Extracting structured information from lengthy documents is a common need we hear from customers. Whether you are analyzing SEC filings, legal contracts, research papers, or technical documentation, LlamaExtract can help you transform complex, long-form documents into structured, actionable data that can be used downstream as part of an automated process.
Why Extract Structured data from 10-Ks
In working with our financial services customers, we have come across several use cases where structured data extraction from 10Ks would be valuable. Some examples are
- Financial Analysis and Benchmarking: Structured data extraction enables analysts and investors to systematically evaluate a company's financial health by organizing key metrics such as revenue, operating income, and net income
- Risk Assessment and Management: By extracting and structuring information on risk factors disclosed in 10-K reports, organizations can identify and monitor potential risks more effectively
- Investment Decision-Making: Investors rely on structured data from 10-K reports to assess the viability and potential returns of investment opportunities. Organizing financial statements, management discussions, and market analyses into structured formats enables more accurate evaluations and comparisons, aiding in sound investment decisions.
Challenges of Extraction from 10-K/Q Filings
While extracting structured data from SEC 10-K/Q filings is high value, it exemplifies the challenges of long-form document extraction.
- These reports often exceed 100 pages and contain densely packed information across multiple sections with varying structures. Traditional extraction methods typically fail because they can't maintain context across distant sections of a document or struggle with extraction from tabular data.
- These documents have a loosely defined structure and the reported metrics and sections may differ based on the company's operations. We ideally want to capture fields that are common across different companies while still allowing for individual variation in reporting metrics and fields.
For reference, here is Nvidia’s 2024 10-K filing with the SEC. We will be using this as an example in this post. To follow along, you can clone the notebook from our examples folder. Let's see how LlamaExtract addresses the challenges of converting these documents into a structured well-typed format.
Building an Effective Extraction Schema
The foundation of successful extraction is a well-designed schema. A well-designed schema is one that captures your information of interest and generalizes to your target documents, i.e. documents have the relevant information to populate the fields in the schema, and likewise, the schema contains enough information to specify “how” to extract this data from the target documents.
For SEC filings, we create a comprehensive schema that captures filing information, company profile, financial highlights, business segments, geographic data, risk factors, and management discussions.
1. Using Python SDK with Pydantic for Schema Specification
We can use our Python SDK to build the schema, which looks like the following. Refer to the notebook for additional classes for extracting financial highlights, information from different financial statements, management discussions, etc.
python
from typing import Literal, Optional, List
from pydantic import BaseModel, Field
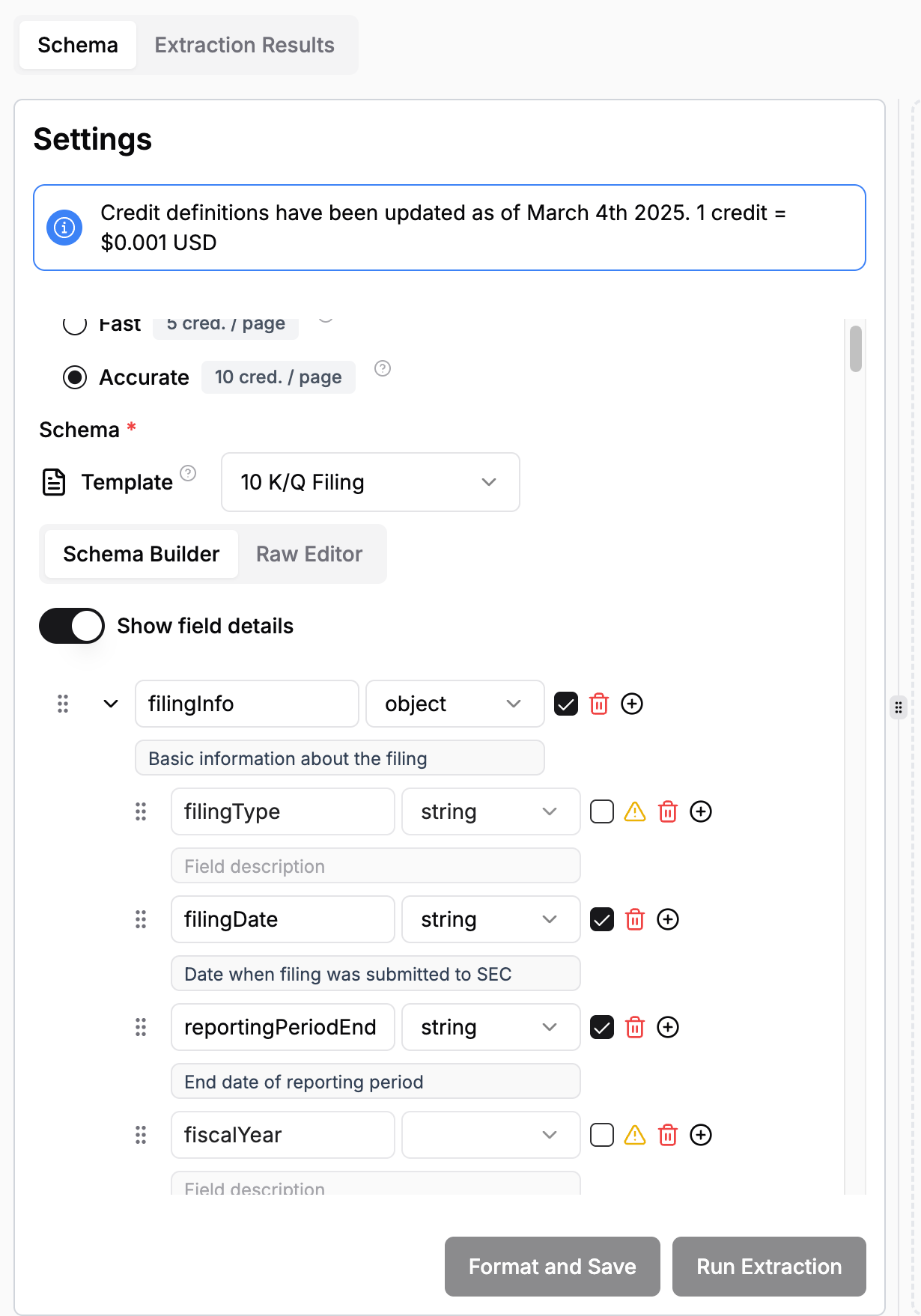
class FilingInfo(BaseModel):
"""Basic information about the SEC filing"""
filing_type: Literal["10-K", "10-Q", "10-K/A", "10-Q/A"] = Field(
description="Type of SEC filing"
)
filing_date: str = Field(description="Date when filing was submitted to SEC")
reporting_period_end: str = Field(description="End date of reporting period")
fiscal_year: int = Field(description="Fiscal year")
fiscal_quarter: int = Field(description="Fiscal quarter (if 10-Q)", ge=1, le=4)
# Additional model classes for company profile, financial data, etc.2. Using the Web UI
The notebook may give the impression that schema design is a one-shot process which is far from being the case. Usually, you start small, test the schema on a sample document, add descriptions and examples in case of inaccurate extractions and slowly and iteratively build your schema. This part might be easier to do with our Web UI. We have provided a pre-defined 10-K/Q extraction schema that you can play around with and modify.

Tips for Long-Form Document Extraction Schema Design
When working with extensive documents like SEC filings, consider these specialized schema design principles:
1. Strategic Field Optionality
For long documents with varying content across different companies or document instances, be strategic about which fields are required versus optional:
python
# Making fields optional when they might not be present in all filings
ebitda: Optional[float] = Field(
None,
description="EBITDA (Earnings Before Interest, Taxes, Depreciation, Amortization)"
)Too many required fields may force hallucination, while too many optional fields might result in missed information. Find the right balance based on your document set.
2. Clear Field Descriptions
In lengthy documents where similar concepts may appear in different contexts, precise field descriptions are essential. The more specific your descriptions, the more accurate your extraction results will be. As you find inaccuracies in the extractions, this is a good place to specify expected behavior by giving examples of what to do and what not to do.
python
gross_margin: float = Field(description="Gross margin percentage")
revenue_percentage: Optional[float] = Field(
None, description="Percentage of total company revenue (not growth rate)"
)3. Hierarchical Organization
Structure your schema to mirror the natural organization of the document. This hierarchical approach helps the extraction model maintain context across the document's logical sections.
python
class SECFiling(BaseModel):
filing_info: FilingInfo = Field(description="Basic information about the filing")
company_profile: CompanyProfile = Field(description="Essential company information")
financial_highlights: FinancialHighlights = Field(
description="Key financial metrics from this reporting period"
)
# Additional sections...4. Include Page Tracking
For long documents, tracking where information was found is important for verification. We have included page_numbers in the schema to be able to verify which section of the document was used to source certain data. Page numbers might be off by one due to the relative placement of the page numbers and the surrounding context from which the information is extracted, but it is a quick way to navigate to the relevant sections of the document and sanity test some fields. Providing an easier and more accurate way to cite source documents is high on our roadmap.
python
page_numbers: List[int] = Field(
description="Page numbers where the financial metrics were extracted from"
)Assessing Extraction Results
Here's the relevant section on financial highlights that was extracted. Take a look at the notebook to see the detailed extraction results.
json
{
'financial_highlights': {
'period_end': '2025-01-26',
'comparison_period_end': '2024-01-28',
'currency': 'USD',
'unit': 'thousands',
'revenue': 130497.0,
'revenue_prior_period': 60922.0,
'revenue_growth': 114.23,
'gross_profit': 97858.0,
'gross_margin': 75.0,
'operating_income': 81453.0,
'operating_margin': None,
'net_income': 72880.0,
'net_margin': 55.8,
'eps': None,
'diluted_eps': None,
'ebitda': None,
'free_cash_flow': None,
'page_numbers': [40, 41, 55, 56, 68]
},
}
The gross margin of 75% was extracted from page 40 below and the revenue figures and are from page 41 in the document. You can verify that the geographic breakdown of revenue is extracted from page 79 correctly.

LlamaExtract is Available in Public Beta!
LlamaExtract is now available for you to try out. It provides a comprehensive solution for structured data extraction workflows:
- Schema Iteration using the Web UI: We have a Web UI with a schema builder that can help you define your schema and iterate on different documents. We have a 10-K/Q schema for you to get started with if you are interested in trying this out. Start small and build from there! Refer to the tips above. Try your schema on different documents to see whether it generalizes to the target documents.
- Citations: For long-form document extraction, you can ask the extraction agent to provide page numbers for key figures extracted. This will help you quickly navigate to the relevant section of the document and verify the veracity of the information extracted. We are working on a more robust and convenient citation feature!
- Run scalable batch jobs: Once you have confidence that the extraction agent is working well, you can use your agent via our Python SDK to run scalable batch jobs.
Get started today! Sign up for LlamaParse with LlamaExtract.