Today, we're excited to announce the release of llama-deploy , our solution for deploying and scaling your agentic Workflows built with llama-index ! llama-deploy is the result of our learning on how best to deploy agentic systems since introducing llama-agents . llama-deploy launches llama-index Workflows as scalable microservices in just a few lines of code. Want to dive right in? Check out the docs, or read on to learn more.
llama-deploy , llama-agents and Workflows
In June we released llama-agents , a way of deploying agentic systems built in llama-index . Our microservice-based approach struck a chord with our community, with over 1K GitHub stars and a flurry of blog posts, tutorials and open-source contributions. Building on that successful experience, in August we released Workflows, a powerful, event-driven architecture for designing any kind of genAI system including agentic systems. The response to Workflows has been similarly positive.
Now we have dovetailed the two mechanisms, producing llama-deploy , which combines the ease of building LlamaIndex Workflows with a simple, native deployment mechanism for them. llama-deploy builds on the ideas and code of llama-agents , which has been folded into the new repo.
All the ideas developers loved about llama-agents are still there: everything is async-first, everything’s an independently-scalable microservice, and a central hub manages state and service registration. Anybody who used llama-agents will be able to pick up llama-deploy in seconds.
llama-deploy Architecture
We believe multi-agent systems need scalability, flexibility, and fault-tolerance in addition to easy deployment, and that’s what our architecture delivers. llama-deploy ’s architecture will be very familiar to anyone who worked with its predecessor, llama-agents .

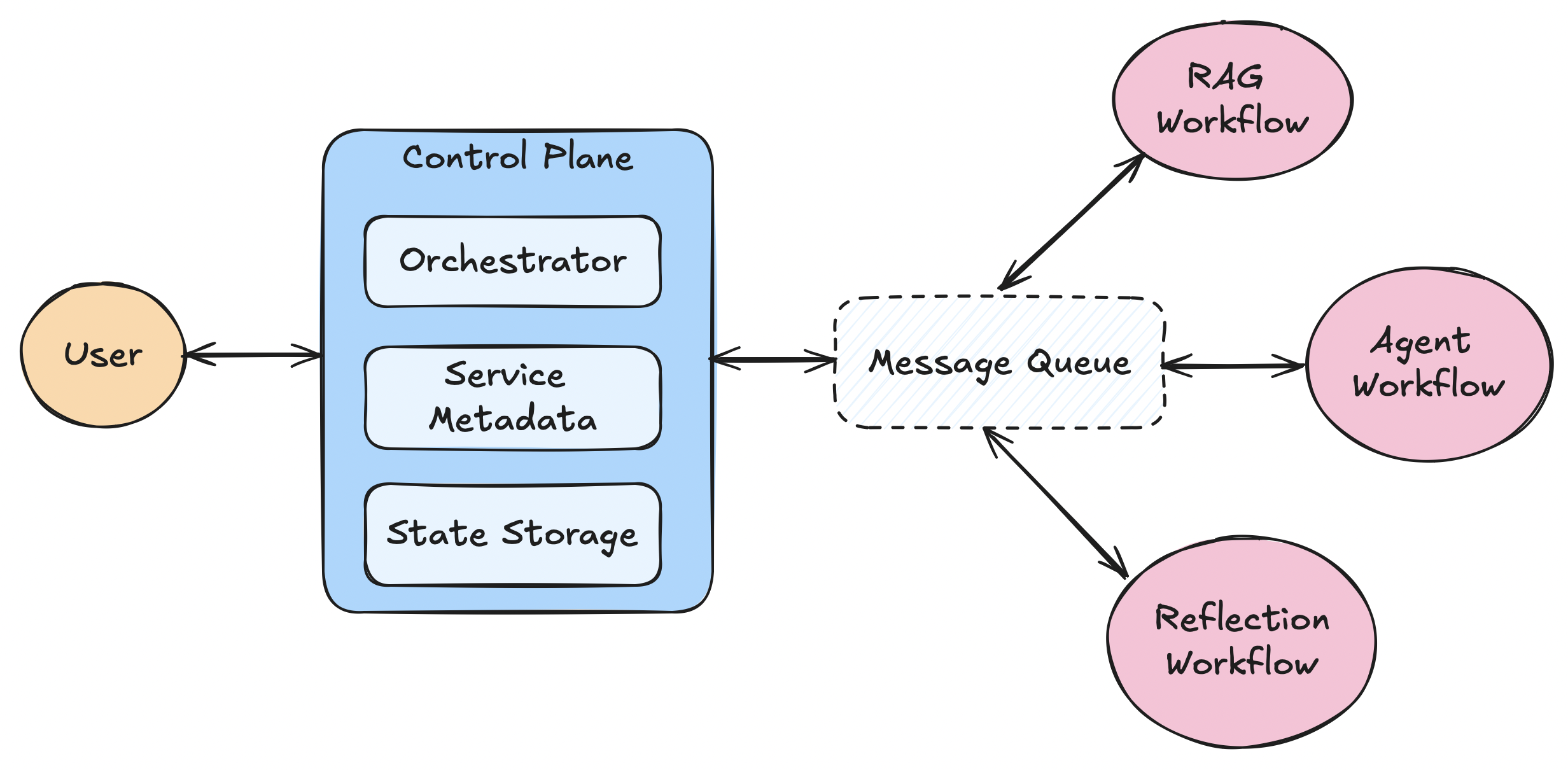
In llama_deploy , there are several key components that make up the overall system
-
message queue-- the message queue acts as a queue for all services and thecontrol plane. It has methods for publishing methods to named queues, and delegates messages to consumers. -
control plane-- the control plane is a the central gateway to thellama_deploysystem. It keeps track of current tasks and the services that are registered to the system. Thecontrol planealso performs state and session management and utilizes theorchestrator. -
orchestrator-- The module handles incoming tasks and decides what service to send it to, as well as how to handle results from services. By default, theorchestratoris very simple, and assumes incoming tasks have a destination already specified. Beyond that, the defaultorchestratorhandles retries, failures, and other nice-to-haves. -
workflow services-- Services are where the actual work happens. A services accepts some incoming task and context, processes it, and publishes a result. When you deploy a workflow, it becomes a service.
Key Features of llama-deploy
- Seamless Deployment:
llama-deployallows you to deployllama-indexworkflows with minimal changes to your existing code, simplifying the transition from development to production. - Scalability: The microservices architecture of
llama-deployenables easy scaling of individual components, ensuring your system can handle growing demands. - Flexibility: The hub-and-spoke design of
llama-deployempowers you to swap out components (like message queues) or add new services without disrupting the entire system. - Fault Tolerance: Built-in retry mechanisms and failure handling in
llama-deployensure your multi-agent AI system remains robust and resilient in production environments. - State Management: The control plane in
llama-deploymanages state across services, simplifying the development of complex, multi-step processes. - Async-First: Designed with high-concurrency scenarios in mind,
llama-deployis well-suited for real-time and high-throughput applications.
Getting Started with llama-deploy
To get started with llama-deploy , you can follow the comprehensive documentation available on the project's GitHub repository. The README provides detailed instructions on installation, deployment, and usage of the library.
Here's a quick glimpse of how you can deploy a simple workflow using llama-deploy:
First, deploy core services (includes a control plane and message queue):
python
from llama_deploy import (
deploy_core,
ControlPlaneConfig,
SimpleMessageQueueConfig,
)
async def main():
# Deploy the workflow as a service
await deploy_core(
control_plane_config=ControlPlaneConfig(),
message_queue_config=SimpleMessageQueueConfig(),
)
if __name__ == "__main__":
import asyncio
asyncio.run(main())Then, deploy your workflow:
python
from llama_deploy import (
deploy_workflow,
WorkflowServiceConfig,
ControlPlaneConfig,
)
from llama_index.core.workflow import Workflow, StartEvent, StopEvent, step
# Define a sample workflow
class MyWorkflow(Workflow):
@step()
async def run_step(self, ev: StartEvent) -> StopEvent:
arg1 = str(ev.get("arg1", ""))
result = arg1 + "_result"
return StopEvent(result=result)
async def main():
# Deploy the workflow as a service
await deploy_workflow(
MyWorkflow(),
WorkflowServiceConfig(
host="127.0.0.1", port=8002, service_name="my_workflow"
),
ControlPlaneConfig(),
)
if __name__ == "__main__":
import asyncio
asyncio.run(main())Once deployed, you can interact with your deployment using a client:
python
from llama_deploy import LlamaDeployClient, ControlPlaneConfig
# client talks to the control plane
client = LlamaDeployClient(ControlPlaneConfig())
session = client.get_or_create_session("session_id")
result = session.run("my_workflow", arg1="hello_world")
print(result) # prints "hello_world_result"Resources
See our examples and docs and API reference for more details, including using different messaging queues, deploying using Docker and Kubernetes, deploying nested workflows, and more!
The Future of Multi-Agent AI Systems
With the release of llama-deploy , we believe we're taking a significant step forward in the world of multi-agent AI systems. By empowering developers to build, deploy, and scale complex AI applications with ease, we're paving the way for more innovative and impactful AI-powered solutions.
Some features that are directly on our roadmap
- Streaming support
- Improved resiliency and failure handling
- Better config/setup options
- yaml
- environment variables
- CLI
We're excited to see what the community will create with llama-deploy , and we're committed to continuously improving and expanding the library to meet the evolving needs of the AI ecosystem.