
Build state-of-the-art RAG applications for the enterprise by leveraging LlamaIndex’s market-leading RAG strategies with AI21 Labs’ long context Foundation Model, Jamba-Instruct.
We at AI21 Labs are excited to announce that our groundbreaking Jamba-Instruct foundation model is now available through leading data framework LlamaIndex. With this integration, developers can now build powerful RAG enterprise applications with enhanced accuracy and cost-efficiency due to Jamba-Instruct’s impressive 256K context window and LlamaIndex’s sophisticated end-to-end offerings for RAG.
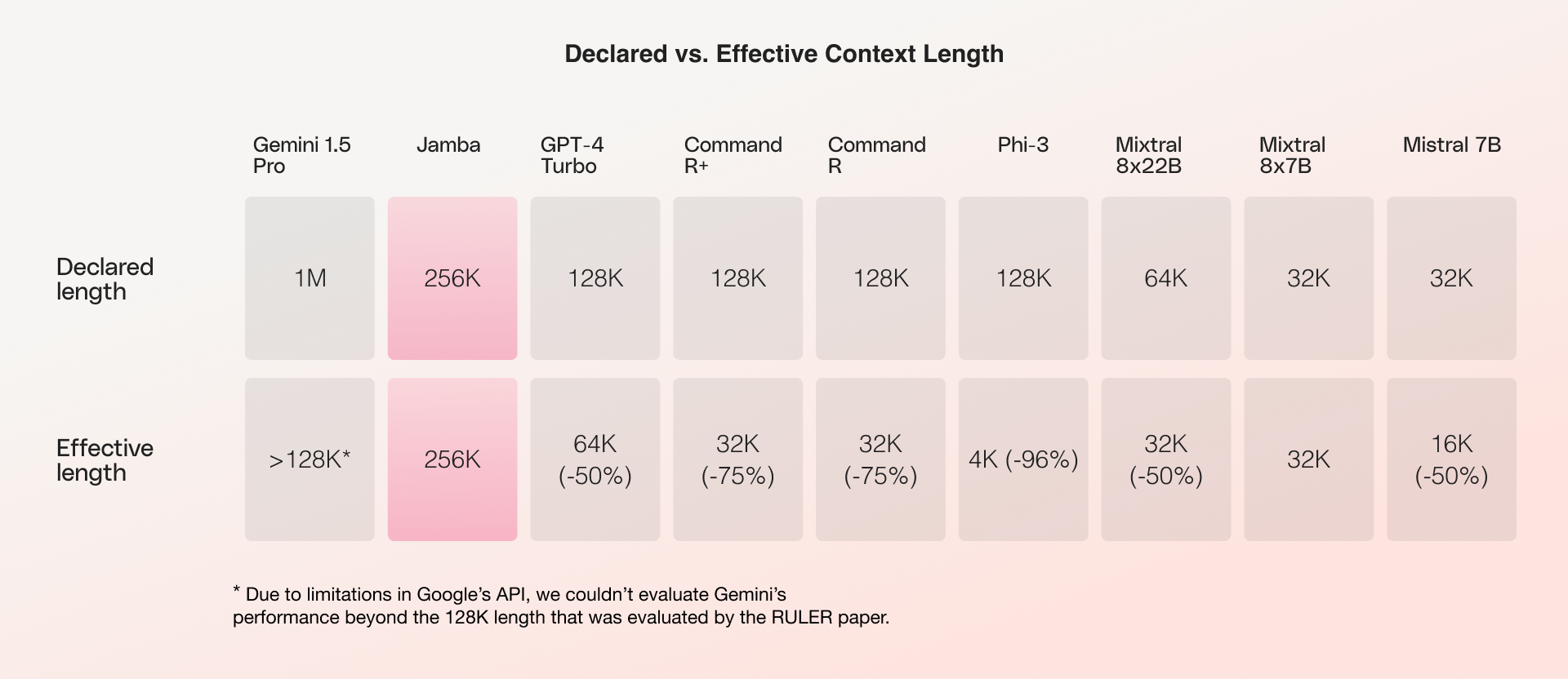
While many models declare long context windows, researchers at NVIDIA found that most falter under evaluation, revealing a discrepancy between their claimed and effective context window lengths. Jamba-Instruct is one of the few models on the market to not only achieve parity between its declared and effective lengths, but to do so with a much longer context window length than any other model in its size class.

By offering a context window of 256K—roughly equivalent to 800 pages of text—Jamba-Instruct increases the number of retrieved chunks and can vastly improve the entire RAG system, rather than trying to improve the search mechanism or incorporating an additional reranking component. Using a long context foundation model like Jamba-Instruct makes querying private enterprise data with RAG both more reliable and easier.
In the following notebook (also available directly on colab), we’ll walk through an example of querying a collection of financial documents, showing how Jamba-Instruct’s 256K context window allows the RAG pipeline to retrieve more chunks at once in order to deliver an accurate answer.
RAG Q&A on financial documents
To get started, these are the packages you need to install. You will also need API keys to set up OpenAI for embeddings and AI21 for Jamba-Instruct.
python
!pip install llama-index
!pip install -U ai21
!pip install llama-index-llms-ai21
import os
from llama_index.core.llama_dataset import download_llama_dataset
from llama_index.core.llama_pack import download_llama_pack
from llama_index.core import VectorStoreIndex
from llama_index.core import SimpleDirectoryReader
from llama_index.llms.ai21 import AI21
os.environ['OPENAI_API_KEY'] = 'YOUR_OPENAI_API_KEY' # For embeddings
os.environ['AI21_API_KEY'] = 'YOUR_AI21_API_KEY' # For the generation
# Setup jamba instruct as the llm
llm = AI21(
model='jamba-instruct',
temperature=0,
max_tokens=2000
)Next, download 5 10-K forms from Amazon from Amazon’s Investor Relations page.
python
# Get the data - download 10k forms from AMZN from the last five years
os.mkdir("data")
!wget 'https://d18rn0p25nwr6d.cloudfront.net/CIK-0001018724/c7c14359-36fa-40c3-b3ca-5bf7f3fa0b96.pdf' -O 'data/amazon_2023.pdf'
!wget 'https://d18rn0p25nwr6d.cloudfront.net/CIK-0001018724/d2fde7ee-05f7-419d-9ce8-186de4c96e25.pdf' -O 'data/amazon_2022.pdf'
!wget 'https://d18rn0p25nwr6d.cloudfront.net/CIK-0001018724/f965e5c3-fded-45d3-bbdb-f750f156dcc9.pdf' -O 'data/amazon_2021.pdf'
!wget 'https://d18rn0p25nwr6d.cloudfront.net/CIK-0001018724/336d8745-ea82-40a5-9acc-1a89df23d0f3.pdf' -O 'data/amazon_2020.pdf'
!wget 'https://d18rn0p25nwr6d.cloudfront.net/CIK-0001018724/4d39f579-19d8-4119-b087-ee618abf82d6.pdf' -O 'data/amazon_2019.pdf'Set up your index and query engine to create the retrieval and generation components of your RAG system.
python
# Setup the index
file_list = [os.path.join("data", f) for f in os.listdir("data")]
amzn_10k_docs = SimpleDirectoryReader(input_files=file_list).load_data()
index = VectorStoreIndex.from_documents(documents=amzn_10k_docs)
# Build a query engine
default_query_engine = index.as_query_engine(llm)Let’s enter a query to make sure our RAG system is working.
python
answer = default_query_engine.query("What was the company's revenue in 2021?")
print(answer.response)text
The company's revenue in 2021 was $469,822 million.Great! It works. Now let’s try a similar query to continue validating.
python
answer = default_query_engine.query("What was the company's revenue in 2023?")
print(answer.response)text
The company's revenue in 2023 was not explicitly mentioned in the provided context. However, it is mentioned that the company's operating income increased to $36.9 billion in 2023, compared to $12.2 billion in 2022.We can see there’s a problem—we know that the answer to our question is most definitely included in our documents, yet our RAG system is claiming that it cannot find the answer. That’s because the default amount of retrieved chunks is rather small (a few chunks). This makes the whole system prone to errors and failing to capture information that is indeed located in the documents.
However, with Jamba-Instruct, a model which handles a 256K context window effectively, we can increase the number of retrieved chunks from just a few (default value) to 100 and vastly improve the entire RAG system.
Let’s build a new query engine on top of our existing index and try the query that failed before.
python
# Large amount of chunks in the retrieval process
extended_query_engine = index.as_query_engine(llm,
similarity_top_k=100)
answer = extended_query_engine.query("What was the company's revenue in 2023?")
print(answer.response)text
The company's revenue in 2023 was $574.785 million.We see that the RAG system, with the help of Jamba-Instruct’s 256K context window, is now able to produce the accurate answer.
Let’s try one more answer to validate our new RAG system.
python
answer = default_query_engine.query("Was there a stock split in the last five years?")
print(answer.response)text
No, there was no stock split in the last five years.python
answer = extended_query_engine.query("Was there a stock split in the last five years?")
print(answer.response)text
Yes, there was a stock split in the last five years. On May 27, 2022, Amazon.com, Inc. effected a 20-for-1 stock split of its common stock.Context is king
Often, the debate is framed as “RAG vs. long context.” We at AI21 Labs believe that’s the wrong way to look at it. Rather, it’s long context plus RAG. When paired together in an AI system, a long context model enhances the quality and accuracy of a RAG system, especially useful in enterprise contexts that involve lengthy documents or vast databases of information.
Going forward, as RAG systems continue to scale, the number of documents and lengths of chunks will drastically increase. Only a long context model—whose context length truly delivers—can handle this amount of text.


