

(Authored by Andrei Fajardo at LlamaIndex)

Intro
A few weeks back, we launched our very first set of llama-datasets, namely the LabelledRagDataset. The main purpose of these llama-datasets is to provide builders with the means to benchmark their LLM systems in an effective and efficient manner. In the couple of weeks since that launch date, we’ve amassed over a dozen LabelledRagDatasets via both staff and community contributions (all of which are available for download through LlamaHub)!
The fun doesn’t stop there though: today we’re introducing two new llama-dataset types: LabelledEvaluatorDataset and the LabelledPairwiseEvaluatorDataset. These new llama-dataset types are meant for evaluating or benchmarking an LLM evaluator. Indeed, the adopted standard for evaluating LLM responses is to use a strong LLM as an evaluator. This approach is certainly more scalable, faster, and cheaper than using human evaluators via crowdsourcing. However, these LLM evaluators themselves must also be continuously evaluated rather than blindly trusted.
In this post, we provide a brief overview of the new llama-datasets as well as provide some very interesting results from benchmarking Google’s Gemini and OpenAI’s GPT models as LLM evaluators on the MT-Bench datasets which we’ve converted into the new llama-dataset types.
A primer on the new llama-datasets
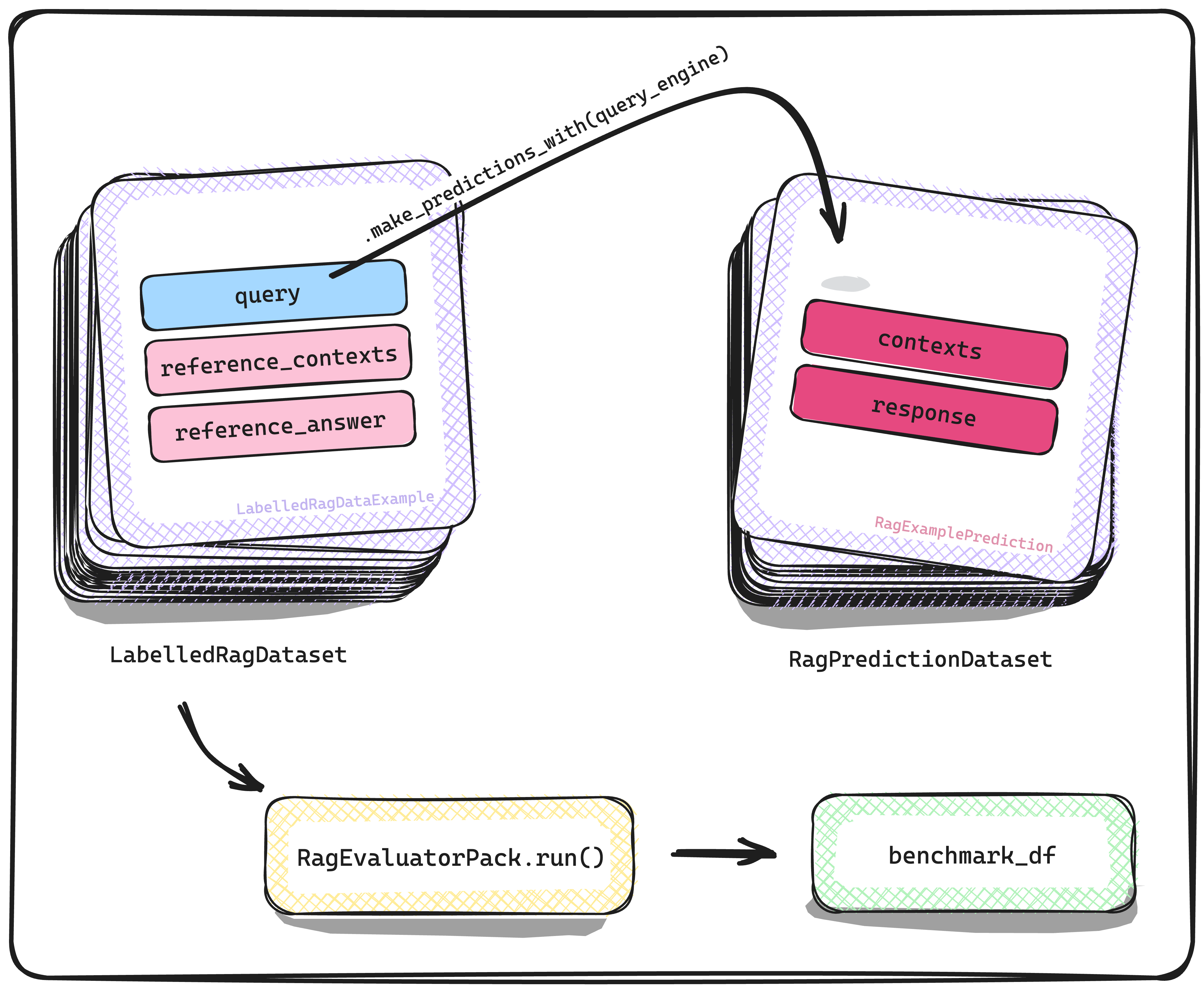
Before getting into the new llama-datasets, recall that with LabelledRagDataset our end goal was to use it to evaluate or benchmark a Retrieval-Augmented Generation (RAG) system. The way to do that with our llama-dataset abstractions is to build a QueryEngine (i.e., a RAG system) and then use it to make “predictions” over the LabelledRagDataset. With the predictions in hand, we can evaluate the quality of these predictions by comparing it to the corresponding reference attributes of the LabelledRagDataset.

In a similar vein, the new llama-datasets are meant to benchmark an LLM evaluator. Let’s go through the first kind, the LabelledEvaluatorDataset. Here, instead of the RAG system making predictions on a LabelledRagDataset we have an LLM evaluator making “predictions” over a LabelledEvaluatorDataset — predictions in this context means that the LLM evaluator is evaluating the response produced by another LLM model to a given query. As before, with the predictions in hand, we can measure the goodness of the LLM evaluator’s evaluations by comparing it to the corresponding reference attributes of the LabelledEvaluatorDataset.

The second llama-dataset we’re introducing today can be considered an extension of the first one. The LabelledPairwiseEvaluatorDataset is similarly used for benchmarking an LLM evaluator. However, there is a subtle difference in the evaluation task as here the LLM evaluator compares two generated answers from two separate LLMs. Outside of this difference, the flow for using this llama-dataset to benchmark an evaluator remains the same.

Benchmarking Gemini and GPT models as LLM evaluators: Gemini achieves GPT-3.5 performance!
In this section, we will put our new llama-dataset types to use in order to pit Gemini Pro against GPT models. For this, we’re going to use slightly adapted versions of the MT-Bench dataset. These adapted versions have been made available for download and use through LlamaHub along with today’s release!
Mini MT-Bench Single Grading Dataset
This llama-dataset is a LabelledEvaluatorDataset and is a miniature version of the MT-Bench single-grading dataset. In particular, we consider all of the 160 original questions (i.e., 80 x 2, since MT Bench is a two-turn question dataset), but only the responses produced by Llama2-70b. For the reference evaluations, we use GPT-4. As with the original LabelledRagDataset, we’ve produced a new llama-pack EvaluatorBenchmarkerPack (of course, also made available in today’s release!) to make benchmarking an LLM evaluator on the new llama-datasets relatively effortless. The below snippet of code is how you can replicate the results of this benchmark
from llama_index.llama_dataset import download_llama_dataset
from llama_index.llama_pack import download_llama_pack
from llama_index.evaluation import CorrectnessEvaluator
from llama_index.llms import Gemini
from llama_index import ServiceContext# download dataset evaluator_dataset, _ = download_llama_dataset( "MiniMtBenchSingleGradingDataset", "./mini_mt_bench_data" )# define evaluator gemini_pro_context = ServiceContext.from_defaults( llm = Gemini(model="models/gemini-pro", temperature=0) ) evaluator = CorrectnessEvaluator(service_context=gemini_pro_context)# download EvaluatorBenchmarkerPack and define the benchmarker EvaluatorBenchmarkerPack = download_llama_pack("EvaluatorBenchmarkerPack", "./pack") evaluator_benchmarker = EvaluatorBenchmarkerPack( evaluator=evaluators["gpt-3.5"], eval_dataset=evaluator_dataset, show_progress=True, )# produce the benchmark result benchmark_df = await evaluator_benchmarker.arun( batch_size=5, sleep_time_in_seconds=0.5 )
Benchmark Results

Observations
- It seems that Gemini-Pro and GPT-3.5 are quite close in terms of their closeness to the reference evaluator GPT-4!
- As for GPT-4 versus the reference GPT-4, this is mostly used for assessing self-consistency of the LLM, for which we see it does a fairly good job at that.
MT-Bench Human Judgement Dataset
For this benchmark, we’ll evaluate the LLM evaluators on the task of ranking two LLM responses, to determine which of the two is the better one. And it is for this such task that LabelledPairwiseEvaluatorDataset exists. The llama-dataset that we’ve curated here is a slightly adapted version of the original MT-Bench Human Judgement dataset. Specifically, in the original dataset, there are some replications with respect to the triple (query, model A, model B) examples since for some of these more than one human evaluation was provided. Since our prompt allows the LLM evaluator to deem a tie, and to our knowledge, this wasn’t made an option for the human evaluators, we have aggregated the results across the different human evaluations to get the proportion of times model A wins versus model B for each triple (query, model A, model B). We then say that human evaluators deem a tie if the proportion lies between 0.4 and 0.6. It should be emphasized here that the reference evaluations are provided by humans, and so the benchmark metrics that we produce and share here represent the LLM agreement with humans.
(We skip showing the code snipped to produce the results here, because they’re essentially the same as the previously shared code snipper with the exception of requiring a PairwiseComparisonEvaluator instead of a CorrectnessEvaluator.)
Benchmark Results

Observations
- In terms of agreement rates, all three models seem quite close. Note again that these are conditional on the prediction/evaluation being valid. And so, one should “discount” these with the invalid and inconclusive counts.
- Gemini Pro and GPT-3.5 seem to be a bit more assertive than GPT-4 resulting in only 50–60 ties to GPT-4’s 100 ties.
- Overall, it seems that Gemini Pro is up to snuff with GPT models, and would say that it outperforms GPT-3.5!
Go now and evaluate your evaluators (and eat your veggies)!
It is, for obvious reasons, important to evaluate your LLM evaluators, as these are now being relied upon to evaluate the performance of our LLM systems — a broken compass is not really helpful! With these newly introduced llama-datasets, we hope that it is easy for you to compile your own benchmark datasets on your own data, and then even easier to produce your benchmark metrics. As mentioned before, the two llama-datasets discussed in this blog are available for download and use through LlamaHub. Be sure to visit and make use of the datasets there to build an exhaustive benchmark suite! (We welcome contributed llama-datasets as well!)


