In a recent blog post, we introduced our llama-index-networks library extension that makes it possible to build a network of RAG systems, which users can query. The benefits of such a network are clear: connecting to a diverse set of knowledge stores—that one may not otherwise have access to—means more accurate responses to an even wider breadth of queries.
A main caveat to these networks though is that the data being shared across the network ought to be privacy safe. In this blog post, we demonstrate how to turn private, sensitive data into privacy-safe versions that can be subsequently and safely shared across a network. To do so, we’ll be relying on some recent developments in the area of Privacy-Enhancing Techniques.
The story of Alex, Bob and Beth continues
To illustrate all of this, we will again make use of our three made-up characters Alex, Bob and Beth. As a quick reminder, Alex is a data consumer who wants to access the data sources that Bob and Beth possess and are willing to supply.
We showed then how such data a collaboration could be permitted through llama-index-networks by taking the following steps:
- Bob and Beth both build their respective QueryEngine’s (RAG in llama-index lingo)
- Bob and Beth both expose their QueryEngine behind a ContributorService
- Alex builds a NetworkQueryEngine that connects to Bob and Beth’s ContributorService’s
In part two of this story, we add the wrinkle that Bob and Beth possess private, sensitive data that must be carefully protected before to sharing to Alex. Or, put in another way, we need to add a step 0. to the above steps which applies protective measures to the private datasets.
Measures for protecting data (or more specifically the data subjects) depends on the use-case factors such as what the data involves and how its intended to be shared and ultimately processed. De-anonymizing techniques such as wiping PII (i.e., personal identifiable indicators) are often applied. However, in this blog post we highlight another privacy-enhancing technique called Differential Privacy.
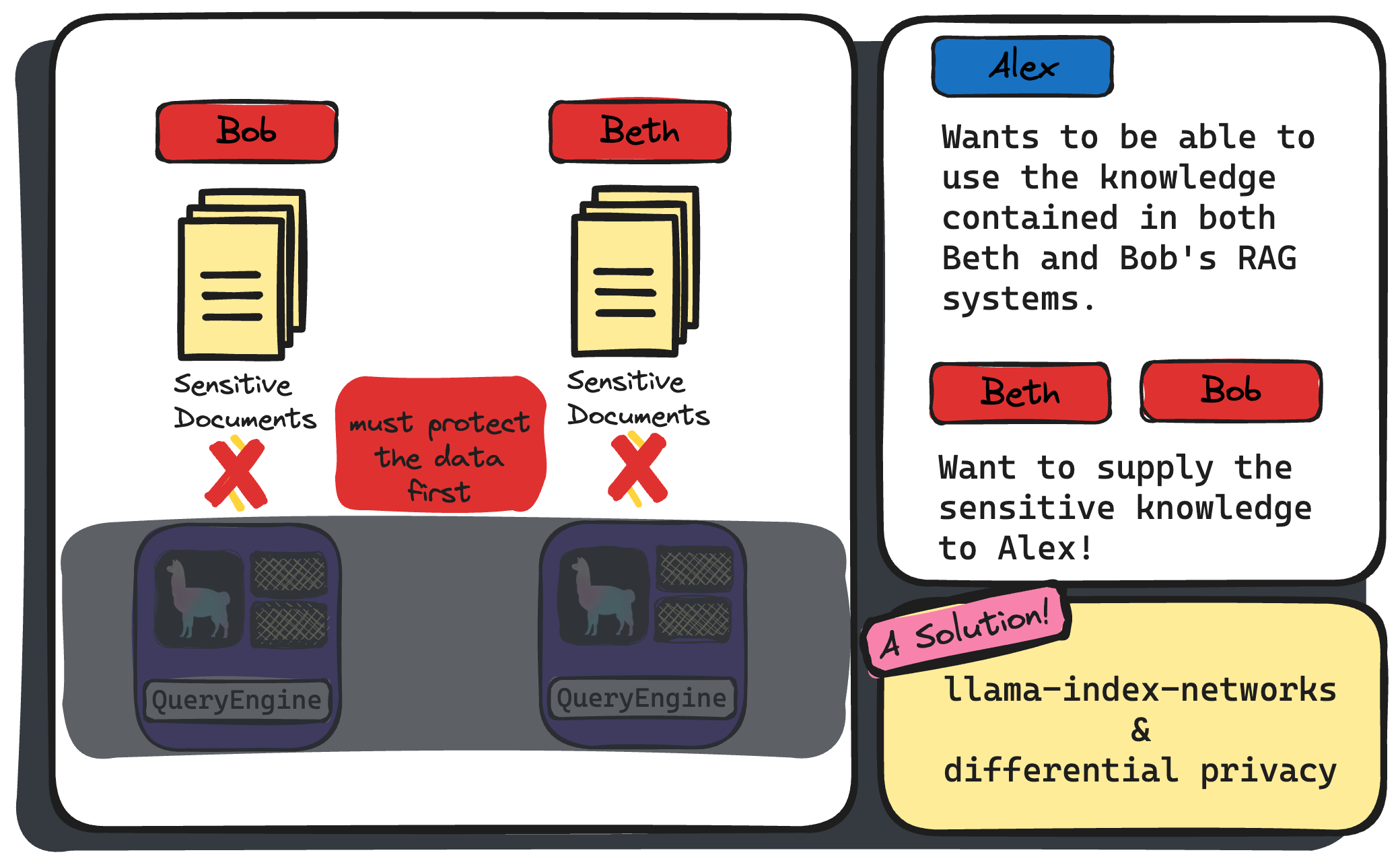
Part 2: of Alex, Bob and Beth. This time Bob and Beth have sensitive data that they want to share, but can’t unless protective measures are applied before sharing across the network.
Sidebar: differential privacy primer
In short, differential privacy is a method that provides mathematical guarantees (up to a certain level of chance) that an adversary would not be able to learn that a specific individual belonged to a private dataset after only seeing the output of running this private dataset through a protected data processing step. In other words, an individual’s inclusion in the private dataset cannot be learned from the output of a differentially-private algorithm.
By protecting against the threat of dataset inclusion, we mitigate the risk that an adversary is able to link the private data with their external sources to learn more about the data subject and potentially cause more privacy harms (such as distortion).
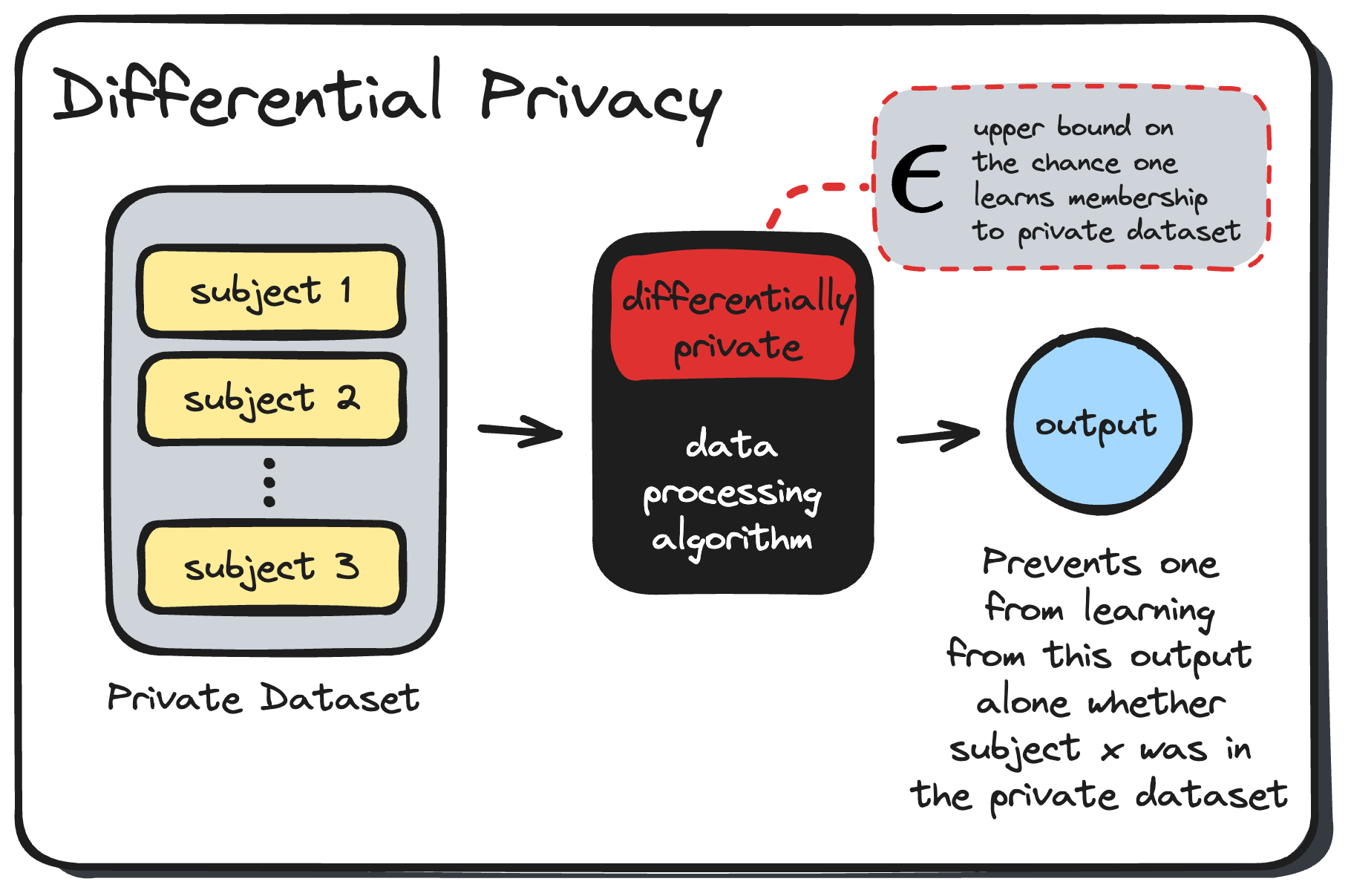
A light introduction to differential privacy.
Coming back to the story of Alex, Bob and Beth, in order to protect Bob and Beth’s data, we will make use of an algorithm that uses a pre-trained LLM to create synthetic copies of private data that satisfies the differential private mathematical guarantees. This algorithm was introduced in the paper entitled “Privacy-preserving in-context learning with differentially private few-shot generation” by Xinyu Tang et al., which appeared in ICLR 2024. It is the synthetic copies that we can use to share across the network!
There we have it, the added privacy wrinkle and our differentially privacy approach means that we have to take the following steps to facilitate this data collaboration.
- Bob and Beth create privacy-safe synthetic copies of their private datasets
- Bob and Beth both build their respective QueryEngine’s over their synthetic datasets
- Bob and Beth both expose their QueryEngine behind a ContributorService
- Alex builds a NetworkQueryEngine that connects to Bob and Beth’s ContributorService’s
Creating differentially private synthetic copies of a private dataset
Fortunately, for step 0., we can make use of the DiffPrivateSimpleDataset pack.
python
from llama_index.core.llama_datasets.simple import LabelledSimpleDataset
from llama_index.packs.diff_private_simple_dataset.base import PromptBundle
from llama_index.packs.diff_private_simple_dataset import DiffPrivateSimpleDatasetPack
from llama_index.llms.openai import OpenAI
import tiktoken
# Beth uses `DiffPrivateSimpleDatasetPack` to generate synthetic copies
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
max_tokens=1,
logprobs=True,
top_logprobs=5, # OpenAI only allows for top 5 next token
) # as opposed to entire vocabulary
tokenizer = tiktoken.encoding_for_model("gpt-3.5-turbo-instruct")
beth_private_dataset: LabelledSimpleDataset = ... # a dataset that contains
# examples with two attributes
# `text` and `reference_label`
beth_synthetic_generator = DiffPrivateSimpleDatasetPack(
llm=llm,
tokenizer=tokenizer,
prompt_bundle=prompt_bundle, # params for preparing required prompts
simple_dataset=simple_dataset, # to generate the synthetic examples
)
beth_synthetic_dataset = await beth_synthetic_generator.arun(
size=3, # number of synthetic observations to create
sigma=0.5 # param that determines the level of privacy
)With the synthetic dataset in hand, Bob and Beth can apply the steps introduced in our previous post to build their privacy-safe QueryEngine. It’s worthwhile to mention here that as mentioned by the authors of the paper, the synthetic copies can be used as many times as one would like in a downstream task and it would incur no additional privacy cost! (This is due to the post-processing property of differential privacy.)
Example: Symptom2Disease
In this section of the blog post, we go over an actual example application of the privacy-safe networks over the Symptom2Disease dataset. This dataset consists of 1,200 examples each containing a “symptoms” description as well as the associated “disease” label — the dataset contains observations for 24 distinct disease labels. We split the dataset into two disjoint subsets, one for training and the other for testing. Moreover, we consider this original dataset to be private, requiring protective measures before being shared across a network.
Generate privacy-safe synthetic observations of Symptom2Disease
We use the training subset and apply the DiffPrivateSimpleDatasetPack on it in order to generate privacy-safe, synthetic observations. But in order to do so, we first need to turn the raw Symptom2Disease dataset into a LabelledSimpleDataset object.
python
import pandas as pd
from sklearn.model_selection import train_test_split
from llama_index.core.llama_dataset.simple import (
LabelledSimpleDataExample,
LabelledSimpleDataset,
)
from llama_index.core.llama_dataset.base import CreatedBy, CreatedByType
# load the Symptom2Disease.csv file
df = pd.read_csv("Symptom2Disease.csv")
train, test = train_test_split(df, test_size=0.2)
# create a LabelledSimpleDataset (which is what the pack works with)
examples = []
for index, row in df.iterrows():
example = LabelledSimpleDataExample(
reference_label=row["label"],
text=row["text"],
text_by=CreatedBy(type=CreatedByType.HUMAN),
)
examples.append(example)
simple_dataset = LabelledSimpleDataset(examples=examples)Now we can use the llama-pack to create our synthetic observations.
python
import llama_index.core.instrumentation as instrument
from llama_index.core.llama_dataset.simple import LabelledSimpleDataset
from llama_index.packs.diff_private_simple_dataset.base import PromptBundle
from llama_index.packs.diff_private_simple_dataset import DiffPrivateSimpleDatasetPack
from llama_index.llms.openai import OpenAI
import tiktoken
from .event_handler import DiffPrivacyEventHandler
import asyncio
import os
NUM_SPLITS = 3
T_MAX = 150
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
max_tokens=1,
logprobs=True,
top_logprobs=5,
)
tokenizer = tiktoken.encoding_for_model("gpt-3.5-turbo-instruct")
prompt_bundle = PromptBundle(
instruction=(
"You are a patient experiencing symptoms of a specific disease. "
"Given a label of disease type, generate the chosen type of symptoms accordingly.\n"
"Start your answer directly after 'Symptoms: '. Begin your answer with [RESULT].\n"
),
label_heading="Disease",
text_heading="Symptoms",
)
dp_simple_dataset_pack = DiffPrivateSimpleDatasetPack(
llm=llm,
tokenizer=tokenizer,
prompt_bundle=prompt_bundle,
simple_dataset=simple_dataset,
)
synthetic_dataset = await dp_simple_dataset_pack.arun(
sizes=3,
t_max=T_MAX,
sigma=1.5,
num_splits=NUM_SPLITS,
num_samples_per_split=8, # number of private observations to create a
) # synthetic obsevation
synthetic_dataset.save_json("synthetic_dataset.json")Create a network with two contributors
Next, we imagine that there are two contributors that each have their own set of Symptom2Disease datasets. In particular, we split the 24 categories of diseases into two disjoint sets and consider each Contributor to possess only one of the two sets. Note that we created the synthetic observations on the full training set, though we could have easily done this on the split datasets as well.
Now that we have the synthetic observations, we can follow a slightly modified version of steps 1. through 3. defined in the story of Alex, Bob and Beth. The modification here is that we’re using Retrievers instead of QueryEngine (the choice of Retriever or QueryEngine is completely up to the user).
Step 1: Contributor’s build their Retriever over their synthetic datasets.
python
import os
from llama_index.core import VectorStoreIndex
from llama_index.core.llama_dataset.simple import LabelledSimpleDataset
from llama_index.core.schema import TextNode
# load the synthetic dataset
synthetic_dataset = LabelledSimpleDataset.from_json(
"./data/contributor1_synthetic_dataset.json"
)
nodes = [
TextNode(text=el.text, metadata={"reference_label": el.reference_label})
for el in synthetic_dataset[:]
]
index = VectorStoreIndex(nodes=nodes)
similarity_top_k = int(os.environ.get("SIMILARITY_TOP_K"))
retriever = index.as_retriever(similarity_top_k=similarity_top_k)Step 2: Contributor’s expose their Retrievers behind a ContributorRetrieverService
python
from llama_index.networks.contributor.retriever.service import (
ContributorRetrieverService,
ContributorRetrieverServiceSettings,
)
settings = ContributorRetrieverServiceSettings() # loads from .env file
service = ContributorRetrieverService(config=settings, retriever=retriever)
app = service.appStep 3: Define the NetworkRetriever that connects to the ContributorRetrieverServices
python
from llama_index.networks.network.retriever import NetworkRetriever
from llama_index.networks.contributor.retriever import ContributorRetrieverClient
from llama_index.postprocessor.cohere_rerank import CohereRerank
# ContributorRetrieverClient's connect to the ContributorRetrieverService
contributors = [
ContributorRetrieverClient.from_config_file(
env_file=f"./client-env-files/.env.contributor_{ix}.client"
)
for ix in range(1, 3)
]
reranker = CohereRerank(top_n=5)
network_retriever = NetworkRetriever(
contributors=contributors, node_postprocessors=[reranker]
) With the NetworkRetriever established, we can retrieve synthetic observations from the two contributors data against a query.
python
related_records = network_retriever.aretrieve("Vomitting and nausea")
print(related_records) # contain symptoms/disease records that are similar to
# to the queried symptoms. Evaluating the NetworkRetriever
To evaluate the efficacy of the NetworkRetriever we make use of our test set in order to compute two traditional retrieval metrics, namely: hit rate and mean reciprocal rank.
- hit rate: a hit occurs if any of the retrieved nodes share the same disease label as the test query (symptoms). The hit rate then is the total number of hits divided by the size of the test set.
- mean reciprocal rank: similar to hit rate, but now we take into account the position of the first retrieved node that shares the same disease label as the test query. If there is no such retrieved node, then the reciprocal rank of the test is equal to 0. The mean reciprocal rank is then merely the average of all reciprocal ranks across the test set.
In addition to evaluating the NetworkRetriever we consider the two baselines that represent Retrieving only over the individual Contributor’s synthetic datasets.
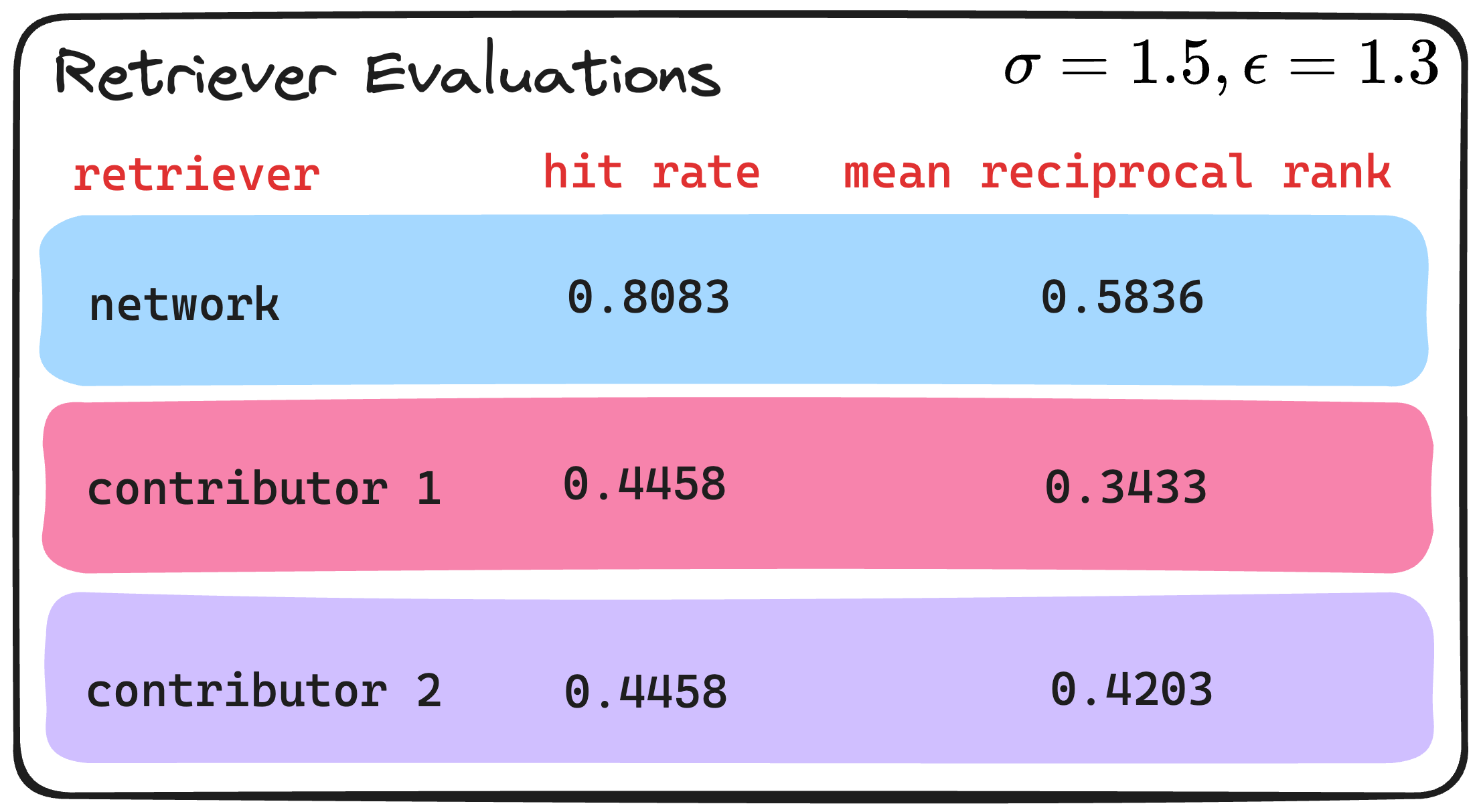
In the image above, we observe that the NetworkRetriever outperforms both the individual contributor Retriever’s in the test set. This shouldn’t be hard to grasp however since the network retriever has access to more data since it has access to both the Contributor’s synthetic observations—this is the point after all of a network!
Another important observation can be made upon inspection of these results. That is, the privacy-safe synthetic observations do indeed do the job of protecting privacy while still maintaining utility in the original dataset. This is often the concern when applying privacy measures such as differential privacy, where noise is incorporated to protect the data. Too much noise will provide high levels of privacy, but at the same time, may render the data useless in downstream tasks. From the table above, we see that at least for this example (though it does corroborate the results of the paper) that the synthetic observations still do match well with the test set, which are indeed real observations (i.e. not synthetically generated).
Finally, this level of privacy can be controlled via the noise parameter sigma . In the example above we used a sigma of 1.5, which for this dataset amounts to an epsilon (i.e., privacy-loss measure) value of 1.3. (Privacy loss levels between 0 and 1 are generally considered to be quite private.) Below, we share the evaluations that result from using a sigma of 0.5, which amounts to an epsilon of 15.9—higher values of epsilon or privacy-loss means less privacy.
python
# use the `DiffPrivacySimpleDatasetPack` to get the value of epsilon
epsilon = dp_simple_dataset_pack.sigma_to_eps(
sigma=0.5,
mechanism="gaussian",
size=3*24,
max_token_cnt=150 # number of max tokens to generate per synthetic example
)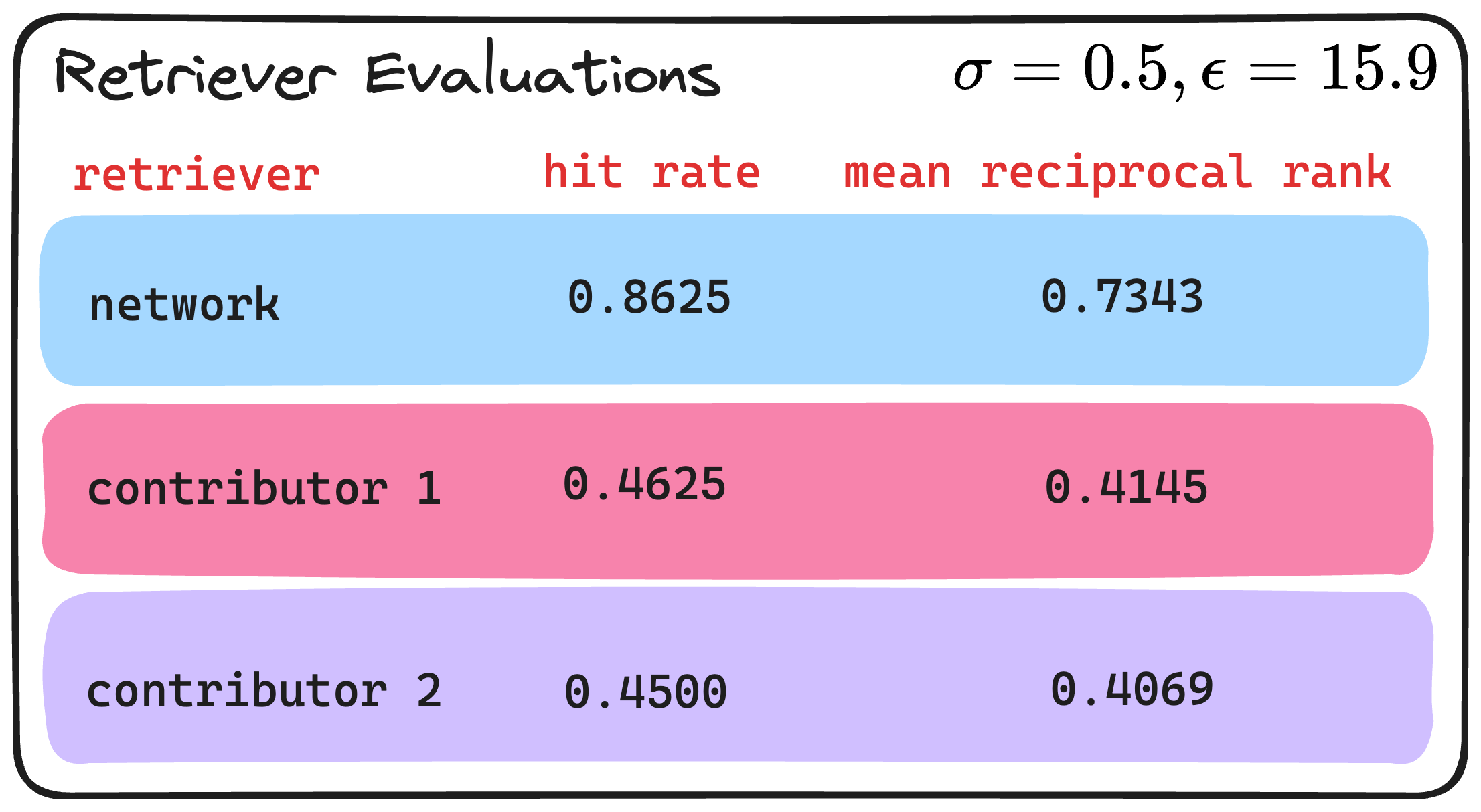
So we see after comparing the evaluation metrics with different levels of privacy that when we use the synthetic observations that have higher levels of privacy, we take a bit of a hit in the performance as seen in the decrease in both the hit rate and mean reciprocal rank. This indeed is an illustration of the privacy tradeoff. If we take a look at some of the examples from the synthetic datasets, we can perhaps gain insight as to why this may be happening.
python
# synthetic example epsilon = 1.3
{
"reference_label": "Psoriasis",
"text": "[RESULTS] red, scalloped patches on skin; itching and burning sensation; thick, pitted nails on fingers and toes; joint discomfort; swollen and stiff joints; cracked and painful skin on palms and feet",
"text_by": {
"model_name": "gpt-3.5-turbo-instruct",
"type": "ai"
}
},
# synthetic example epsilon = 15.9
{
"reference_label": "Migraine",
"text": "Intense headache, sensitivity to light and sound, nausea, vomiting, vision changes, and fatigue.",
"text_by": {
"model_name": "gpt-3.5-turbo-instruct",
"type": "ai"
}
},We can see that synthetic datasets with higher level of privacy are not as clean in terms of punctuation symbols in the text when compared to those with lower levels of privacy. This makes sense because the differential privacy algorithm adds noise to the mechanics of next-token generation. Thus, perturbing this process greatly has affect on the instruction-following capabilities of the LLM.
In summary
- We used differential privacy to create privacy-safe, synthetic observations in order to permit the data collaboration of private data that may not be otherwise possible.
- We demonstrated the benefits of the NetworkRetriever that has access to more data than what the individual Contributor Retriever may have access to.
- We demonstrated the affects of varying degrees of privacy on the synthetic observations, and by extension, the NetworkRetriever.
Learn more!
To delve deeper into the materials of this blog post, we share a few links below: