which events it will send back using the method signature with proper typing annotations. In order to run a workflow, we create an instance of the OpenAIGenerator class passing some configuration parameters like the desired timeout and we then call the run method. Any keyword argument passed to run will be packed into a special event of type StartEvent that will be relayed to the steps that requested it (in this case, only the generate step). The generate step returns a special event of type StopEvent that will signal the workflow to gracefully halt its execution. A StopEvent carries any data that we want to return to the caller as the workflow result, in this case the LLM response.
Workflows can loop
In event-driven architectures, loops have to do with communication rather than topology. Any step can decide to call another step multiple times by crafting and sending the proper event. Let’s see a self-correction loop for example (check the notebook for the full code):
python
class ExtractionDone(Event):
output: str
passage: str
class ValidationErrorEvent(Event):
error: str
wrong_output: str
passage: str
class ReflectionWorkflow(Workflow):
@step()
async def extract(
self, ev: StartEvent | ValidationErrorEvent
) -> StopEvent | ExtractionDone:
if isinstance(ev, StartEvent):
passage = ev.get("passage")
if not passage:
return StopEvent(result="Please provide some text in input")
reflection_prompt = ""
elif isinstance(ev, ValidationErrorEvent):
passage = ev.passage
reflection_prompt = REFLECTION_PROMPT.format(
wrong_answer=ev.wrong_output, error=ev.error
)
llm = Ollama(model="llama3", request_timeout=30)
prompt = EXTRACTION_PROMPT.format(
passage=passage, schema=CarCollection.schema_json()
)
if reflection_prompt:
prompt += reflection_prompt
output = await llm.acomplete(prompt)
return ExtractionDone(output=str(output), passage=passage)
@step()
async def validate(
self, ev: ExtractionDone
) -> StopEvent | ValidationErrorEvent:
try:
json.loads(ev.output)
except Exception as e:
print("Validation failed, retrying...")
return ValidationErrorEvent(
error=str(e), wrong_output=ev.output, passage=ev.passage
)
return StopEvent(result=ev.output)
w = ReflectionWorkflow(timeout=60, verbose=True)
result = await w.run(
passage="There are two cars available: a Fiat Panda with 45Hp and a Honda Civic with 330Hp."
)
print(result) In this example, the validate step receives the result of the tentative schema extraction as an event and it can decide to try again by returning a ValidationErrorEvent that will be eventually delivered to the extract step which will perform another attempt. Note that in this example the workflow might time out if this extract/validate loop keeps providing poor results for too long, but another strategy might be giving up after a precise number of attempts, just to give an example.
Workflows keep state
Workflows keep a global state during the execution, and this state can be shared and propagated to its steps upon request. This shared state is implemented as a Context object and can be used by steps to store data in between iterations but also as an alternative form of communication among different steps. Let’s see an excerpt from a more complex RAG example as an example showing how to use the global context (check notebook for full code):
python
class RAGWorkflow(Workflow):
@step(pass_context=True)
async def ingest(self, ctx: Context, ev: StartEvent) -> Optional[StopEvent]:
dataset_name = ev.get("dataset")
_, documents = download_llama_dataset(dsname, "./data")
ctx.data["INDEX"] = VectorStoreIndex.from_documents(documents=documents)
return StopEvent(result=f"Indexed {len(documents)} documents.")
... In this case the ingest step creates an index, and it wants to make it available to any other step that might needed it later during workflow execution. The idiomatic way of doing that in a LlamaIndex workflow is to declare the step requires an instance of the global context (@step(pass_context=True) does the trick) and store the index in the context itself with a predefined key that other steps might access later.
Workflows can be customized
Alongside Workflows, we’ll be releasing a set of predefined workflows so that the most common use cases can be implemented with a single line of code. Using these predefined flows, users still might want to just slightly change a predefined workflow to introduce some custom behavior without having to rewrite a whole workflow from scratch. Let’s say you want to customize a RAG workflow and use a custom re-ranking step, all you would need to do is subclass a hypothetical built-in RAGWorkflow class and override the rerank step like this:
python
class MyWorkflow(RAGWorkflow):
@step(pass_context=True)
def rerank(
self, ctx: Context, ev: Union[RetrieverEvent, StartEvent]
) -> Optional[QueryResult]:
# my custom reranking logic here
w = MyWorkflow(timeout=60, verbose=True)
result = await w.run(query="Who is Paul Graham?")Workflows can be debugged
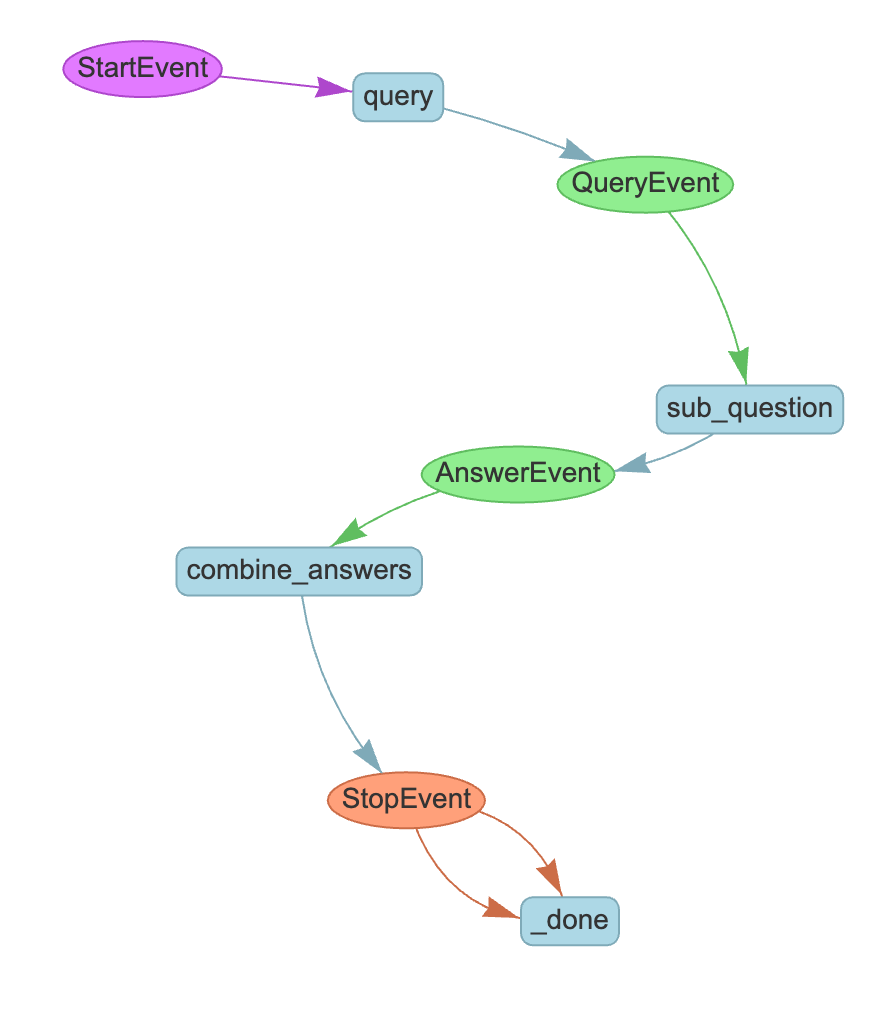
The complexity of your workflows will grow with the complexity of your application logic, and sometimes it can be hard to understand how events will flow during execution by just looking at the Python code. To ease the understanding of complex workflows and to support the debugging of workflow executions, LlamaIndex provides two functions:
-
draw_all_possible_flowsproduces a picture showing all the steps in a workflow and how events will possibly flow -
draw_most_recent_executionproduces a similar picture, showing only the events that were actually sent during the last workflow execution

On top of that, workflows can be executed manually, by calling run_step() multiple times until all the steps have completed. After each run_step call, the workflow can be inspected, examining any intermediate results or debug logs.
Why you should use workflows today
Despite being at an early stage of development, LlamaIndex workflows already represent a step forward compared to query pipelines, extending their functionalities and adding more flexibility. On top of that, workflows come with a set of features that you would normally expect from a much more mature software:
- Fully async with streaming support
- Instrumented by default, providing one-click observability with the supported integrations
- Step-by-step execution for easier debugging
- Validation and visualization of the event-driven dependencies
- Events are implemented as pydantic models to ease customization and further developments of new features
Resources
Check out our workflow documentation and our examples including: