

We're excited to announce the launch of multimodal capabilities in LlamaParse, our enterprise RAG platform. This new feature enables developers to build fully multimodal RAG pipelines in minutes, over a broad range of document types - from investor slide decks to insurance contracts to research reports.
The Future of Document RAG is Multimodal
Many documents in the wild not only contain text, but also complex visual elements like images, charts, and diagrams. Traditional RAG systems tend to focus solely on text. This leads to decreased document understanding, lower quality responses, and increased hallucination rates.
Multimodal LLMs and RAG systems can address these complexities - multimodal LLMs like Pixtral, Sonnet 3.5, and GPT-4o are increasingly better at document understanding. Our customers have asked us for these capabilities for advanced knowledge assistant use cases, like generating structured reports with both charts and images.
Yet these systems are complex to setup and productionize. An ideal multimodal pipeline not only extracts images into text, but also stores native image chunks that are indexed along with text chunks. This allows the LLM to take in both retrieved text and images as input during the synthesis phase. Doing this well requires clever algorithms around parsing, indexing, and retrieval and infrastructure to serve both text and images. We have notebooks in both the core LlamaIndex repo and LlamaParse to help you build multimodal RAG setups, but they contain a lot of code, are optimized for a small number of local files, and avoid system-level complexities of how to scale this indexing to production.
LlamaParse’s new multimodal feature let you build a full multimodal RAG pipeline in minutes. Index both text and image chunks. Retrieve both text and images and provide those as sources in the response.
LlamaParse Multimodal Feature Overview
At a high-level, our multimodal feature lets you build a RAG pipeline that can index and retrieve both text and image chunks. You can easily validate your pipeline through our chat interface (see below images), or plug it into your application through an API.


Key Benefits
- Reduced Time to Value: Activating multimodal indexing is as simple as clicking a toggle when creating a RAG index.
- High Performance over Unstructured Data: Achieve superior retrieval quality across text and images in complex documents like PDFs and PowerPoints.
- Comprehensive Understanding: Leverage both textual and visual information for more accurate and context-aware AI responses.
- Simplified Data Integration: Easily incorporate diverse data types into your RAG pipeline without extensive preprocessing.
Real-World Example: Analyzing Corporate Presentations
To demonstrate the effectiveness of multimodal RAG, let's consider a real-world example using a ConocoPhillips investor presentation. Let's walk through the process:
1. Create a Multimodal Index
First, create a new LlamaParse Index and enable the Multi-Modal Indexing option. This feature automatically generates and stores page screenshots alongside the extracted text, allowing for both text and image retrieval.

2. Integrate the Index into Your Code
Once your index is created, you can easily integrate it into your Python code:
python
from llama_index.indices.managed.llama_cloud import LlamaParseIndex
index = LlamaParseIndex(
name="<index_name>",
project_name="<project_name>",
organization_id="...",
api_key="llx-..."
)3. Set Up Multimodal Retrieval
To enable multimodal retrieval, create a retriever that can handle both text and image nodes:
python
retriever = index.as_retriever(retrieve_image_nodes=True)4. Build a Custom Multimodal Query Engine
To fully leverage the power of multimodal RAG, we recommend creating a custom query engine that can take full advantage of this multimodal retriever. It will separate the text and image nodes from the retriever, and feed them into a multimodal model through our multimodal LLM abstraction:
python
from llama_index.core.query_engine import CustomQueryEngine
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
class MultimodalQueryEngine(CustomQueryEngine):
"""Custom multimodal Query Engine.
Takes in a retriever to retrieve a set of document nodes.
Also takes in a prompt template and multimodal model.
"""
qa_prompt: PromptTemplate
retriever: BaseRetriever
multi_modal_llm: OpenAIMultiModal
def __init__(self, qa_prompt: Optional[PromptTemplate] = None, **kwargs) -> None:
"""Initialize."""
super().__init__(qa_prompt=qa_prompt or QA_PROMPT, **kwargs)
def custom_query(self, query_str: str):
# retrieve text nodes
nodes = self.retriever.retrieve(query_str)
img_nodes = [n for n in nodes if isinstance(n.node, ImageNode)]
text_nodes = [n for n in nodes if isinstance(n.node, TextNode)]
# create context string from text nodes, dump into the prompt
context_str = "\\n\\n".join(
[r.get_content(metadata_mode=MetadataMode.LLM) for r in nodes]
)
fmt_prompt = self.qa_prompt.format(context_str=context_str, query_str=query_str)
# synthesize an answer from formatted text and images
llm_response = self.multi_modal_llm.complete(
prompt=fmt_prompt,
image_documents=[n.node for n in img_nodes],
)
return Response(
response=str(llm_response),
source_nodes=nodes,
metadata={"text_nodes": text_nodes, "image_nodes": img_nodes},
)
return response
query_engine = MultimodalQueryEngine(
retriever=retriever, multi_modal_llm=gpt_4o
)
Note: We’re hoping to make this experience a one-liner - stay tuned!
5. Query Your Multimodal Index
Now you're ready to query your multimodal index and receive responses that incorporate both textual and visual information:
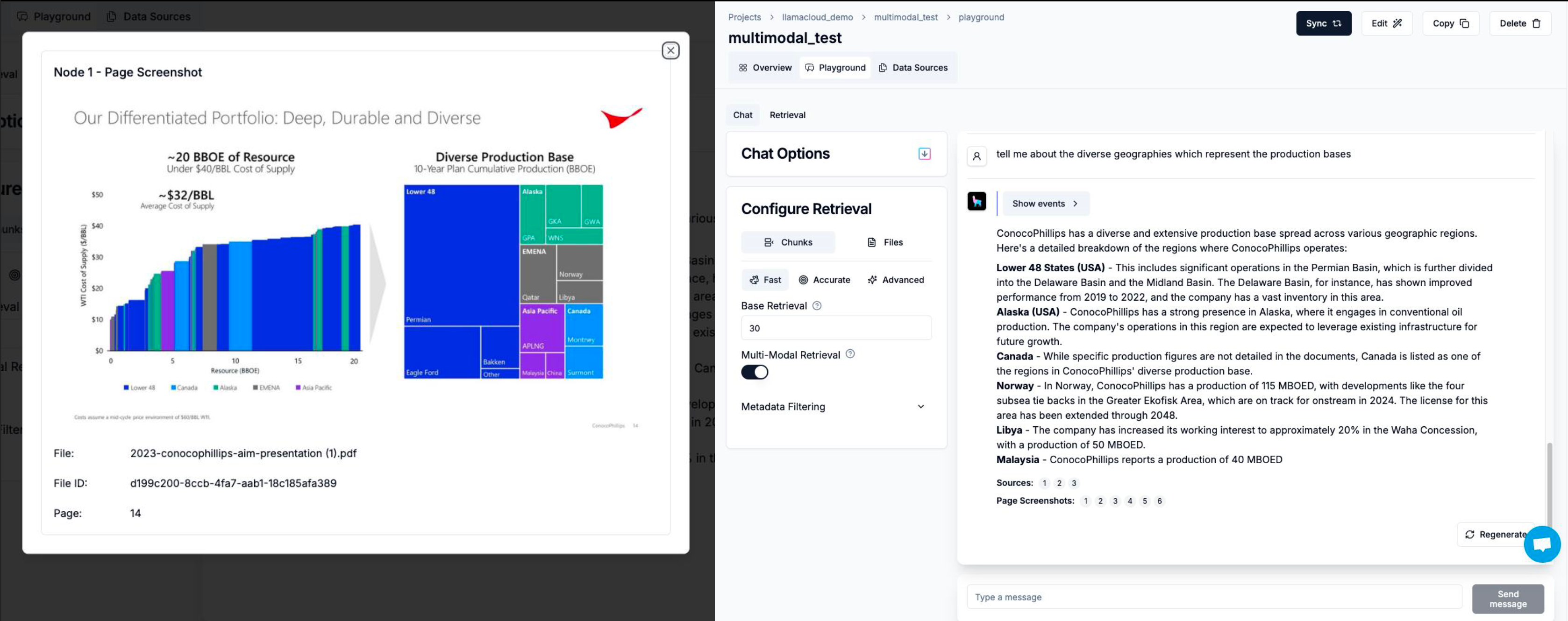
response = query_engine.query("Tell me about the diverse geographies which represent the production bases")
print(str(response))
When asked about the company's diverse production bases, our multimodal RAG system provides a comprehensive response:
"The diverse geographies representing the production bases for ConocoPhillips include:
- Lower 48 (United States)
- Canada
- Alaska
- EMENA (Europe, Middle East, and North Africa)
- Asia Pacific
This information is derived from both the text and images provided in the presentation, showcasing how our system integrates multiple data types to provide a complete answer."
Getting Started
Point LlamaParse at your bucket of unstructured files; let us handle the rest so that you can focus on application logic. Sign up for a LlamaParse account at https://cloud.llamaindex.ai/ - we’re letting lots of people off the waitlist.
We have a great reference notebook here to help you get started.
If you're looking to adopt LlamaParse in an enterprise setting, come talk to us.