
Introduction:
The concept of Multi-Tenancy in RAG (Retriever-Augmented Generation) systems has become increasingly vital, especially when it comes to data security and privacy. Multi-Tenancy, in simple terms, refers to a system’s ability to serve multiple users (‘tenants’) independently and securely.
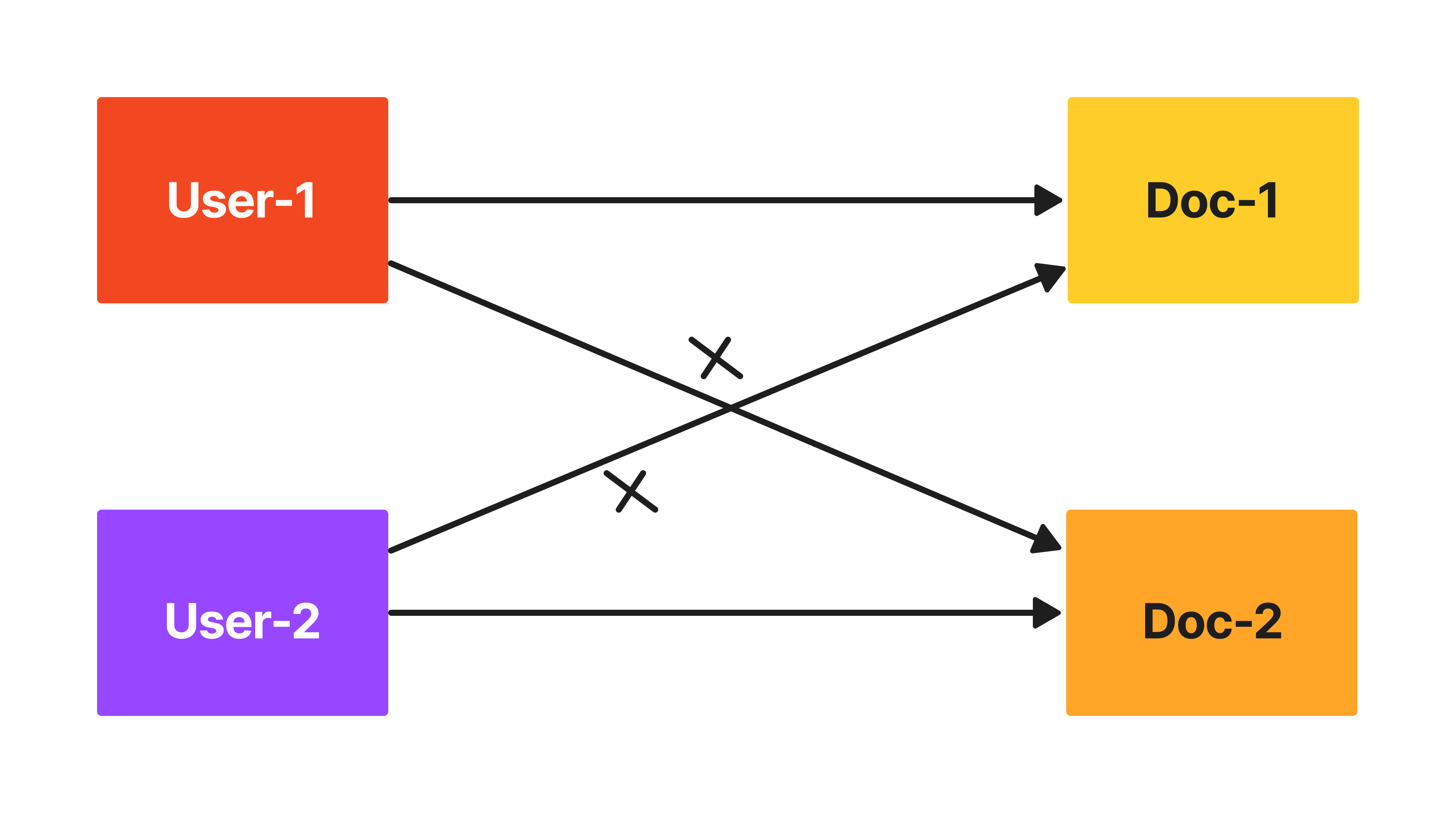
Consider this scenario: In a RAG system, there are two users, User-1 and User-2. Both have their own set of documents which they have indexed into the system. The critical aspect of Multi-Tenancy here is that when User-1 queries the system, they should only receive answers from the documents they have indexed, and not from the documents indexed by User-2, and vice versa. This separation is crucial for maintaining data confidentiality and security, as it prevents the accidental or unauthorized cross-referencing of private information between different users.
In the context of Multi-Tenancy in RAG systems, this means designing a system that not only understands and retrieves information effectively but also strictly adheres to user-specific data boundaries. Each user’s interaction with the system is isolated, ensuring that the retriever component of the RAG pipeline accesses only the information relevant and permitted for that particular user. This approach is important in scenarios where sensitive or proprietary data is involved, as it safeguards against data leaks and privacy breaches.
In this blog post, we will look into Building a Multi-Tenancy RAG System with LlamaIndex.
Solving Multi-Tenancy Challenges
The key to managing Multi-Tenancy lies within the metadata. When indexing documents, we incorporate user-specific information into the metadata before adding it to the index. This ensures that each document is uniquely tied to an individual user.
During the query phase, the retriever uses this metadata to filter and only access documents associated with the querying user. Subsequently, it performs a semantic search to retrieve the most relevant information segments, or ‘top_k chunks’, for that user. By implementing this approach, we effectively prevent the unauthorized cross-referencing of private information between different users, upholding the integrity and confidentiality of each user’s data.
Now that we’ve discussed the concept, let’s dive into the construction of a Multi-Tenancy RAG system. For an in-depth step-by-step guide, feel free to follow along with the subsequent instructions in our Google Colab Notebook.
Download Data:
We will use An LLM Compiler for Parallel Function Calling and Dense X Retrieval: What Retrieval Granularity Should We Use? papers for the demonstrations.
!wget --user-agent "Mozilla" "https://arxiv.org/pdf/2312.04511.pdf" -O "llm_compiler.pdf"
!wget --user-agent "Mozilla" "https://arxiv.org/pdf/2312.06648.pdf" -O "dense_x_retrieval.pdf"Load Data:
We will load the data of LLMCompiler paper for user Jerry and Dense X Retrieval paper for user Ravi
reader = SimpleDirectoryReader(input_files=['dense_x_retrieval.pdf'])
documents_jerry = reader.load_data()
reader = SimpleDirectoryReader(input_files=['llm_compiler.pdf'])
documents_ravi = reader.load_data()Create An Empty Index:
We will initially create an empty index to which we can insert documents, each tagged with metadata containing the user information.
index = VectorStoreIndex.from_documents(documents=[])Ingestion Pipeline:
The IngestionPipeline is useful for data ingestion and performing transformations, including chunking, metadata extraction, and more. Here we utilize it to create nodes, which are then inserted into the index.
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=512, chunk_overlap=20),
]
)Update Metadata and Insert Documents:
We will update the metadata of the documents with each user and insert the documents into the index.
# For user Jerry
for document in documents_jerry:
document.metadata['user'] = 'Jerry'
nodes = pipeline.run(documents=documents_jerry)
# Insert nodes into the index
index.insert_nodes(nodes)
# For user Ravi
for document in documents_ravi:
document.metadata['user'] = 'Ravi'
nodes = pipeline.run(documents=documents_ravi)
# Insert nodes into the index
index.insert_nodes(nodes)Define Query Engines:
We will define query engines for both the users with necessary filters.
# For Jerry
jerry_query_engine = index.as_query_engine(
filters=MetadataFilters(
filters=[
ExactMatchFilter(
key="user",
value="Jerry",
)
]
),
similarity_top_k=3
)
# For Ravi
ravi_query_engine = index.as_query_engine(
filters=MetadataFilters(
filters=[
ExactMatchFilter(
key="user",
value="Ravi",
)
]
),
similarity_top_k=3
)Querying:
# Jerry has Dense X Rerieval paper and should be able to answer following question.
response = jerry_query_engine.query(
"what are propositions mentioned in the paper?"
)The paper mentions propositions as an alternative retrieval unit choice. Propositions are defined as atomic expressions of meanings in text that correspond to distinct pieces of meaning in the text. They are minimal and cannot be further split into separate propositions. Each proposition is contextualized and self-contained, including all the necessary context from the text to interpret its meaning. The paper demonstrates the concept of propositions using an example about the Leaning Tower of Pisa, where the passage is split into three propositions, each corresponding to a distinct factoid about the tower.
# Ravi has LLMCompiler paper
response = ravi_query_engine.query("what are steps involved in LLMCompiler?")LLMCompiler consists of three key components: an LLM Planner, a Task Fetching Unit, and an Executor. The LLM Planner identifies the execution flow by defining different function calls and their dependencies based on user inputs. The Task Fetching Unit dispatches the function calls that can be executed in parallel after substituting variables with the actual outputs of preceding tasks. Finally, the Executor executes the dispatched function calling tasks using the associated tools. These components work together to optimize the parallel function calling performance of LLMs.
# This should not be answered as Jerry does not have information about LLMCompiler
response = jerry_query_engine.query("what are steps involved in LLMCompiler?")I’m sorry, but I couldn’t find any information about the steps involved in LLMCompiler in the given context.
As demonstrated, if Jerry queries the system regarding a document indexed by Ravi, the system does not retrieve any answers from that document.
What’s Next?
We have included a MultiTenancyRAGPack within the LlamaPacks and Replit template which offers a Streamlit interface for hands-on experience. Be sure to explore it.


