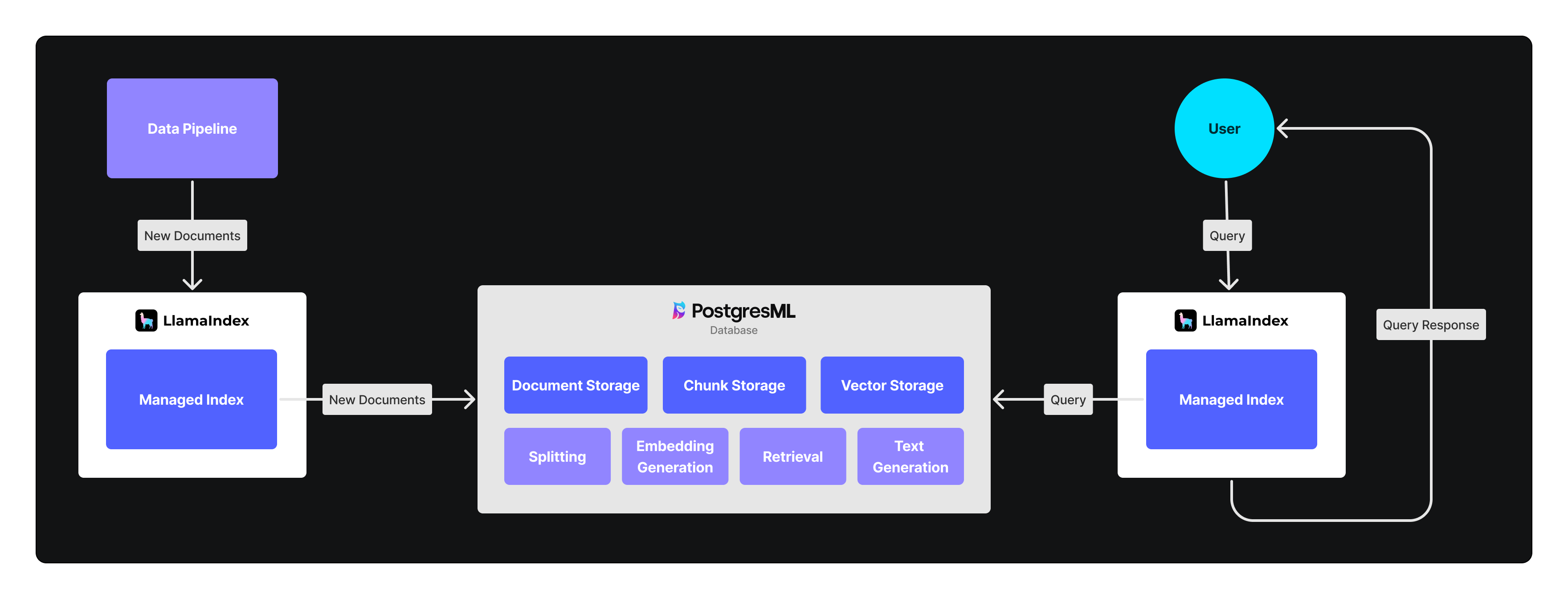
We’re happy to announce the recent integration of LlamaIndex with PostgresML — a comprehensive machine learning platform built on PostgreSQL. The PostgresML Managed Index allows LlamaIndex users to seamlessly manage document storage, splitting, embedding, and retrieval. By using PostgresML as the backend, users benefit from a streamlined and optimized process for Retrieval-Augmented Generation (RAG). This integration unifies embedding, vector search, and text generation into a single network call, resulting in faster, more reliable, and easier-to-manage RAG workflows.
The problem with typical RAG workflows
Typical Retrieval-Augmented Generation (RAG) workflows come with significant drawbacks, particularly for users.

Poor performance is a major issue, as these workflows involve multiple network calls to different services for embedding, vector storage, and text generation, leading to increased latency. Additionally, there are privacy concerns when sensitive data is sent to various LLM providers. These user-centric issues are compounded by other challenges:
- Increased dev time to master new technologies
- Complicated maintenance and scalability issues due to multiple points of failure
- Costly vendors required for multiple services
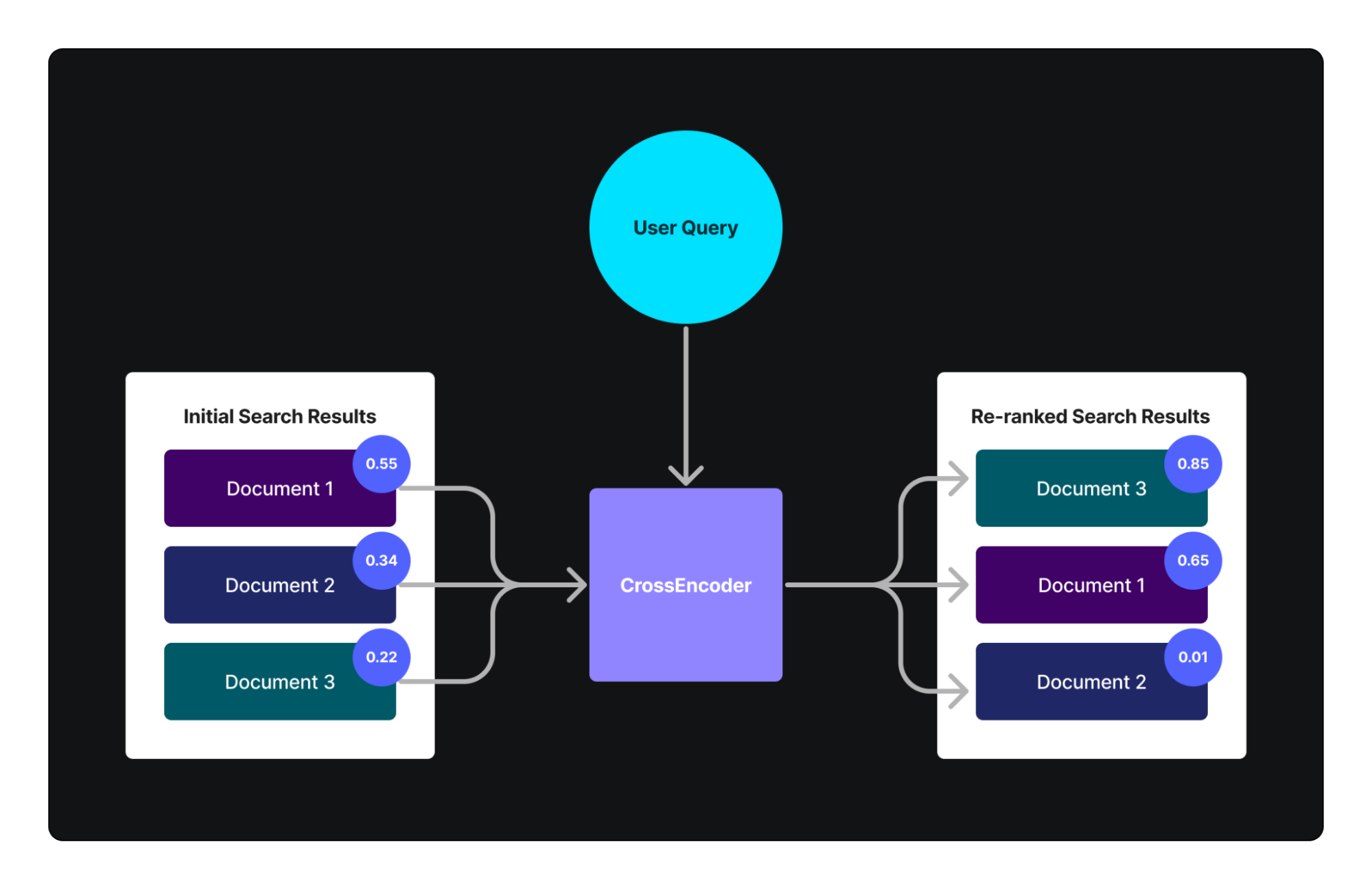
The diagram above illustrates the complexity, showing how each component interacts across different services — exacerbating these problems.
Solution
The PostgresML Managed Index offers a comprehensive solution to the challenges of typical RAG workflows.

By managing document storage, splitting, embedding generation, and retrieval all within a single system, PostgresML significantly reduces dev time, scaling costs, and overall spend when you eliminate the need for multiple point solutions. Most importantly, it enhances the user experience by consolidating embedding, vector search, and text generation into a single network call — resulting in improved performance and reduced latency. Additionally, the use of open-source models ensures transparency and flexibility, while operating within the database addresses privacy concerns and provides users with a secure and efficient RAG workflow.
About PostgresML
PostgresML [github || website || docs] allows users to take advantage of the fundamental relationship between data and models, by moving the models to your database rather than constantly moving data to the models. This in-database approach to AI architecture results in more scalable, reliable and efficient applications. On the PostgresML cloud, you can perform vector operations, create embeddings, and generate real-time outputs in one process, directly where your data resides.
Key highlights:
- Model Serving - GPU accelerated inference engine for interactive applications, with no additional networking latency or reliability costs
- Model Store - Access to open-source models including state of the art LLMs from Hugging Face, and track changes in performance between versions
- Model Training - Train models with your application data using more than 50 algorithms for regression, classification or clustering tasks; fine tune pre-trained models like Llama and BERT to improve performance
- Feature Store - Scalable access to model inputs, including vector, text, categorical, and numeric data: vector database, text search, knowledge graph and application data all in one low-latency system
- Python and JavaScript SDKs - SDK clients can perform advanced ML/AI tasks in a single SQL request without having to transfer additional data, models, hardware or dependencies to your application
- Serverless deployments - Enjoy instant autoscaling, so your applications can handle peak loads without overprovisioning
PostgresML has a range of capabilities. In the following sections, we’ll guide you through just one use case – RAG – and how to use the PostgresML Managed Index on LlamaIndex to build a better RAG app.
How it works in LlamaIndex
Let’s look at a simple question-answering example using the PostgresML Managed Index. For this example, we will be using Paul Graham’s essays.
Step 1: Get Your Database Connection String
If you haven’t already, create your PostgresML account. You’ll get $100 in free credits when you complete your profile.
Set the PGML_DATABASE_URL environment variable:
sh
export PGML_DATABASE_URL="{YOUR_CONNCECTION_STRING}"Alternatively, you can pass the pgml_database_url argument when creating the index.
Step 2: Create the PostgresML Managed Index
First install Llama_index and the PostgresML Managed Index component:
sh
pip install llama_index llama-index-indices-managed-postgresmlThen load in the data:
sh
mkdir data
curl -o data/paul_graham_essay.txt https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txtFinally create the PostgresML Managed Index:
python
from llama_index.core.readers import SimpleDirectoryReader
from llama_index.indices.managed.postgresml import PostgresMLIndex
documents = SimpleDirectoryReader("data").load_data()
index = PostgresMLIndex.from_documents(
documents, collection_name="llama-index-example"
)Note the collection_name is used to uniquely identify the index you are working with.
Here we are using the SimpleDirectoryReader to load in the documents and then we construct the PostgresMLIndex from those documents.
This workflow does not require document preprocessing. Instead, the documents are sent directly to PostgresML where they are stored, split, and embedded per the pipeline specification. For more information on pipelines see: https://postgresml.org/docs/api/client-sdk/pipelines Custom Pipelines can be passed into the PostgresML index at creation, but by default documents are split using the recursive_character splitter and embedded with intfloat/e5-small-v2 .
Step 3: Querying
Now that we have created our index we can use it for retrieval and querying:
python
retriever = index.as_retriever()
docs = retriever.retrieve("Was the author puzzled by the IBM 1401?")
for doc in docs:
print(doc)PostgreML does embedding and retrieval in a single network call. Compare this query against other common LlamaIndex embedding and vector storage configurations and you will notice a significant speed up.
Using the PostgresML Index as a query_engine is just as easy:
python
response = index.as_query_engine().query("Was the author puzzled by the IBM 1401?")
print(response)Once again, notice how fast the response was! The PostgresML Managed Index is doing embedding, retrieval, and augmented generation in one network call. The speed up becomes even more apparent when streaming:
python
query_engine = index.as_query_engine(streaming=True)
results = query_engine.query("Was the author puzzled by the IBM 1401?")
for text in results.response_gen:
print(text, end="", flush=True)Note that by default the query_engine uses meta-llama/Meta-Llama-3-8B-Instruct but this is completely configurable.
Key takeaways
The PostgresML Managed Index uniquely unifies embedding, vector search, and text generation into a single network call. LlamaIndex users can expect faster, more reliable, and easier-to-manage RAG workflows by using PostgresML as the backend.
To get started with PostgresML and LlamaIndex, you can follow the PostgresML intro guide to setup your account, and the examples above with your own data.