A guide to get started creating RAG applications with LlamaIndex using Azure OpenAI and deployed on Microsoft Azure.
If you are reading this, chances are you have used generative AI like ChatGPT or Azure OpenAI. You have utilized it to enhance your daily work processes or integrated AI into your application to provide a better customer experience.
Ideally you want your intelligent apps to use your own business data when providing responses to your customers. To address this need, you require your application to implement an architecture known as Retrieval-Augmented Generation (RAG). LlamaIndex is a great framework that helps you achieve this goal, which is the focus of this article.
In this article you will learn about:
- The RAG architecture and how LlamaIndex can help you implement RAG multi-agent applications.
- The architecture of a sample LlamaIndex application.
- The deployment of a LlamaIndex application to Microsoft Azure using the Azure Developer CLI, azd.
What is RAG - Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) is a framework that improves AI text generation by combining two key components:
- Retriever: This part searches a large collection of documents to find relevant information related to a given query.
- Generator: This model uses the retrieved information to generate a more accurate and contextually rich response.
By combining these two components, RAG allows AI models to pull in external knowledge, resulting in higher quality and more relevant responses.
How does LlamaIndex implement RAG?
To implement a RAG system using LlamaIndex, you can follow these general steps, which include setting up the data ingestion, and the generation components:
- Data Ingestion:
- Load your documents into LlamaIndex using a document loader such as SimpleDirectoryReader. This reader, for example, helps in importing data from various sources such as PDFs, APIs, or SQL databases.
- Break down large documents into smaller, manageable chunks using the SentenceSplitter.
- Index Creation:
- Create a vector index of these document chunks using VectorStoreIndex. This allows for efficient similarity searches based on embeddings.
- Optionally, for complex datasets, you can use recursive retrieval techniques to manage hierarchically structured data and retrieve relevant sections based on user queries.
- Query Engine Setup:
- Convert the vector index into a query engine using asQueryEngine with parameters such as similarityTopKto define how many top documents should be retrieved.
- For more advanced setups, use agents. Create a multi-agent system where each agent is responsible for specific documents, and a top-level agent coordinates the overall retrieval process.
- Retrieval and Generation:
- Implement the RAG pipeline by defining an objective function that takes user queries and retrieves relevant document chunks. This function can also evaluate the retrieval chunks to ensure they match the user's query.
- Use the RetrieverQueryEngineto perform the actual retrieval and query processing. This can include additional post-processing steps like re-ranking the retrieved documents using tools such as CohereRerank.
For a practical example, we have provided you with a sample application to demonstrate a complete RAG implementation using Azure OpenAI as the AI provider.
Practical RAG sample application
For the remainer of this article, we'll focus on the use case of building a RAG type application on Azure using LlamaIndex and Azure OpenAI. You will use one of the provided starter templates: TypeScript or Python.
Requirements to run the samples
First let's explain what you'll need:
- Azure Developer CLI, azd: this is a CLI, a command line tool that can easily deploy your entire app, backend, frontend, databases etc. You can use azd with extensible blueprint templates that includes everything you need to get an application up and running on Azure.
- Azure account: you will need an Azure account to deploy things. get an Azure account for free and you'll get some free Azure credits to get started
- Samples: we've created two samples that will deploy a RAG type application on Azure. The azd starter templates are designed to help you create a serverless RAG application with LlamaIndex and Azure OpenAI in a few simple steps. We are going to highlight two sample applications that were created based on the great create-llama tool:
1. For TypeScript: https://github.com/Azure-Samples/llama-index-javascript
2. For Python: https://github.com/Azure-Samples/llama-index-python
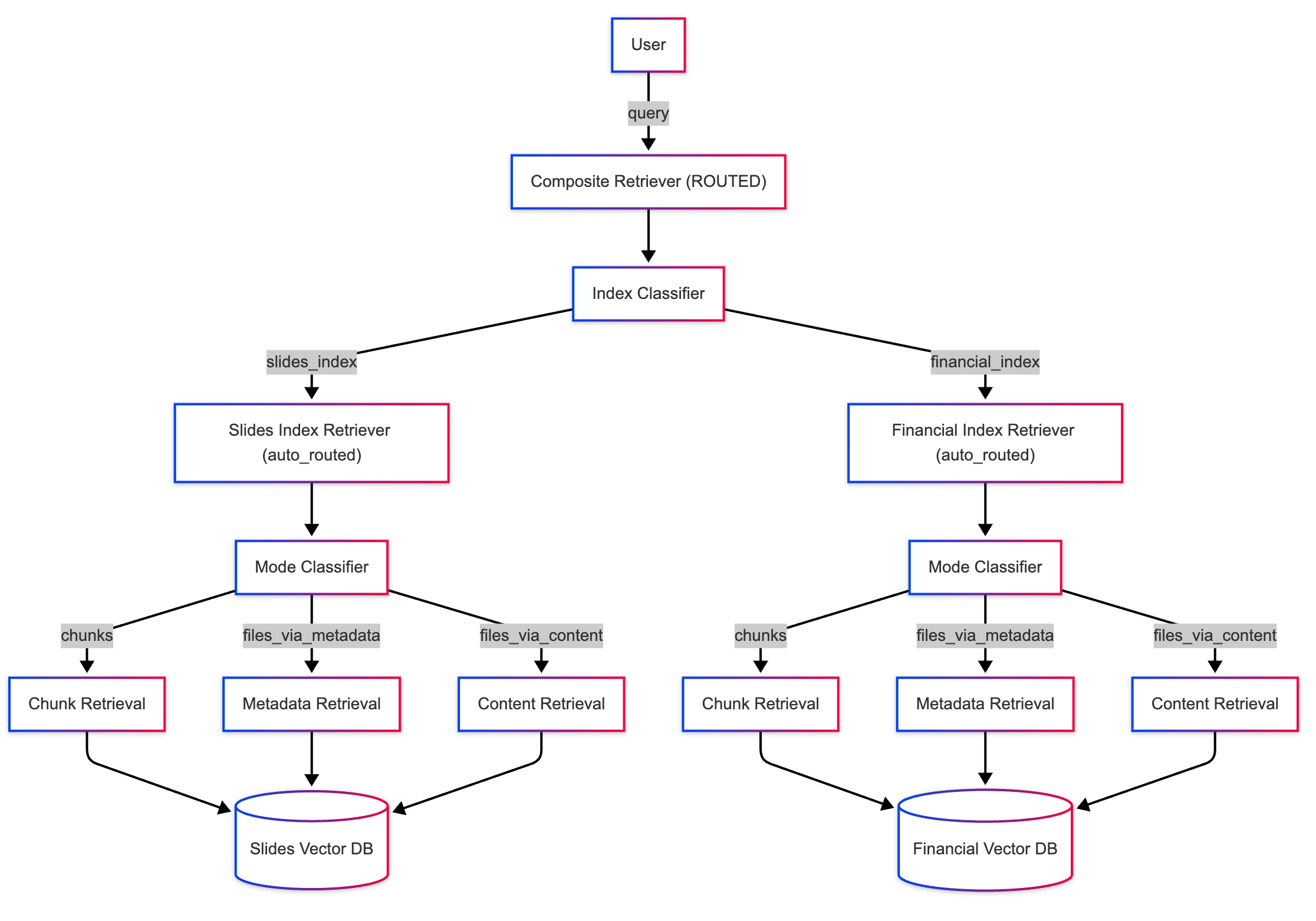
High level architecture
Both sample applications are built based on the same architecture:
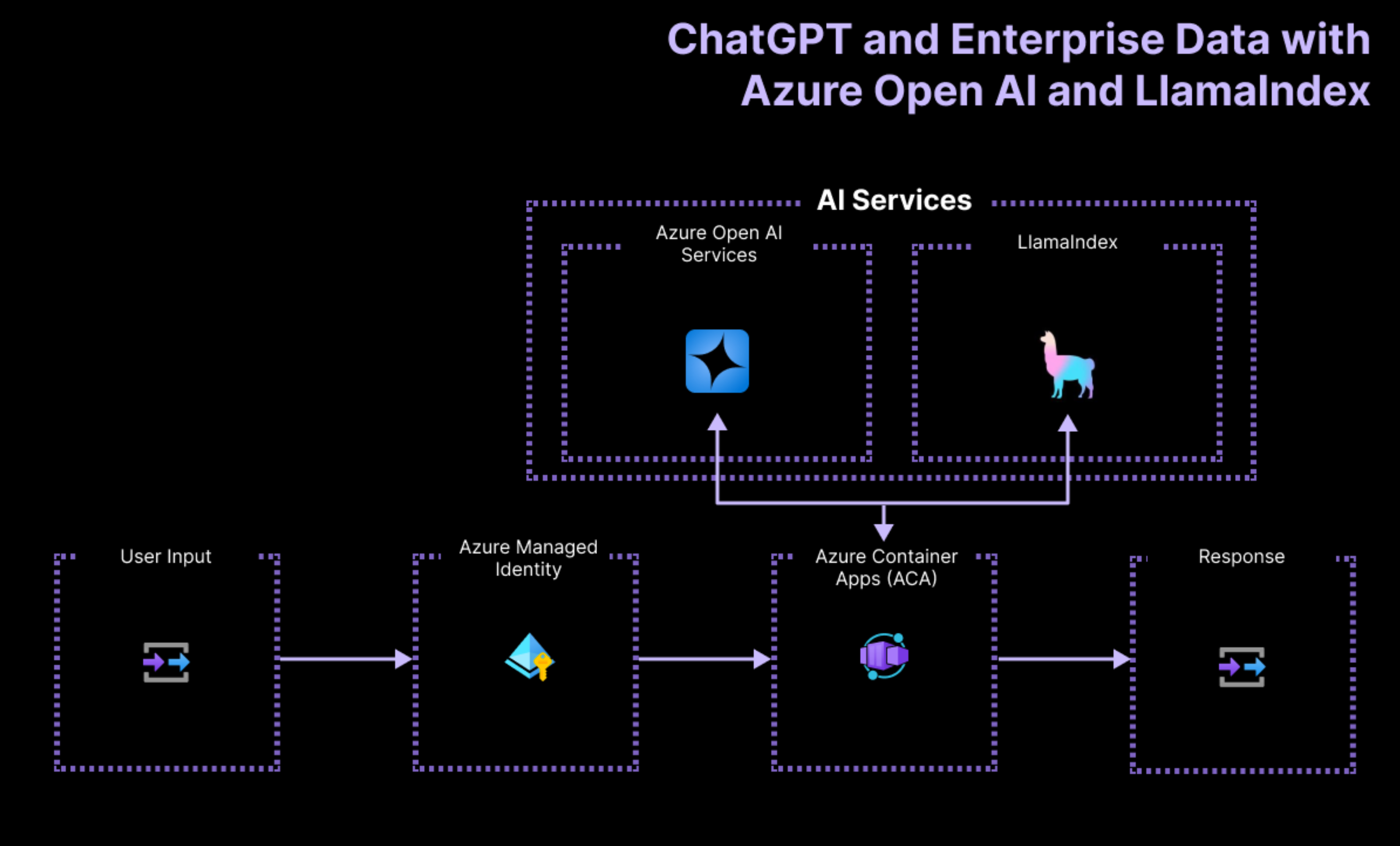
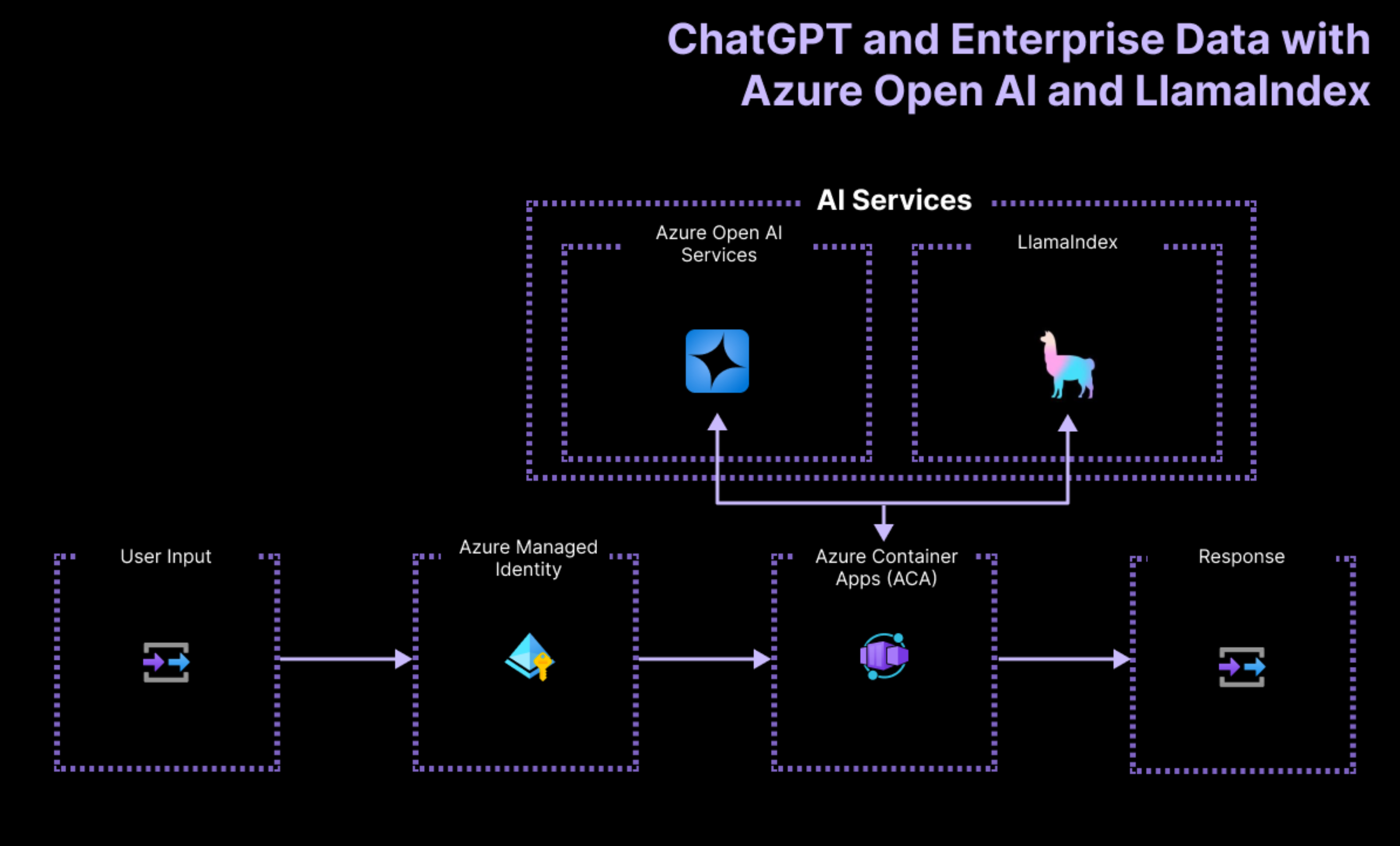
The architecture of the application relies on the following services and components:
- Azure OpenAIrepresents the AI provider that we send the user's queries to.
- LlamaIndexis the framework that helps us ingest, transform and vectorize our content (PDF file) and create a search index from our data.
- Azure Container Apps is the container environment where the application is hosted.
- Azure Managed Identity helps us ensure best in class security and eliminates the requirements for you as a developer to deal with credentials and API keys.
To learn more about what Cloud resources get deployed on Azure, check out the infra folder available in all our samples.
Example user workflows
The sample application contains logic code for the following two workflows:
1. Data ingestion, where data is fetched and vectorized and search indexes are created. Vector indexes are stored in the cache sub folder. The data itself lives in a data folder. Should you want to add more files like additional PDFs or Word files, this is where you should add them. There are existing Vector indexes but if you need to generate new ones (if you change the content of the data folder), you can run the following command:
sh
npm run generateThis command will invoke the following code in TypeScript:
typescript
async function generateDatasource() {
console.log(`Generating storage context...`);
// Split documents, create embeddings and store them in the storage context
const ms = await getRuntime(async () => {
const storageContext = await storageContextFromDefaults({
persistDir: STORAGE_CACHE_DIR,
});
const documents = await getDocuments();
await VectorStoreIndex.fromDocuments(documents, {
storageContext,
});
}); or in Python:
sh
cd backend
poetry run generate which will invoke this code:
python
def generate_datasource():
init_settings()
logger.info("Creating new index")
storage_dir = os.environ.get("STORAGE_DIR", "storage")
# load the documents and create the index
documents = get_documents()
index = VectorStoreIndex.from_documents(
documents,
)
# store it for later
index.storage_context.persist(storage_dir)
logger.info(f"Finished creating new index. Stored in {storage_dir}") 2. Serving prompt requests. In this part of the application, we receive user input i.e.prompts, which are sent to Azure OpenAI. To augment these prompts a chat engine is created consisting of a connection to the LLM and the vector index loaded as a retriever. Configuring access to Azure OpenAI is made easy with a few lines:
In TypeScript:
typescript
const credential = new DefaultAzureCredential();
const azureADTokenProvider = getBearerTokenProvider(
credential,
"https://cognitiveservices.azure.com/.default",
);
const azure = {
azureADTokenProvider,
deployment: "gpt-35-turbo",
};
Settings.llm = new OpenAI({ azure }); Or in Python:
python
credential = DefaultAzureCredential()
token_provider = get_bearer_token_provider(
credential,
"https://cognitiveservices.azure.com/.default"
)
llm_config = {
"engine": llm_deployment,
"azure_endpoint": azure_openai_endpoint,
"azure_ad_token_provider": token_provider,
"use_azure_ad": True,
"temperature":float(os.getenv("LLM_TEMPERATURE", DEFAULT_TEMPERATURE)),
"max_tokens": int(max_tokens) if max_tokens is not None else None,
}
Settings.llm = AzureOpenAI(**llm_config) In this sample, we use the @azure/identity Node.js or PyPI package and import the DefaultAzureCredential chained credential strategy that seamlessly checks and uses a valid token from an existing Azure session, based on what is available in the current environment without changing your code.
When your application is hosted in Azure, managed identity is also used for seamless authentication in your production environments.
Important packages used for the JavaScript sample
Here's some packages used in the solution worth mentioning. For a detailed list of all packages used, check out the package.json file.
- The llamaindex core library providing core functionality on connecting to LLMs, facilitates vector index creation and more.
- @llamaindex/pdf-viewer is used to retrieve structured information from a PDF like tables, lists, paragraphs more and is part of the chunking process, where the data is divided into smaller strips, e.g.chunks, and each chunk is turned into vectorized form so it can be used later for semantic comparison.
- As discussed earlier, @azure/identity is used to connect to Azure using Azure Managed Identity, (managed identity means Azure handles the identity for you via Microsoft EntraID instead of using API keys which are considered less secure).
Important packages used for the Python sample
The Python sample uses Poetry for dependency management and installation. For a detailed list of all packages used, checkout the pyproject.toml file.
- The llamaindex core Python library providing core functionality on connecting to LLMs, facilitates vector index creation and more.
- FastAPI, a Python web framework is used to create the API that takes in the user input and returns a response.
- The Python azure-identity package is used to connect to Azure using Azure Managed Identity, (managed identity means Azure handles the identity for you via Microsoft EntraID instead of using API keys which are considered less secure).
Running the samples
Before running any of the samples, and using Azure OpenAI, it is worth mentioning that you need to provision the necessary Azure resources.
You can run these templates by using GitHub Codespaces. Follow these links and then click "Create codespace" as shown to launch a VS Code instance in your browser (this may take a few minutes while the containers are built):

For TypeScript: https://github.com/Azure-Samples/llama-index-javascript
For Python: https://github.com/Azure-Samples/llama-index-python
1.Open a terminal window in your Codespaces instance.
2. Type the following command to sign into your Azure account:
azd auth login
3. Run the next command to provision, package and deploy the sample application to Azure:
azd up
Once the command completes, you should see output from the terminal indicating success.
Congratulations! At this point, you should be able to access your deployed application from the provided URL endpoint. To run and develop on the application locally, you need to:
4. Run the following commands to install the application dependencies and run the app:
npm install
npm run dev
This will open the application on the default port 3000 in your Codespaces instance, or http://localhost:3000 in your browser locally. You should see your application rendered like so:
NOTE: If you would like to run these samples locally in VS Code Dev Containers or directly on your filesystem, the README files in the samples have all the details about the tools and requirements.
What's next?
This guide has demonstrated how to build a serverless RAG (Retrieval-Augmented Generation) application using LlamaIndex and Azure OpenAI, deployed on Microsoft Azure. The key argument presented is that integrating your own business data into AI applications enhances the relevance and quality of responses, a crucial need for intelligent apps serving customers.
In this post we addressed the implementation of RAG architecture with LlamaIndex, detailing the steps from data ingestion and index creation to query engine setup and deployment on Azure. By following this guide, you can leverage Azure's robust infrastructure and LlamaIndex's capabilities to create powerful AI applications that provide contextually enriched responses based on your data.
By deploying on Azure, you also benefit from scalability, security, and ease of management, reinforcing the practical application of the RAG model in real-world scenarios.
We're excited to see what you build with these sample applications. Feel free to fork them and like the GitHub repositories to receive the latest changes and new features.