Retrieval-augmented generation (RAG) is here to stay, and for good reason. It’s a powerful framework that blends advanced language models with targeted information retrieval techniques, enabling quicker access to relevant data and producing more accurate, context-aware responses. While RAG applications often focus on unstructured data, I’m a big fan of integrating structured data into the mix, a vital yet frequently overlooked approach. One of my favorite ways to do this is by leveraging graph databases like Neo4j.
Often, the go-to approach for retrieving data from a graph is text2cypher, where natural language queries are automatically converted into Cypher statements to query the graph database. This technique relies on a language model (or rule-based system) that interprets user queries, infers their underlying intent, and translates them into valid Cypher queries, enabling RAG applications to retrieve the relevant information from the knowledge graph and produce accurate answers.

Text2cypher offers remarkable flexibility because it allows users to formulate questions in natural language without having to know the underlying graph schema or Cypher syntax. However, due to the nuances of language interpretation and the need for precise schema-specific details, its accuracy can still be lacking as shown in this text2cypher article.
The most important results of the benchmark are shown in the following visualization.

From a high-level perspective, the benchmark compares three groups of models:
- Fine-tuned models for text2cypher tasks
- Open foundational models
- Closed foundational models
The benchmark evaluates their performance on generating correct Cypher queries using two metrics: GoogleBLEU (top chart) and ExactMatch (bottom chart).
The GoogleBLEU metric measures the degree of overlap (in terms of n-grams) between the generated query and a reference query. Higher scores generally indicate closer alignment to the reference, but they do not necessarily guarantee that the query will run correctly in a database context.
ExactMatch, on the other hand, is an execution-based metric. It indicates the percentage of generated queries that exactly match the correct query text, implying they produce the same results when executed. This makes ExactMatch a stricter measure of correctness and more directly tied to the actual utility of the query in a real-world setting.
Despite some promising results with fine-tuning, the overall accuracy levels illustrate that text2cypher remains an evolving technology. Some models still struggle to generate fully correct queries in every case, underscoring the need for further improvement in this area.
In this post, we’ll experiment with LlamaIndex Workflows to implement more agentic strategies for text2cypher. Instead of relying on a single-shot query generation, which is typically how most benchmarks are run, we’ll try a multi-step approach that allows for retries or alternative query formulations. By incorporating these extra steps and fallback options, we’re aiming to boost overall accuracy and reduce the instances of flawed Cypher generation.
The code is available on GitHub. We also have a hosted version of the application available here. Thanks to Anej Gorkic for contributing to the application and helping with debugging :)

LlamaIndex Workflows
LlamaIndex Workflows are a practical way to organize multi-step AI processes by connecting different operations through an event-driven system. They help break down complex tasks into smaller, manageable pieces that can communicate with each other in a structured way. Each step in a workflow handles specific events and produces new ones, creating a chain of operations that can accomplish tasks like document processing, question answering, or content generation. The system handles the coordination between steps automatically, making it easier to build and maintain complex AI applications.
Naive text2cypher flow
The naive text2cypher architecture is a streamlined approach to converting natural language questions into Cypher queries for Neo4j graph databases. It operates through a three-stage workflow: first, it generates a Cypher query from the input question using few-shot learning with similar examples stored in a vector database. The system then executes the generated Cypher query against the graph database. Finally, it processes the database results through a language model to generate a natural language response that directly answers the original question. This architecture maintains a simple yet effective pipeline, leveraging vector similarity search for example fewshot retrieval and LLM for both Cypher query generation and response formatting.
Here is the visualized naive text2cypher workflow.

It is worth noting that most Neo4j schema generation methods struggle with multi-labeled nodes. This issue arises not only due to added complexity but also because of the combinatorial explosion of labels, which can overwhelm the prompt. To mitigate this, we exclude the Actor and Director labels in the schema generation process.
python
schema = graph_store.get_schema_str(exclude_types=["Actor", "Director"]) The pipeline starts with the generate_cypher step.
python
@step
async def generate_cypher(self, ctx: Context, ev: StartEvent) -> ExecuteCypherEvent:
question = ev.input
# Cypher query generation using an LLM
cypher_query = await generate_cypher_step(
self.llm, question, self.few_shot_retriever
)
# Streaming event information to the web UI.
ctx.write_event_to_stream(
SseEvent(
label="Cypher generation",
message=f"Generated Cypher: {cypher_query}",
)
)
# Return for the next step
return ExecuteCypherEvent(question=question, cypher=cypher_query)The generate_cypher step takes a natural language question and transforms it into a Cypher query by utilizing a language model and retrieving similar examples from a vector store. The step also streams the generated Cypher query back to the user interface in real-time, providing immediate feedback on the query generation process. You can inspect the whole code and prompts here.
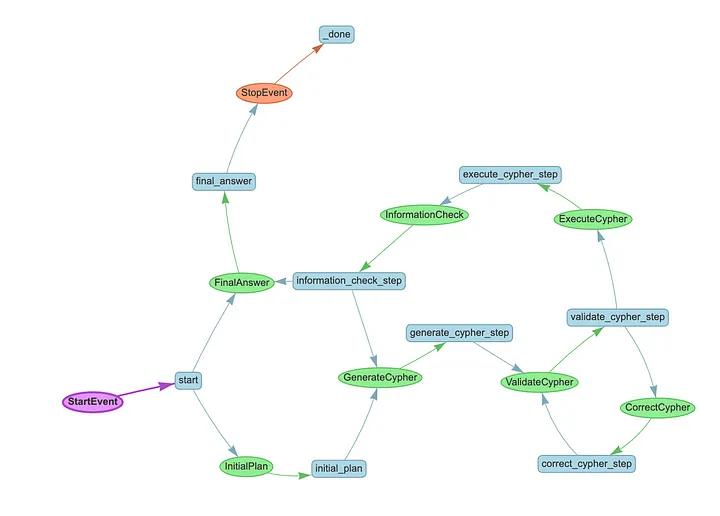
Naive text2cypher with retry flow
This enhanced version of text2cypher with retry builds upon the original architecture by adding a self-correction mechanism. When a generated Cypher query fails to execute, instead of failing outright, the system attempts to fix the query by feeding the error information back to the language model in the CorrectCypherEvent step. This makes the system more resilient and capable of handling initial mistakes, similar to how a human might revise their approach after receiving error feedback.
Here is the visualized naive text2cypher with retry workflow.

Let’s take a look at the ExecuteCypherEvent .
python
@step
async def execute_query(
self, ctx: Context, ev: ExecuteCypherEvent
) -> SummarizeEvent | CorrectCypherEvent:
# Get global var
retries = await ctx.get("retries")
try:
database_output = str(graph_store.structured_query(ev.cypher))
except Exception as e:
database_output = str(e)
# Retry
if retries < self.max_retries:
await ctx.set("retries", retries + 1)
return CorrectCypherEvent(
question=ev.question, cypher=ev.cypher, error=database_output
)
return SummarizeEvent(
question=ev.question, cypher=ev.cypher, context=database_output
)The execute function first attempts to run the query, and if successful, passes the results forward for summarization. However, if something goes wrong, it doesn’t give up immediately — instead, it checks if it has any retry attempts left and, if so, sends the query back for correction along with information about what went wrong. This creates a more forgiving system that can learn from its mistakes, much like how we might revise our approach after receiving feedback. You can inspect the whole code and prompts here.
Naive text2cypher with retry and evaluation flow
Building on the naive text2cypher with retry flow, this enhanced version adds an evaluation phase that checks if the query results are sufficient to answer the user’s question. If the results are deemed inadequate, the system sends the query back for correction with information on how to improve it. If the results are acceptable, the flow proceeds to the final summarization step. This extra layer of validation further bolsters the resilience of the pipeline, ensuring that the user ultimately receives the most accurate and complete answer possible.

The additional evaluation step is implemented in the following manner:
python
@step
async def evaluate_context(
self, ctx: Context, ev: EvaluateEvent
) -> SummarizeEvent | CorrectCypherEvent:
# Get global var
retries = await ctx.get("retries")
evaluation = await evaluate_database_output_step(
self.llm, ev.question, ev.cypher, ev.context
)
if retries < self.max_retries and not evaluation == "Ok":
await ctx.set("retries", retries + 1)
return CorrectCypherEvent(
question=ev.question, cypher=ev.cypher, error=evaluation
)
return SummarizeEvent(
question=ev.question, cypher=ev.cypher, context=ev.context
) The function evaluate_check is a simple check that determines whether the query results adequately address the user’s question. If the evaluation indicates the results are insufficient and there are retry attempts remaining, it returns a CorrectCypherEvent so the query can be refined. Otherwise, it proceeds with a SummarizeEvent ,indicating that the results are suitable for final summarization.
I later realized it would be an excellent idea to capture instances where the flow successfully self-healed by correcting invalid Cypher statements. These examples could then be leveraged as dynamic few-shot prompts for future Cypher generation. This approach would enable the agent to not only self-heal but also continuously self-learn and improve over time. The example code to store these fewshot examples can be found here and is implemented currently for this flow only (as it gives the best self-healing accuracy).
python
@step
async def summarize_answer(self, ctx: Context, ev: SummarizeEvent) -> StopEvent:
retries = await ctx.get("retries")
# If retry was successful:
if retries > 0 and check_ok(ev.evaluation):
# print(f"Learned new example: {ev.question}, {ev.cypher}")
# Store success retries to be used as fewshots!
store_fewshot_example(ev.question, ev.cypher, self.llm.model)Iterative planner flow
The final flow is the most complex, and coincidentally, the one I ambitiously designed first. I’ve kept it in the code so you can learn from my exploration.
The iterative planner flow introduces a more sophisticated approach by implementing an iterative planning system. Instead of directly generating a Cypher query, it first creates a plan of sub-queries, validates each subquery Cypher statement before execution, and includes an information checking mechanism that can modify the plan if the initial results are insufficient. The system can make up to three iterations of information gathering, each time refining its approach based on previous results. This creates a more thorough question-answering system that can handle complex queries by breaking them down into manageable steps and validating the information at each stage.
Here is the visualized iterative planner workflow.

Let’s examine the query planner prompt. I was quite ambitious when I began. I expected the LLMs to produce the following response.
python
class SubqueriesOutput(BaseModel):
"""Defines the output format for transforming a question into parallel-optimized retrieval steps."""
plan: List[List[str]] = Field(
description=(
"""A list of query groups where:
- Each group (inner list) contains queries that can be executed in parallel
- Groups are ordered by dependency (earlier groups must be executed before later ones)
- Each query must be a specific information retrieval request
- Split into multiple steps only if intermediate results return ≤25 values
- No reasoning or comparison tasks, only data fetching queries"""
)
)The output represents a structured plan for transforming a complex question into sequential and parallel query steps. Each step consists of a group of queries that can be executed in parallel, with later steps depending on the results of earlier ones. Queries are strictly for information retrieval, avoiding reasoning tasks, and are split into smaller steps if needed to manage result size. For example, the following plan begins by listing movies for two actors in parallel, followed by a step that identifies the highest-grossing movie from the results of the first step.
python
plan = [
# 2 steps in parallel
[
"List all movies made by Tom Hanks in the 2000s.",
"List all movies made by Tom Cruise in the 2000s.",
],
# Second step
["Find the highest profiting movie among winner of step 1"],
]This idea is undeniably cool. It’s a smart way to break down complex questions into smaller, actionable steps and even leverage parallelism to optimize retrieval. It sounds like the kind of strategy that could really speed things up. But, in practice, expecting LLMs to execute this reliably is a bit ambitious. Parallelism, while efficient in theory, introduces a lot of complexity. Dependencies, intermediate results, and maintaining logical consistency between parallel steps can easily trip up even advanced models. Sequential execution, though less glamorous, is more reliable for now and significantly reduces the cognitive overhead on the model.
Additionally, LLMs often struggle with following structured tool outputs like lists of lists, especially when reasoning about dependencies between steps. Here, I’m curious to see how much prompting alone (without tool outputs) can improve the model’s performance on these tasks
The code for the iterative planning flow is available here.
Benchmarking
Creating a benchmark dataset for evaluating text2ypher agents in the LlamaIndex workflow architecture feels like an exciting step forward.
We sought an alternative to traditional one-shot Cypher execution metrics, such as ExactMatch mentioned in the beginning, which often fall short in capturing the full potential of workflows like iterative planning. In these workflows, multiple steps are employed to refine queries and retrieve relevant information, making single-step execution metrics inadequate.
That’s why we chose to use answer_relevancy from RAGAS — it feels more aligned with what we want to measure. Here, we use an LLM to generate the answer, and then use LLM as a judge to compare it with ground truth. We’ve prepared a custom dataset of about 50 samples, carefully designed to avoid generating overwhelming outputs, meaning database results that are excessively large or detailed. Such outputs can make it difficult for an LLM judge to evaluate relevance effectively, so keeping results short ensures a fair and focused comparison of single- and multi-step workflows.
Here are the results.

Sonnet 3.5, Deepsek-v3, and GPT-4o emerge as the top three models in terms of answer relevancy, each scoring above 0.80. The NaiveText2CypherRetryCheckFlow tends to produce the highest relevancy overall, while the IterativePlanningFlow consistently ranks lower (dropping as low as 0.163).
Although o1 model is fairly accurate, it probably isn’t at the top due to multiple timeouts (set at 90 seconds). Deepsek-v3 stands out as especially promising, given its strong scores paired with relatively low latency. Overall, these results underscore the importance not just of raw accuracy, but also of stability and speed in practical deployment scenarios.
Here’s another table where uplift between flows can be easily examined.

Sonnet 3.5 rises steadily from a 0.596 score in NaiveText2CypherFlow to 0.616 in NaiveText2CypherRetryFlow, then makes a bigger leap to 0.843 in NaiveText2CypherRetryCheckFlow. GPT-4o shows a similar pattern overall, moving from 0.622 in NaiveText2CypherFlow down slightly to 0.603 in NaiveText2CypherRetryFlow, but then climbing significantly to 0.837 in NaiveText2CypherRetryCheckFlow. These improvements suggest that adding both a retry mechanism and a final verification step markedly boosts answer relevancy.
The benchmark code can be found here.
Please note that benchmark results may vary by at least 5%, meaning you might observe slightly different outcomes and top performers across different runs.
Learnings and going to production
This was a two-month project where I learned a lot along the way. One highlight of the project was achieving 84% relevancy in a test benchmark, which is a significant achievement. However, does that mean you will achieve 84% accuracy in production? Probably not.
Production environments bring their own set of challenges — real-world data is often noisier, more diverse, and less structured than benchmark datasets. Something we haven’t discussed yet, but you’ll see in practice with real applications and users, is the need for production-ready steps. This means not just focusing on achieving high accuracy in controlled benchmarks but ensuring the system is reliable, adaptable, and delivers consistent results in real-world conditions.
In these settings, you’d need to implement some kind of guardrails to stop unrelated questions from going through the text-to-Cypher pipeline.

We have an example guardrails implementation here. Beyond simply rerouting irrelevant questions, the initial guardrails step can also be used to help educate users by guiding them toward the types of questions they can ask, showcasing the available tools, and demonstrating how to use them effectively.
In the following example, we also highlight the importance of adding a process to map values from user input to the database. This step is crucial for ensuring that user-provided information aligns with the database schema, enabling accurate query execution and minimizing errors caused by mismatched or ambiguous data.

This is an example where a user asks for “Science Fiction” movies. The issue arises because the genre is stored as “Sci-Fi” in the database, causing the query to return no results.
What’s often overlooked is the presence of null values. In real-world data, null values are common and must be accounted for, especially when performing operations like sorting or similar tasks. Failing to handle them properly can lead to unexpected results or errors.

In this example, we get a random movie with Null value for their rating. To solve this problem, the query would need to have an additional clause WHERE m.imdbRating IS NOT NULL .
There are also cases where the missing information isn’t just a data issue but a schema limitation. For example, if we’re asking for Oscar-winning movies, but the schema doesn’t include any information about awards, the query simply cannot return the desired results.

Since LLMs are trained to please the user, the LLM still comes with something that fits the the schema but is invalid. I don’t know yet how to best handle such examples.
The last thing I want to mention is the query planning part. Remember before I used the following plan query to answer the question:
Who made more movies in the 2000s, Tom Hanks or Tom Cruise, and for the winner find their highest profiting movie.
The plan was:
python
plan = [
# 2 steps in parallel
[
"List all movies made by Tom Hanks in the 2000s.",
"List all movies made by Tom Cruise in the 2000s.",
],
# Second step
["Find the highest profiting movie among winner of step 1"],
]It looks impressive, but the reality is that Cypher is highly flexible, and GPT-4o can handle this in a single query.

I’d say parallelism is definitely overkill in this case. You can include a query planner if you’re dealing with complex question types that truly require it, but keep in mind that many multi-hop questions can be efficiently handled with a single Cypher statement.
This example highlights a different issue: the final answer is ambiguous because the LLM was only provided with limited information. Specifically, the winner, Tom Cruise, for the movie War of the Worlds. In this case, the reasoning already occurred within the database, so the LLM isn’t required to handle that logic. However, LLMs tend to operate this way by default, which underscores the importance of providing the LLM with the full context to ensure accurate and unambiguous responses.
Lastly, you will also have to think about how to handle questions that return a lot of results.

In our implementations, we enforce a hard limit of 100 records for results. While this helps manage data volume, it can still be excessive in some cases and may even mislead the LLM during its reasoning process.
Additionally, all the agents presented in this blog are not conversational. You’d likely need a question-rewriting step at the beginning to make them conversational, could be part of the guardrails step. And if you have a large graph schema that you cannot pass it whole in the prompt, you have to come up with a system that dynamically fetches relevant graph schema.
There are a lot of things to be aware of when going to production!
Summary
Agents can be incredibly useful, but it’s best to start simple and avoid diving into overly complex implementations from the beginning. Focus on establishing a solid benchmark to effectively evaluate and compare different architectures. When it comes to tool outputs, consider minimizing their use or sticking to the simplest tools possible, as many agents struggle to handle tool outputs effectively, often requiring manual parsing.
I would love to see some of the implementations you can come up with! Additionally, you can connect the project to your Neo4j database and start experimenting.