Over the last few weeks, there have been a lot of conversations (here, here and here for example) about using Large Vision Models (LVMs) to parse documents. Those conversations struck a chord with us.
We’ve long been of the opinion that document parsing has always been a huge pain for developers, and has never been solved in a definitive way. We’re determined to do something about it. In 2023, we realized that Large Language Models (LLMs) could be used to parse documents, so we started building LlamaParse. Our thesis is simple:
- First, we can use traditional techniques to extract text & screenshots from documents
- Then we can feed this to an LLM or LVM and let the model reconstruct the document into a structured form (we use Markdown) to be able to correctly extract tables, titles, etc.
At first we struggled to get acceptable results due to models hallucinating and/or missing content. But with iteration over time our approach proved to be more generalizable than previous attempts at building document parsers, which utilized multiple models trained to extract different parts of documents, leading to overly complex systems. Our approach also performs better on unusual and unexpected edge cases
Since we built it, LlamaParse has been used to parse hundred of millions of documents, and is trusted by tens of thousands of developers for their parsing needs.
Changes in LlamaParse
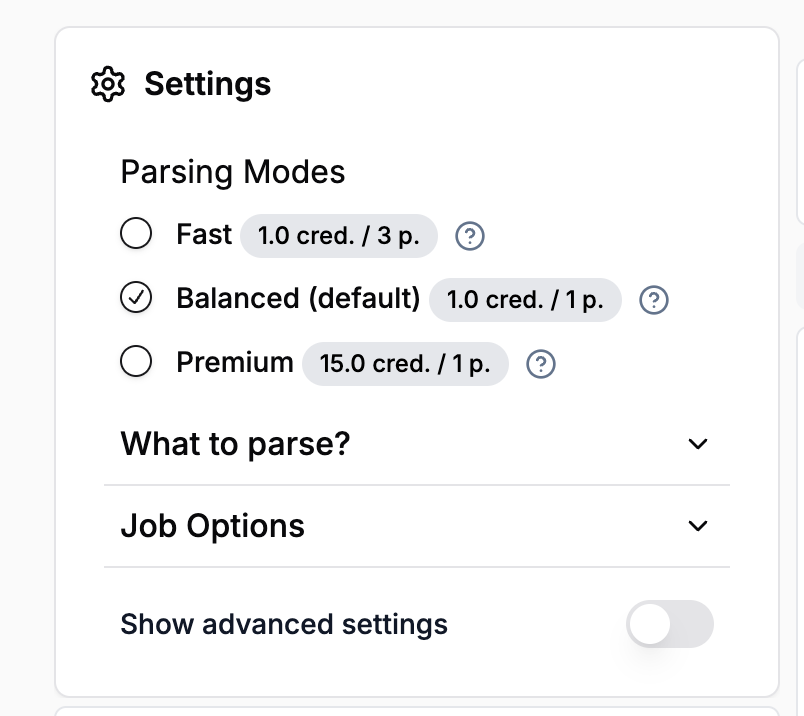
To be more transparent about how LlamaParse works, we’ve decided to rename our parsing modes. We now offer three simplified choices:
- Fast — the cheapest and fastest parsing
- Balanced — the best cost / speed / accuracy trade-off
- Premium — always be directed to our most accurate parsing technique

But for those who want more control, we will let you specify the way you want to parse the document. These options are described below:

Parse without AI
Sometimes, the structure of the document is not that important. In this case we output the raw text out of the document in the unstructured format LLMs understand the best: laid-out text.
We try to keep the text spatially laid out in the same way as the original document. Our extractor at this level has dozens of great features, including:
- Works with hundreds of file formats, and
- Extracts all images contained in a document
- Uses OCR to transcribe all content that is not machine-readable text in the document
- Fixes common issues such as corrupt fonts, corrupt documents
- And many more!
Parse with LLM
In this mode, we first use our internal parser to extract text, then feed it to a Large Language Model to reconstruct the document structure. We do this as efficiently as possible, while performing error correction on the LLM output to improve results.
Parse with LVM
This method uses our internal parser to take screenshots of documents, and feeds those to an LVM. We currently support multiple external LVM model vendors such as OpenAI, Azure, Anthropic and Google and will be adding more in the future. We allow you to provide your own API key if you wish, and only charge a nominal fee for handling the parsing.
Parse with Agent
In our most advanced mode, we use an agentic workflow to parse the provided document to the best of our ability. This includes using both LVMs and LLMs when needed. This gives us the highest accuracy possible, although this requires more time and is more costly.
Other changes
With this release, we have also deprecated our old “parsing instructions” system, and replaced it with a clearer combination of system prompts and user prompts, which give you more control over the way your documents are parsed.
Going forward
We are working hard to further improve LlamaParse. We’re committed to building a faster, cheaper, and more accurate parsing stack, and we are hopeful that we will get to a place where fighting with your parsing tool will be a thing of the past. To do so, we will keep pushing the envelope: integrating and develop new models, trying to solve this problem once and for all.
While most tools today focus on parsing documents page by page, we believe that documents should be looked at as a whole. We took our first step in this direction with what we called “continuous mode” (now called “Parse with LLM”) and are working hard on improving our whole-document parsing capabilities. It should not matter if a table is split between multiple pages, and the hierarchy of titles should be maintained. We will add options to consider the whole document (and not just pages) in all our parsing modes.
Currently we are only offer the ability to supply your own model for our LVM mode. We will soon start adding this ability to our other modes, starting with an Agent-based system built on Gemini 2.0. We expect to release this later this week, further improving our current Premium mode.
You can try LlamaParse for free today! Also, if you are interested in helping us tackle this challenge, we are hiring engineers in the LlamaParse team.