This is a guest post from one of the winners of our recent hackathon.
The promise of agent architectures is that AI can become more capable not by relying on clever prompting, fine-tuning, and scaling of individual LLMs to solve a problem in one autoregressive gulp, but by coordinating simpler tasks that collectively marshal resources and incrementally work toward solutions. The recent Agentic RAG-A-Thon offered incentives, resources, and community for participants to build prototypes and demos doing exactly that.
Problem: RAG for Code Repositories
Our team's problem scenario starts with a real-world application of RAG in technical support. Users have questions, support engineers respond with answers. Sometimes, the answer is based on documentation that may be more or less accessible to average users. For example, manufacturers of semiconductors host community forums listing thousands of how-to and troubleshooting questions. Many questions and answers draw from the hundreds of git repos a company might maintain containing APIs, example code, firmware, and documentation. AI should help the support engineers find the right documents, and synthesize useful answers for customers' problems.

Retrieval Augmented Generation (RAG) can work well when context chunks are derived from well-structured segments of natural language source documents. But some knowledge sources, such as code repositories, tend to produce chunks that lack context and meaning necessary for effective indexing, and that lack significance toward a useful question+context prompt for LLM response synthesis.
One solution operates at knowledge source preparation time, to build smarter chunks. For example, along with function-level chunks identified in software files, include imports and class membership annotations. Or include a narrative summary for each chunk. Already, IDEs such as VS Code and Cursor reach beyond code completion by bridging software expressions with narrative explanations of purpose and function.
Naturally, up-front knowledge preparation for RAG is general-purpose---it cannot be tuned to surfacing knowledge for any particular user question.

Proposal: Revisit the source docs
An alternative approach more closely resembles what a human expert would do. Over multiple rounds of iteration, they will search and follow leads in the documentation until a satisfactory answer is found or pieced together.
Our idea is to emulate this strategy by deploying an AI Agent at question-answering time. Instead of relying solely on chunks retrieved via index search and re-ranking, we propose for the agent to revisit the source documentation itself, to refine the context portion of the LLM prompt until it contains sufficient information to answer the user's question.
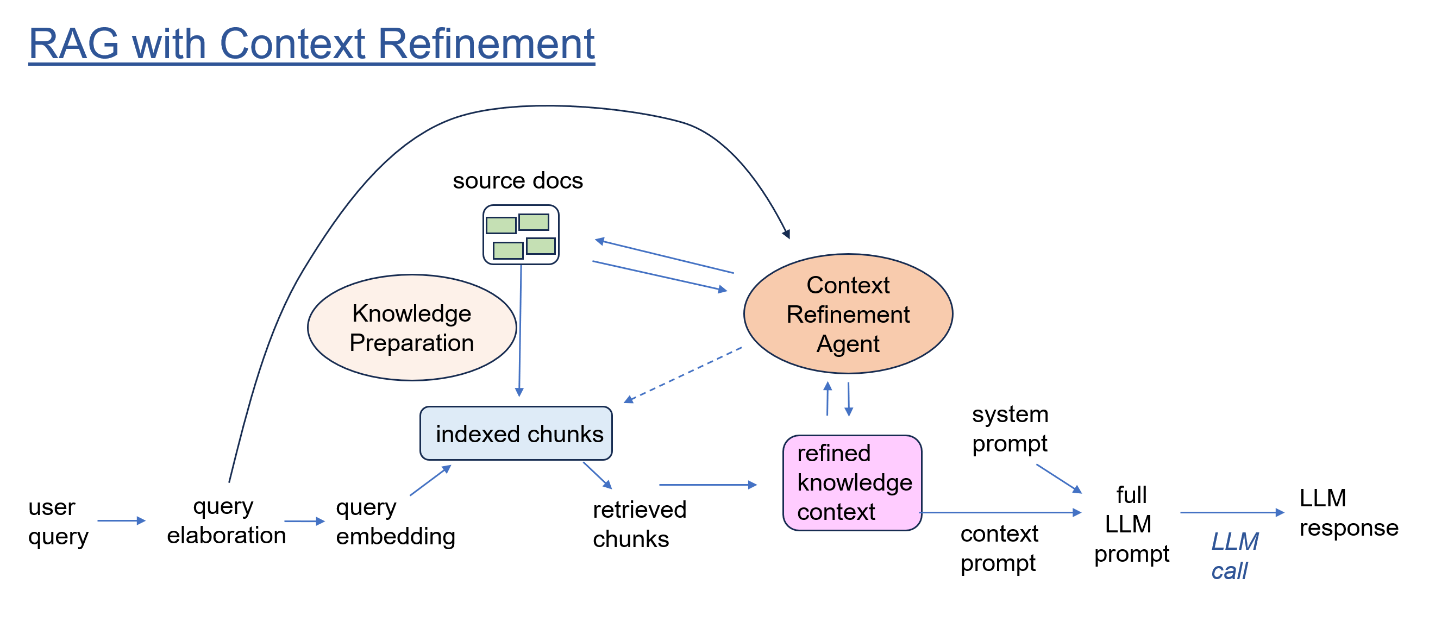
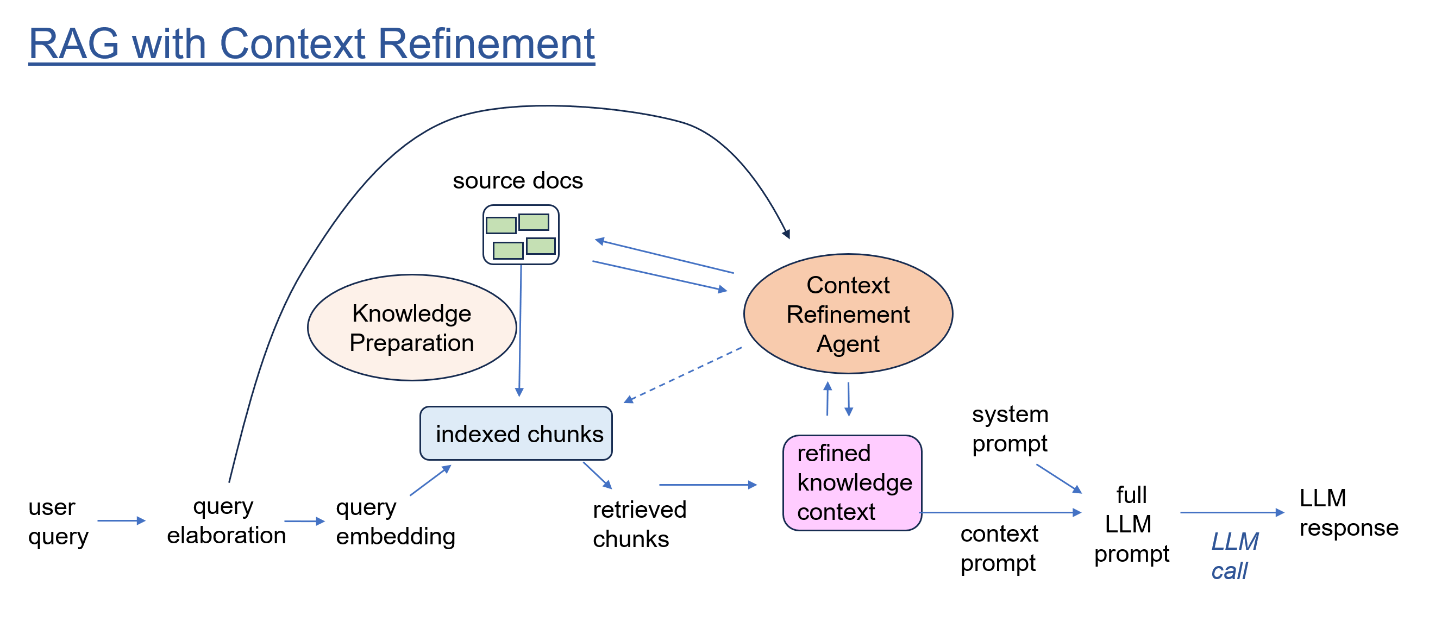
Our design centers around a scratchpad containing the question-specific context information. After refinement, this context is included in the LLM call that generates a final answer, along with the initial user question, plus instruction prompt.
The content of the scratchpad starts off with the initial set of retrieval chunks pulled from the RAG vector store.
But crucially, an Evaluator step decides whether the scratchpad context is sufficient to answer the question, or not. If, for example, the initial chunks are merely assorted snippets of code that appear to be relevant to the question, but offer no coherent explanation of how they fit together, then the Evaluator passes control to other steps within the agent.
The Context Refinement Agent includes an open-ended library of tools that can be applied to refine the scratchpad. Tools can include:
- Selection and filtering of useful repos versus distractors, based on chunk scores and voting.
- Application of summarization to files and directories.
- Inclusion of entire code files (subject to size), based on chunks matched to fragments.
- Removal of chunks deemed irrelevant to the question.
- Selection of explanatory documentation associated with functions, files, and repos.
- Following of links found to documentation located elsewhere on the company's site, or third party sites.
A Tool Selector step decides which tool to apply next. This decision may be a pre-determined sequence, a rule-like policy, or an open-ended judgement.

Learning from Classical AI
Students of Artificial Intelligence will recognize this architecture as a classic Production System. In AI parlance, "Production System" does not mean a "system ready for production deployment." Instead, a Production System establishes a collection of incremental computational steps that compete to modify the contents of a central "blackboard." Control flow is not pre-defined, but depends on the data. In contrast to traditional declarative programs, this approach affords asynchronous, distributed, and parallel modes of computation. The idea dates to Selfridge's 1959 "Pandemonium" architecture for feature matching in visual perception; other significant Production Systems include Soar, Act-R, and OpenCog.
Traditional Production Systems based in symbolic representations have fallen short of the spectacular results delivered by Large Language Models trained and run on deep neural networks. Among the challenges is weighing context in decisions about what productions to fire and how their outputs should modify the blackboard workspace.
LLMs offer several breakthrough capabilities that hold promise for an agent architecture organized around a cycle of evaluation, tool selection, and tool application:
- A large amount of loosely structured context can be brought to bear on decisions.
- Interface representations are human natural language and comprehensible artificial languages.
- Vector embeddings afford "fuzzy" pattern matching.
- Effective abstraction of concepts by LLMs negates the need for explicit programming of intricate logic rules.
Proof of Concept
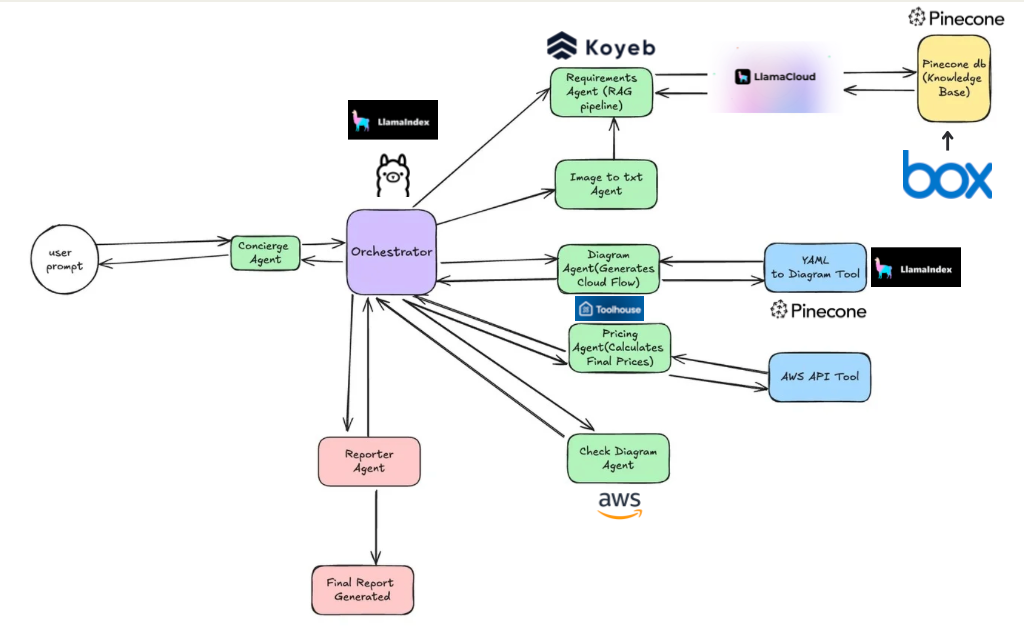
Over the Hack-A-Thon weekend, we built a minimal proof-of-concept RAG Context Refinement Agent. Sample questions were selected from the public Community Forum site of the semiconductor company, Infineon. We chose questions whose peer and expert answers included references to Infineon's public GitHub site. Then, we built and indexed knowledge chunks from these repos using the LlamaIndex and Pinecone tool chain. For baseline testing, we ran the questions against ChatGPT and standard RAG that used top-K retrievals as context.
The figure below shows how AI context refinement improves the response to a sample question over baseline RAG. The user's question is about sleep state of a microcontroller. Our Evaluator step asks an LLM to provide a numerical score assessing how well the scratchpad context answers the question. The initial retrieved chunks offer no helpful answer; they were scored as 0.3 by the Evaluator, which sent control to the Tool Selector. In this case, the relevant tool was one that identified high-scoring chunks from the same file, and fetched the entire file into the scratchpad. The evaluator rated the improved context 0.7. With this context refinement, information was retrieved that addresses HOST_WAKE, DEV_WAKE, and other aspects of the question.

We built the Context Refinement Agent in the LlamaIndex Workflow framework. In fact, we built the entire RAG question/response-generation pipeline in the event-driven Workflow framework. Custom Events of the developer's design trigger operational Steps in asynchronous, dataflow fashion. Workflow steps can be purely programmatic, or they can invoke LLM calls, or they can invite human interaction. We found this framework to be elegant and intuitive---although in Python it can be tricky to get the handoffs right between synchronous and asynchronous code.
The Workflow framework supports a global Context object that naturally maps onto our scratchpad, or blackboard. Within the Context Refinement Agent, context state consists of the user question and question elaborations, plus the current contents of source knowledge context to be supplied in the final LLM answer-generation call.
We found it drop dead easy to run our demo in a web browser using Reflex's tools for building a web GUI in Python.
Outlook: RAG Context Refinement
With a proof-of-concept and working implementation in hand (at least in prototype, outline form), this idea is a candidate for further refinement. A significant amount of development and testing with real-world question-against-repo cases will be required to solidify and improve it. Specifically, any degree of agentic autonomy is subject to unpredictable behavior so requires careful instrumentation, monitoring, and evaluation. For example, some tools might explore the open web to pull in relevant information such as references to third party libraries, but these sources must be constrained and vetted.
The Agentic RAG-A-Thon offered an exhilarating opportunity to exchange ideas with other developers, to learn about the growing array of tools and services, and to learn how Agentic RAG technology can meet real world problems. We are gratified to have received the Global 500 Award recognizing our efforts, and we congratulate all of the sponsors and participants for creating a fantastic event.
Eric Saund, Ph.D., is Chief AI Officer, ept.ai.
Tico Ballagas is VP Software Engineering, Penumbra
Mohit Shankar Velu is recently graduated from UMass Amherst and works at Prosimo.