Introduction:
In the world of IT and Software Development, knowledge transfer (KT) stands out as a big challenge. Whether it’s new hires trying to understand their roles, folks on their notice periods aiming for a smooth handover, or the daily tasks of developers and product specialists adapting to ever-changing projects — the KT process often leads to stress and worry.
This gets more complicated with information spread out everywhere, the mix of new and old tech, and the fast pace of IT and Software Development projects. In this situation, broken bits of knowledge become the norm, causing delays, misunderstandings, and making learning harder.
But amidst these challenges, might there be a beacon of optimism shining through?
Vibhav and I have developed a system that seamlessly organizes KT sessions. By leveraging personal images, we generate video explanations that are paired with individual code snippets, making the code far more comprehensible. Our innovative approach was recognized when we secured the First Prize at the Google Cloud, Searce, and LifeSight hackathon. With the combined strengths of LlamaIndex and D-ID, our aim is not just to consolidate information but also to simplify tasks and elevate the KT process. In doing so, we’re transforming a daunting industry challenge into a straightforward and manageable endeavor.
Want to see how LlamaIndex plays a key role in this change?
Let’s dive in together!
Solution:
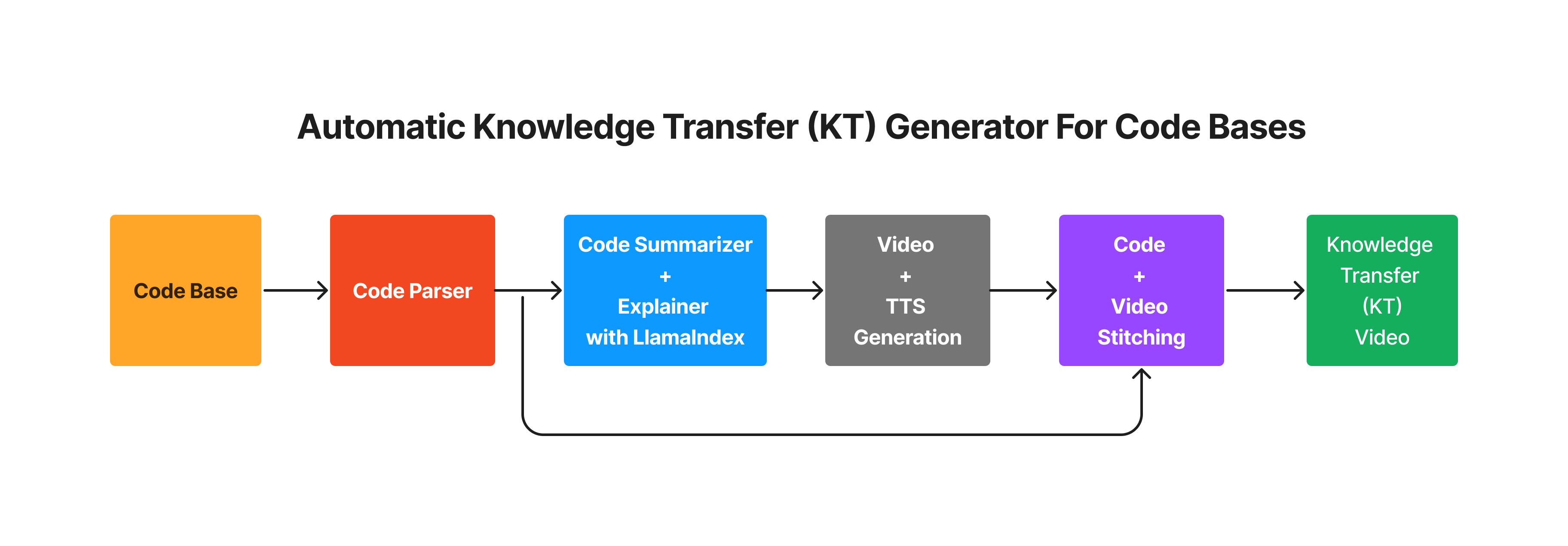
The solution has four stages:
Code Parsing:
- Break down the code base into individual code snippets or blocks.
Summary and Explanation Generation with LlamaIndex:
- Produce a comprehensive summary of the entire code base.
- Create detailed explanations for each individual code block using LlamaIndex.
Video Creation with D-ID:
- Generate videos using text-to-speech capabilities provided by D-ID.
Video-Code Integration:
- Seamlessly stitch together the individual code blocks with their corresponding generated videos.
Let’s dive into each stage in detail.

1. Code Parsing: Breaking Down the Code

Understanding a code base starts with a high-level summary, but the true depth lies in individual snippets or blocks. However, using entire code bases for explanations can overwhelm language models like LLMs, causing them to either exceed token limits or miss key details.
Our approach is simple yet efficient: break the code into digestible sections
like import statements, classes, initializer functions, and methods without
losing the code’s flow. This segmentation is done through a dependency graph
approach, utilizing Python’s
ast library. By analyzing the code's structure, we can extract
classes, their docstrings, initializers, and other methods. This method not
only captures the essence of each segment but is also flexible, allowing for
further rules to extract additional code components.
The code_parser class embodies this strategy. It navigates the
code, distinguishing module-level functions from class-nested ones, and
arranges them systematically. The result? A granular yet comprehensive view of
the code, paving the way for precise and context-rich explanations.
2. Summary and Explanation Generation with LlamaIndex
Producing a Comprehensive Summary:
The initial step in understanding a code base is to grasp its overall essence. This is achieved by generating a concise summary that gives a bird’s-eye view of the entire code. LlamaIndex’s SummaryIndex has been tailored for this exact task. In SummaryIndex, each block of code is treated as a node. By inputting the structured blocks obtained from our code parsing phase into SummaryIndex, we can produce a comprehensive snapshot that serves as a summary of the entire code base.

Detailed Explanations for Individual Code Blocks:
With a general understanding established, the next step is to delve into the
finer details. Starting from import statements, progressing to functions, and
eventually diving into classes and initializer functions, every block gets its
due attention. Here, LlamaIndex’s
accumulateresponse mode is a valuable asset, providing in-depth
explanations for each block.
However, a challenge arises. While
accumulate provides in-depth insights into each block, it can
occasionally miss the broader context offered by preceding blocks. To address
this limitation, we’ve adopted a two-pronged approach. As depicted in the
subsequent architecture, we employ two SummaryIndices for this endeavor.
- We utilize the first SummaryIndex to generate a concise summary for each block, treating each block as a Node in SummaryIndex.
-
For the second SummaaryIndex in the stack, we feed the summarized context
from one node into the next. This ensures every node benefits from the
context of its predecessor. We then harness the
accumulatemode to provide detailed explanations, making certain that every segment of the code is explained comprehensively, preserving the broader perspective. The outcome? A deep, contextually rich interpretation of each code section.
Note: We utilized Google’s PaLM API in conjunction with LlamaIndex to generate summaries and explanations. Alternatively, models like GPT-3.5, GPT-4, or other LLM’s can be employed for this purpose.

3. Video Creation with D-ID:
After carefully crafting summaries and detailed explanations for each code block, it’s essential to convey this information in a captivating and accessible manner. Videos, given their dynamic appeal, have the power to make intricate code explanations clearer and more engaging. This is where D-ID comes into play.
With the prowess of D-ID’s cutting-edge technology, we’re able to create realistic videos where avatars — whether they’re of us or another chosen figure — articulate each code block. Now, what brings these avatars to life? The answer lies in Microsoft’s text-to-speech synthesizer. This tool takes our detailed textual explanations and transforms them into natural, fluent speech. Thus, with D-ID, we’re not just generating video but also integrating audio, culminating in a comprehensive and fluid video explanation.
To see this in action, let’s take a look at a sample output.

4. Video-Code Integration:
After generating insightful videos with avatars elucidating the code and having our individual code snippets ready, the next crucial step is to marry these two elements. This fusion ensures that viewers receive an immersive visual experience, where they can simultaneously watch the explanation and observe the related code.
To achieve this, we employed the
carbon library, which transforms our code snippets into visually
appealing images. These images, when presented side-by-side with our
explanatory videos, offer a clearer understanding of the code in focus. The
final touch is added with the moviepy library, which seamlessly
stitches the video and code images together, ensuring a smooth and integrated
visual flow. Below, you'll find a sample illustrating this compelling
combination.

Final Automatic Knowledge Transfer (KT) Generated Video
Following our detailed process, we’ve crafted a KT video where Jerry explains the ChatEngine code base of LlamaIndex. Watch the video below to see it all come together!
Code Repository: https://github.com/ravi03071991/KT_Generator
Conclusion
Through this post, we’ve showcased the transformative potential of LlamaIndex in creating Knowledge Transfer (KT) Videos for code bases. It’s genuinely remarkable to envision the advancements we’re making in this space. The methodology we’ve adopted is language-neutral, allowing flexibility in adapting to various code bases. With some tweaks to the code parsing phase, we believe it’s feasible to scale this to cover expansive code repositories within organizations. Imagine a platform akin to YouTube, perhaps KodeTube(KT), where an organization’s entire codebase is cataloged through explanatory videos. The horizon is bright with the opportunities LlamaIndex brings, and we’re thrilled about the journey ahead.