
Search and Reranking: Improving Result Relevance
Search systems typically employ two main methods: keyword and semantic. Keyword search matches exact query terms to indexed database content, while semantic search uses NLP and machine learning to understand query context and intent. Many effective systems combine both approaches for optimal results.
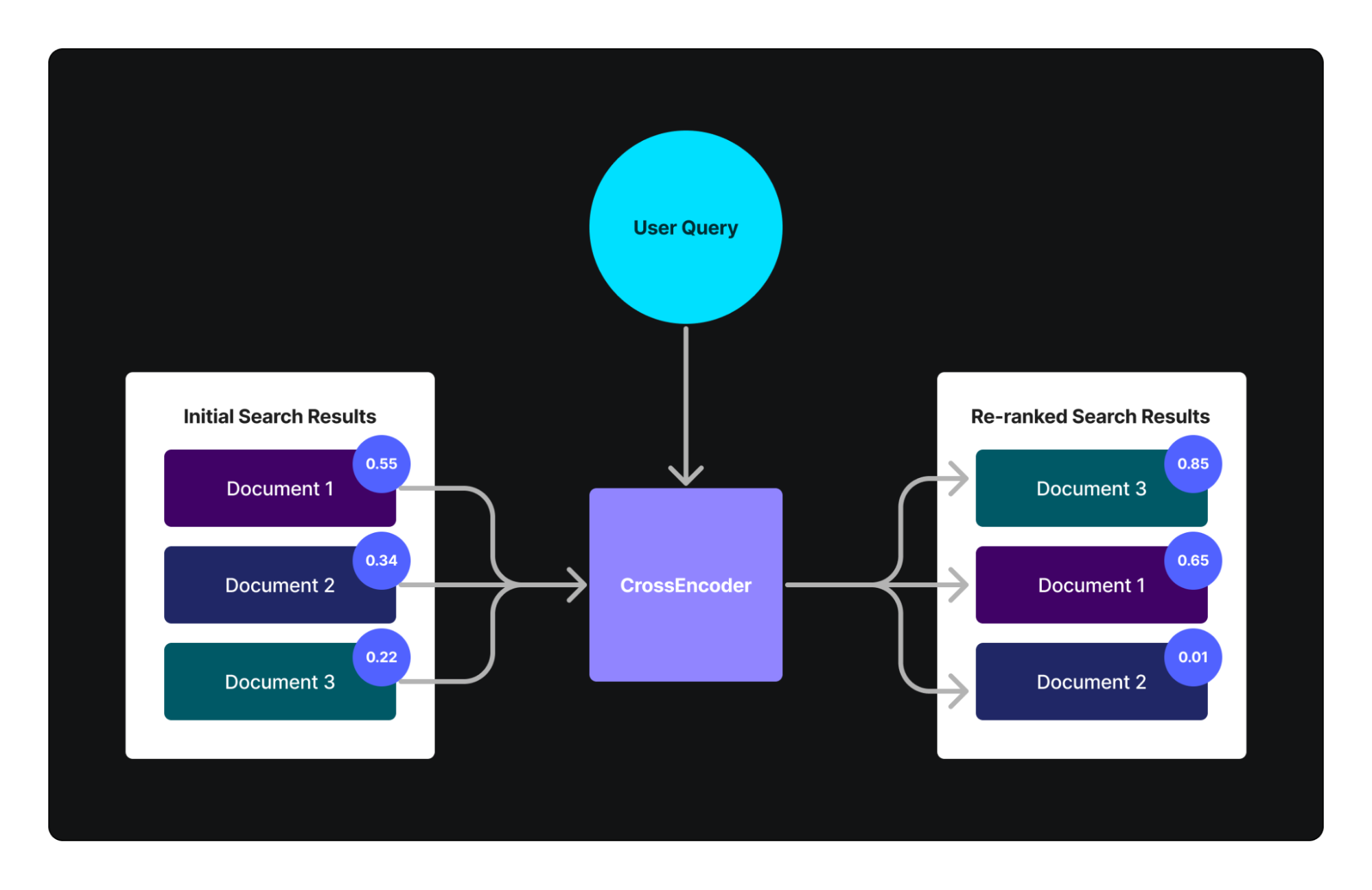
After initial retrieval, reranking can further improve result relevance. Traditional reranking relies on historical user interaction data, but this approach struggles with new content and requires substantial data to train effectively. An advanced alternative is using cross-encoders, which directly compare query-result pairs for similarity.
Cross-encoders directly compare two pieces of text and compute a similarity score. Unlike traditional semantic search methods, we cannot precompute embeddings for cross-encoders and reuse them later. Instead, we must run the cross-encoder for every pair of texts we want to compare, making this method computationally expensive and impractical for large-scale searches. However, it is highly effective for reranking a subset of our dataset because it excels at evaluating new, unseen data without the need for extensive user interaction data for fine-tuning.
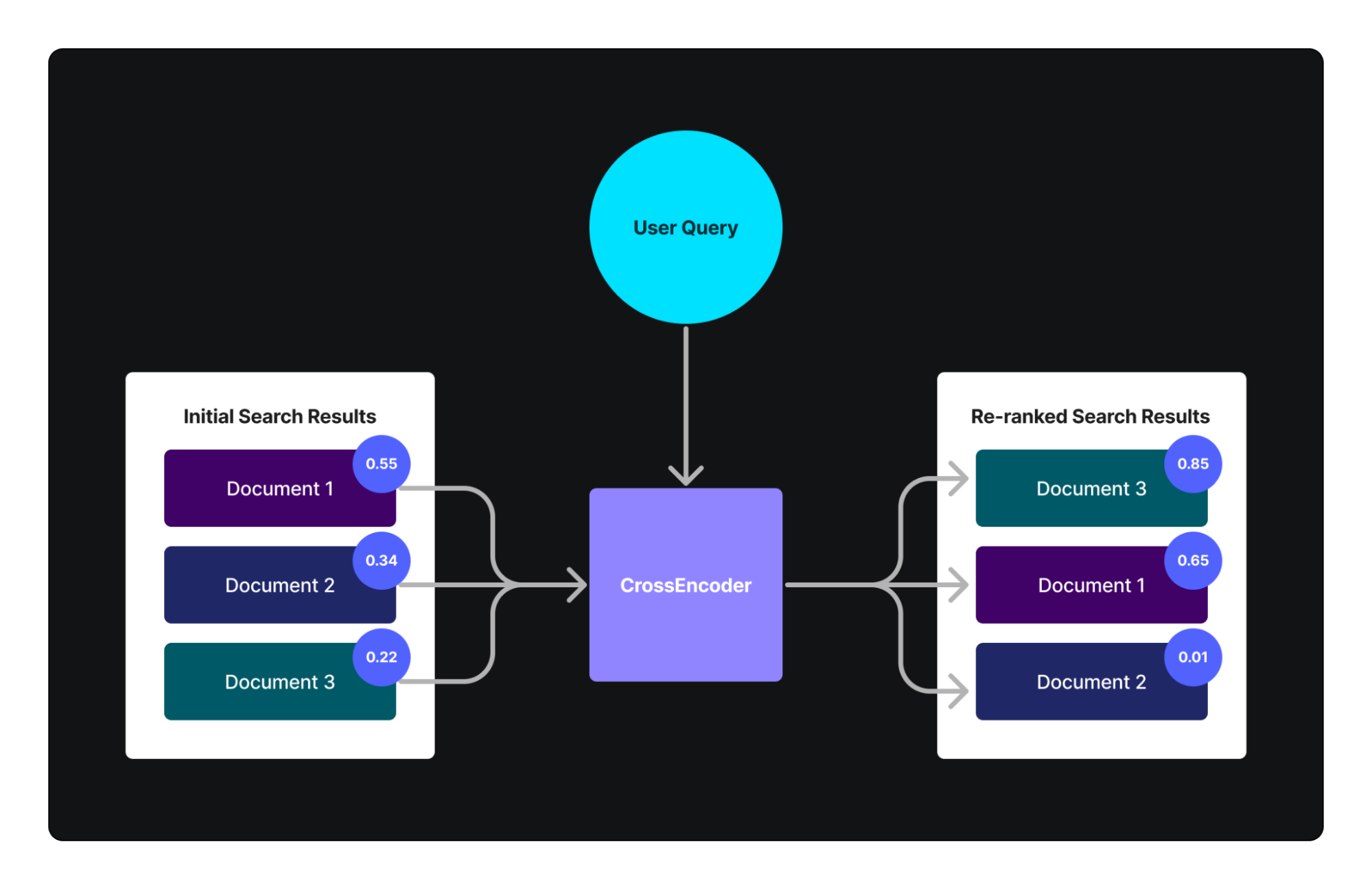
Cross-encoders complement and enhance traditional reranking systems by addressing their limitations in deep text analysis, particularly for novel or highly specific content. They do not rely on large datasets of user interactions for training (though such data can still be beneficial) and are adept at handling new and previously unseen data. This makes cross-encoders an excellent choice for enhancing the relevance of search results in a reranking context.
Implementing Reranking
We are going to implement a simple reranking example using LlamaIndex and the PostgresML managed index. For more info on the PostgresML managed index. Check out our announcement with LlamaIndex: Simplify your RAG application architecture with LlamaIndex + PostgresML.
Install the required dependencies to get started:
sh
pip install llama_index llama-index-indices-managed-postgresmlWe will be using the Paul Graham dataset which can be downloaded with curl:
sh
mkdir data
curl -o data/paul_graham_essay.txt https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txtThe PostgresML Managed Index will handle storing, splitting, embedding, and querying our documents. All we need is a database connection string. If you haven’t already, create your PostgresML account. You’ll get $100 in free credits when you complete your profile.
Set the PGML_DATABASE_URL environment variable:
sh
export PGML_DATABASE_URL="{YOUR_CONNCECTION_STRING}"Let’s create our index:
python
from llama_index.core.readers import SimpleDirectoryReader
from llama_index.indices.managed.postgresml import PostgresMLIndex
documents = SimpleDirectoryReader("data").load_data()
index = PostgresMLIndex.from_documents(
documents, collection_name="llama-index-rerank-example"
)Note the collection_name is used to uniquely identify the index you are working with.
Here we are using the SimpleDirectoryReader to load in the documents and then we construct the PostgresMLIndex from those documents.
This workflow does not require document preprocessing. Instead, the documents are sent directly to PostgresML where they are stored, split, and embedded per the pipeline specification. This is a unique quality of using the PostgresML managed index.
Now let’s search! We can perform semantic search and get the top 2 results by creating a retriever from our index.
python
retriever = index.as_retriever(limit=2)
docs = retriever.retrieve("What did the author do as a child?")
for doc in docs:
print("---------")
print(f"Id: {doc.id_}")
print(f"Score: {doc.score}")
print(f"Text: {doc.text}")Doing this we get:
text
---------
Id: de01b7e1-95f8-4aa0-b4ec-45ef64816e0e
Score: 0.7793415653313153
Text: Wow, I thought, there's an audience. If I write something and put it on the web, anyone can read it. That may seem obvious now, but it was surprising then. In the print era there was a narrow channel to readers, guarded by fierce monsters known as editors. The only way to get an audience for anything you wrote was to get it published as a book, or in a newspaper or magazine. Now anyone could publish anything.
This had been possible in principle since 1993, but not many people had realized it yet. I had been intimately involved with building the infrastructure of the web for most of that time, and a writer as well, and it had taken me 8 years to realize it. Even then it took me several years to understand the implications. It meant there would be a whole new generation of essays. [11]
In the print era, the channel for publishing essays had been vanishingly small. Except for a few officially anointed thinkers who went to the right parties in New York, the only people allowed to publish essays were specialists writing about their specialties. There were so many essays that had never been written, because there had been no way to publish them. Now they could be, and I was going to write them. [12]
I've worked on several different things, but to the extent there was a turning point where I figured out what to work on, it was when I started publishing essays online. From then on I knew that whatever else I did, I'd always write essays too.
---------
Id: de01b7e1-95f8-4aa0-b4ec-45ef64816e0e
Score: 0.7770352826735559
Text: Asterix comics begin by zooming in on a tiny corner of Roman Gaul that turns out not to be controlled by the Romans. You can do something similar on a map of New York City: if you zoom in on the Upper East Side, there's a tiny corner that's not rich, or at least wasn't in 1993. It's called Yorkville, and that was my new home. Now I was a New York artist — in the strictly technical sense of making paintings and living in New York.
I was nervous about money, because I could sense that Interleaf was on the way down. Freelance Lisp hacking work was very rare, and I didn't want to have to program in another language, which in those days would have meant C++ if I was lucky. So with my unerring nose for financial opportunity, I decided to write another book on Lisp. This would be a popular book, the sort of book that could be used as a textbook. I imagined myself living frugally off the royalties and spending all my time painting. (The painting on the cover of this book, ANSI Common Lisp, is one that I painted around this time.)
The best thing about New York for me was the presence of Idelle and Julian Weber. Idelle Weber was a painter, one of the early photorealists, and I'd taken her painting class at Harvard. I've never known a teacher more beloved by her students. Large numbers of former students kept in touch with her, including me. After I moved to New York I became her de facto studio assistant.These aren’t bad results, but they aren’t perfect. Let’s try reranking with a cross-encoder.
python
retriever = index.as_retriever(
limit=2,
rerank={
"model": "mixedbread-ai/mxbai-rerank-base-v1",
"num_documents_to_rerank": 100
}
)
docs = retriever.retrieve("What did the author do as a child?")
for doc in docs:
print("---------")
print(f"Id: {doc.id_}")
print(f"Score: {doc.score}")
print(f"Text: {doc.text}")Here, we configure our retriever to return the top two documents, but this time, we add a rerank parameter to use the mixedbread-ai/mxbai-rerank-base-v1 model. This means our initial semantic search will return 100 results, which will then be reranked by the mixedbread-ai/mxbai-rerank-base-v1 model, and only the top two results will be presented.
Running this outputs:
text
Id: de01b7e1-95f8-4aa0-b4ec-45ef64816e0e
Score: 0.17803585529327393
Text: What I Worked On
February 2021
Before college the two main things I worked on, outside of school, were writing and programming. I didn't write essays. I wrote what beginning writers were supposed to write then, and probably still are: short stories. My stories were awful. They had hardly any plot, just characters with strong feelings, which I imagined made them deep.
The first programs I tried writing were on the IBM 1401 that our school district used for what was then called "data processing." This was in 9th grade, so I was 13 or 14. The school district's 1401 happened to be in the basement of our junior high school, and my friend Rich Draves and I got permission to use it. It was like a mini Bond villain's lair down there, with all these alien-looking machines — CPU, disk drives, printer, card reader — sitting up on a raised floor under bright fluorescent lights.
The language we used was an early version of Fortran. You had to type programs on punch cards, then stack them in the card reader and press a button to load the program into memory and run it. The result would ordinarily be to print something on the spectacularly loud printer.
---------
Id: de01b7e1-95f8-4aa0-b4ec-45ef64816e0e
Score: 0.1057136133313179
Text: I wanted not just to build things, but to build things that would last.
In this dissatisfied state I went in 1988 to visit Rich Draves at CMU, where he was in grad school. One day I went to visit the Carnegie Institute, where I'd spent a lot of time as a kid. While looking at a painting there I realized something that might seem obvious, but was a big surprise to me. There, right on the wall, was something you could make that would last. Paintings didn't become obsolete. Some of the best ones were hundreds of years old.
And moreover this was something you could make a living doing. Not as easily as you could by writing software, of course, but I thought if you were really industrious and lived really cheaply, it had to be possible to make enough to survive. And as an artist you could be truly independent. You wouldn't have a boss, or even need to get research funding.
I had always liked looking at paintings. Could I make them? I had no idea. I'd never imagined it was even possible. I knew intellectually that people made art — that it didn't just appear spontaneously — but it was as if the people who made it were a different species. They either lived long ago or were mysterious geniuses doing strange things in profiles in Life magazine. The idea of actually being able to make art, to put that verb before that noun, seemed almost miraculous.These are much better results! We can see that the top document has the answer to the user’s question. Notice that we did not have to specify a third party API to use for reranking. Once again, PostgresML handles the reranking using cross-encoders in the database.
We can use re-ranking directly in RAG:
python
query_engine = index.as_query_engine(
streaming=True,
vector_search_limit=2,
vector_search_rerank={
"model": "mixedbread-ai/mxbai-rerank-base-v1",
"num_documents_to_rerank": 100,
},
)
results = query_engine.query("What did the author do as a child?")
for text in results.response_gen:
print(text, end="", flush=True)Running this outputs:
text
Based on the context information, as a child, the author worked on writing (writing short stories) and programming (on the IBM 1401 using Fortran) outside of school.That is the exact answer we wanted!
Reranking Leads to Better Results
Search can be complicated. Reranking with cross-encoders improves search by comparing text pairs and effectively handling new data. Implementing reranking with LlamaIndex and PostgresML improves search results, providing more precise answers in retrieval-augmented generation applications.
To get started with PostgresML and LlamaIndex, you can follow the PostgresML intro guide to setup your account, and use the examples above with your own data.

