This is a guest post from our friends at Memgraph.
In this blog post, we’ll share how Memgraph integrates with LlamaIndex. You can use LlamaIndex to transform raw data into a structured knowledge graph, which can then be queried using natural language.
Here’s a step-by-step guide to get you started, complete with installation instructions, environment setup, and a sample knowledge graph created from Charles Darwin’s biography.
Step 1: Install and Set Up Memgraph
The quickest way to get started with Memgraph (Memgraph db + MAGE library + Lab) is by running the following command:
For Linux/macOS:
sh
curl https://install.memgraph.com | shFor Windows:
sh
iwr https://windows.memgraph.com | iexOnce installed, launch Memgraph Lab, a visual tool for interacting with your database. Access it through:
- Web: http://localhost:3000
- Desktop App: Download here.
If you need further details, check out the Getting Started with Memgraph docs.
Step 2: Install LlamaIndex and Memgraph Integration
Run the following command to install LlamaIndex and Memgraph’s graph integration package:
sh
%pip install llama-index llama-index-graph-stores-memgraphThis package integrates LlamaIndex with Memgraph, allowing you to transform unstructured data into a structured knowledge graph that can be easily constructed, visualized, and queried.
Step 3: Configure Your Environment
Database Credentials
Configure LlamaIndex to connect to your Memgraph database by setting up the following parameters:
python
from llama_index.graph_stores.memgraph import MemgraphPropertyGraphStore
username = "" # Your Memgraph username, default is ""
password = "" # Your Memgraph password, default is ""
url = "bolt://localhost:7687" # Connection URL for Memgraph
graph_store = MemgraphPropertyGraphStore(
username=username,
password=password,
url=url,
)Set up OpenAI API Key
Add your OpenAI API key to your environment for embedding and query processing.
python
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Replace with your OpenAI API keyStep 4: Load and Prepare Your Data
Use a sample text file about Charles Darwin as your dataset, stored in ./data/charles_darwin/charles.txt :
text
Charles Robert Darwin was an English naturalist, geologist, and biologist, widely known for his contributions to evolutionary biology. His proposition that all species of life have descended from a common ancestor is now generally accepted and considered a fundamental scientific concept. In a joint publication with Alfred Russel Wallace, he introduced his scientific theory that this branching pattern of evolution resulted from a process he called natural selection, in which the struggle for existence has a similar effect to the artificial selection involved in selective breeding. Darwin has been described as one of the most influential figures in human history and was honoured by burial in Westminster Abbey. Load this unstructured text data using LlamaIndex’s SimpleDirectoryReader :
python
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data/charles_darwin/").load_data()The data is now loaded in the documents variable and will be used as an argument in the next steps: index creation and graph construction.
Step 5: Build the Knowledge Graph
LlamaIndex offers several graph constructors. For this tutorial, we’ll use the SchemaLLMPathExtractor to extract entities and relationships from the text automatically.
Construct the Graph
python
from llama_index.core import PropertyGraphIndex
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from llama_index.core.indices.property_graph import SchemaLLMPathExtractor
index = PropertyGraphIndex.from_documents(
documents,
embed_model=OpenAIEmbedding(model_name="text-embedding-ada-002"),
kg_extractors=[
SchemaLLMPathExtractor(
llm=OpenAI(model="gpt-4", temperature=0.0),
)
],
property_graph_store=graph_store,
show_progress=True,
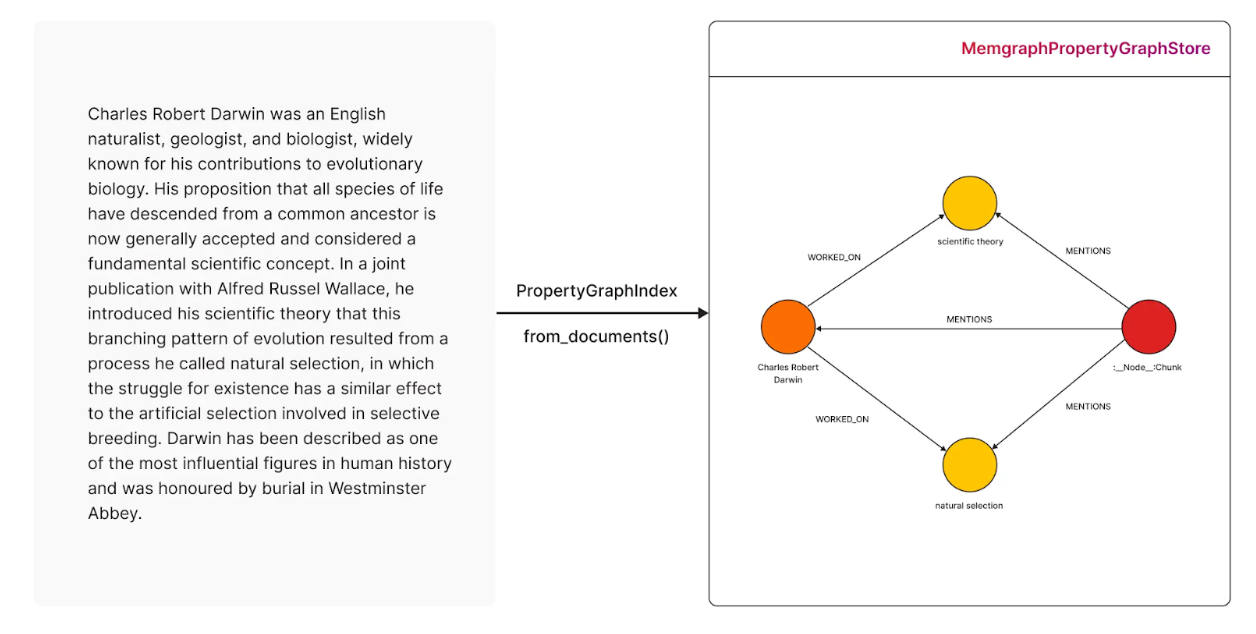
)This step creates a knowledge graph in Memgraph by identifying key concepts and their relationships from the Charles Darwin dataset. The graph is now queryable!
In the image below, you can see how the text was transformed into a knowledge graph and stored into Memgraph.

Step 6: Query the Knowledge Graph
After constructing your knowledge graph, querying becomes straightforward. LlamaIndex offers various methods to retrieve nodes and paths from the graph. If no specific retrievers are configured, the system defaults to using the LLMSynonymRetriever.
Why Natural Language Queries Matter
Using natural language, you can ask questions that would typically require complex query languages. Here, the model fetches relevant information from the graph and returns it in a human-readable format, leveraging the connections and entities captured during graph construction.
Example query:
python
query_engine = index.as_query_engine(include_text=True)
response = query_engine.query("Who did Charles Robert Darwin collaborate with?")
print(str(response))Query: "Who did Charles Robert Darwin collaborate with?"Response: The system identifies Alfred Russel Wallace as a collaborator.
This allows even non-technical users to extract insights easily using natural language.

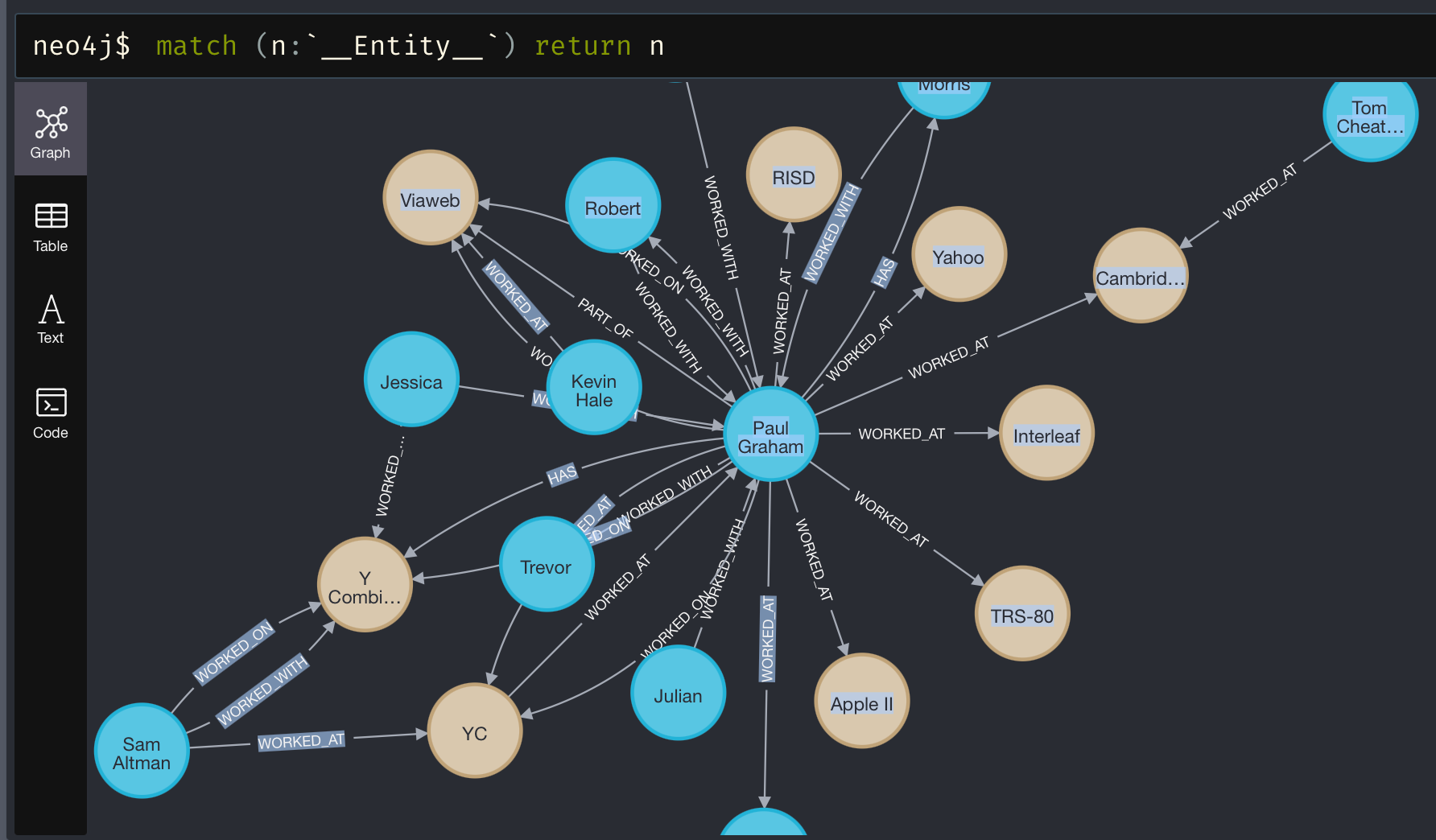
Visualizing Your Knowledge Graph
Use Memgraph Lab to explore your graph visually. You’ll see entities like "Charles Darwin" and "Alfred Russel Wallace," along with their relationships. This helps in understanding how data points connect, making your insights more actionable.
Read more: Memgraph Lab 101: Simplify Graph Data Exploration with Visualization and Querying
Transform Raw Data Into Actionable Knowledge
With LlamaIndex and Memgraph, you can bridge unstructured data and advanced analytics.
This integration offers:
- Effortless data transformation - build knowledge graphs from raw text.
- Intuitive querying - extract insights in natural language without technical barriers.
- Scalable insights - use Memgraph’s property graph for various advanced applications, including GenAI.
Next Steps
Now that you successfully built your knowledge graph, it’s time to unlock the full potential with Memgraph’s algorithms to further analyze your data. Dive into algorithms such as PageRank, community detection and Leiden to take your graph analysis to the next level.