Extracting structured data from unstructured documents is a core challenge across industries – from finance and healthcare to insurance and HR. Whether it's pulling financial metrics from SEC filings, extracting invoice details for expense management, or structuring candidate resumes for hiring, businesses spend countless hours manually processing documents.
We are excited to introduce LlamaExtract—a powerful, easy-to-use tool that allows users to extract structured data from unstructured documents with minimal effort. LlamaExtract is now in public beta, available through LlamaParse’s web UI and Python SDK.
Why Structured Data Extraction?
Unstructured data is everywhere: scanned PDFs, contracts, invoices, resumes, and more. Extracting meaningful insights from these documents typically requires tedious manual work, rule-based systems, or complex machine learning pipelines. However, these approaches often fall short when handling:
- Diverse Document Formats – PDFs, text files, scanned images, and documents that are very long (100+ pages).
- Complex Structures – Tables, multi-column layouts, and nested sections.
- Data Variability – Different formats for invoices, resumes, and financial reports.
- Scalability Challenges – Processing hundreds or thousands of documents efficiently.
LlamaExtract eliminates these pain points by providing a schema-based, AI-powered approach that simplifies extraction while ensuring high accuracy.
How LlamaExtract Works
LlamaExtract enables structured data extraction in three simple steps:
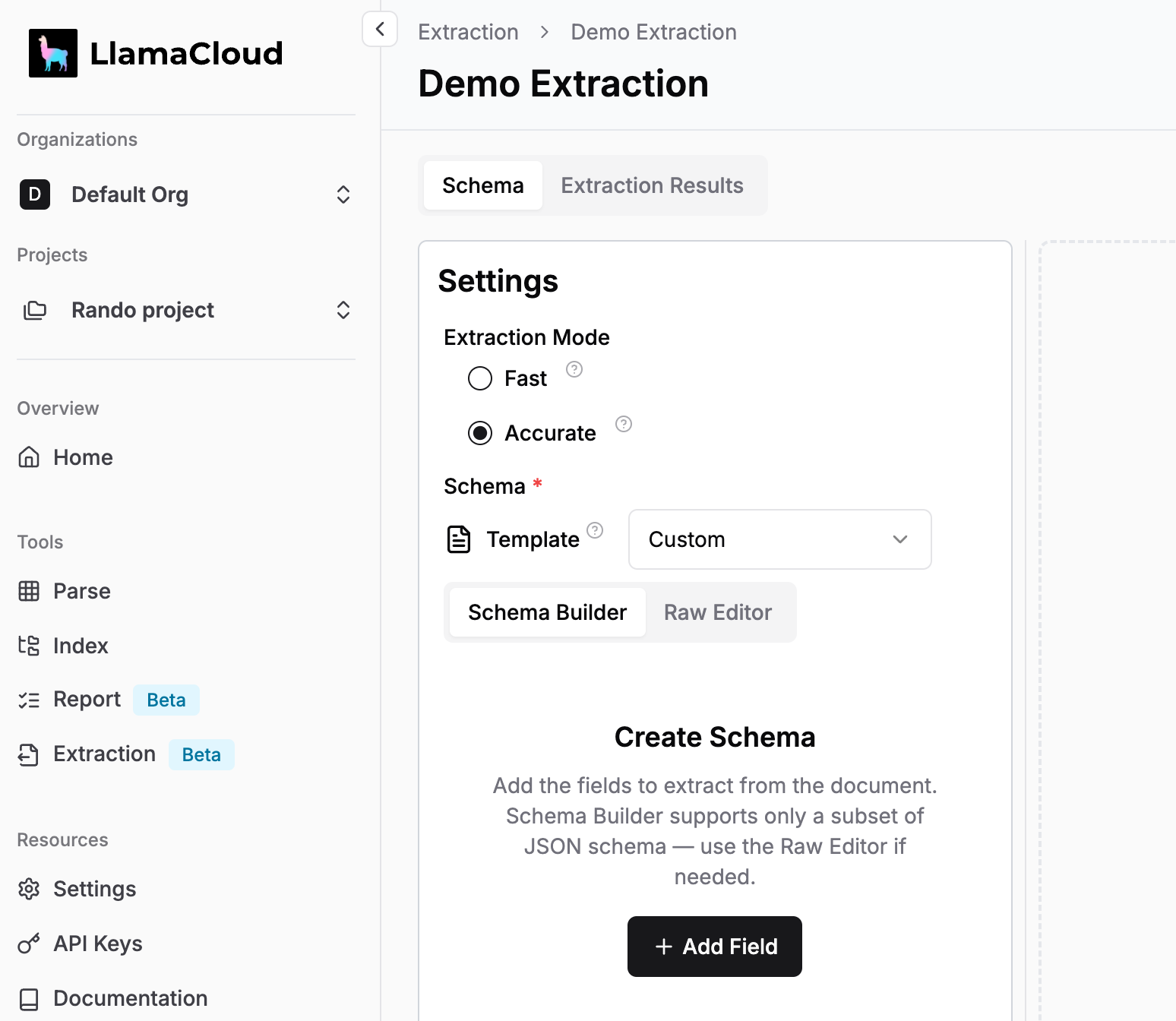
1. Schema Definition & Customization
- LlamaExtract allows users to define a schema (either in JSON or via a clickable UI).
- Users can modify and refine the schema as needed.

2. Automated Data Extraction
- Given a schema, LlamaExtract extracts structured data from documents and outputs it in JSON format.
- Supports well-typed data, ensuring accuracy and compliance with the defined schema.

3. Integration & Workflow Automation
- Integrate with the Python SDK for scalable batch processing.
Who Should Try LlamaExtract?
LlamaExtract is designed for developers and analysts who need reliable, structured data extraction from unstructured sources. Some key use cases include:
- Finance & Investment Teams – Extract financial data from SEC filings, investment reports, and earnings statements.
- Accounts Payable & Expense Management – Digitize invoices and pull structured details like invoice numbers, vendor names, and amounts.
- HR & Recruiting – Parse resumes, extracting key candidate details for ATS (Applicant Tracking Systems).
- Healthcare & Insurance – Process claims, provider enrollment documents, and medical records efficiently.
Why LlamaExtract Stands Out
LlamaExtract is built on LlamaParse, our industry-leading document parser, ensuring best-in-class data extraction capabilities. Here’s what makes it unique:
- Integrated Parsing – No need to manually handle OCR, scanned documents, or table parsing.
- Schema Flexibility – Define the schema and refine as needed.
- Scalability – Extract data from large documents (e.g. 10K filings) with ease.
- Well-typed data for downstream tasks: LlamaExtract guarantees that your data complies with the provided schema or provides helpful error messages when it doesn't.
Try LlamaExtract Today!
LlamaExtract is now available in public beta to all LlamaParse users! Start extracting structured data in just a few clicks by signing up at cloud.llamaindex.ai. You can request access.
For developers, check out our Python SDK and example notebooks to integrate LlamaExtract into your workflows:
Have feedback? Help us improve by sharing your thoughts on our GitHub repo.
This is just the beginning
LlamaExtract is being actively developed. Stay tuned for features like citations, verification and schema versioning. We can’t wait to see what you build with it!