

Today we introduce RAGs, a Streamlit app that allows you to create and customize your own RAG pipeline and then use it over your own data — all with natural language! This means you can now setup a “ChatGPT over your data” without needing to code.
Setup and query a RAG pipeline in three simple steps:
- Easy Task Description: Simply describe your task (like “load this web page”) and define the parameters for your RAG systems (like retrieving a certain number of documents).
- Configurable Settings: Dive into the configuration view to see and alter the automatically generated parameters, such as top-k retrieval, summarization options, and more.
- Interactive RAG Agent: Once set up, you can interact with your RAG agent, asking questions and getting responses based on your data.
The app is designed for both less-technical and technical users: if you’re less-technical, you still need to clone the repo and pip install it, but you don’t need to worry about what’s going on under the hood. On the other hand, if you are technical, you can inspect and customize specific parameter settings (e.g. top-k, data).
Detailed Overview
The app contains the following sections, corresponding to the steps listed above.
[1] 🏠 Home Page
This is the section where you build a RAG pipeline by instructing the “builder agent”. Typically to setup a RAG pipeline you need the following components:
- Describe the dataset: Currently we support either a single local file or a web page. We’re open to suggestions here!
- Define the Task: Your description here initializes the “system prompt” of the LLM powering the RAG pipeline.
- Set RAG Parameters: Configure typical RAG setup parameters, such as top-k retrieval, chunk size, and summarization options. See below for the full list of parameters.
[2] ⚙️ RAG Config: Tailoring Your Experience
After setting up the basics, you move to the RAG Config section. This part of the app provides an intuitive UI where you can:
- View Generated Parameters: The builder agent suggests parameters based on your initial setup.
- Edit and Customize: You have complete freedom to tweak these settings, ensuring the RAG agent behaves exactly as you need.
- Update the Agent: Any changes you make can be instantly applied by hitting the “Update Agent” button.
This is the current set of parameters:
- System Prompt
- Include Summarization: whether to also add a summarization tool (instead of only doing top-k retrieval.)
- Top-K
- Chunk Size
- Embed Model
- LLM
[3] 🤖 Generated RAG Agent: Interacting with Your Data
The final piece of the RAGs experience is the Generated RAG Agent section. Here’s what you can expect:
- Interactive Chatbot Interface: Just like ChatGPT, engage in conversations with your RAG agent.
- Data-Driven Responses: The agent utilizes top-k vector search and optional summarization tools to answer your queries based on the underlying data.
- Seamless Integration: The agent dynamically picks the right tools to fulfill your queries, ensuring a smooth and intelligent interaction with your dataset.
Architecture
We’ll cover the architecture in more detail in followups. At a high-level:
- We have a builder agent equipped with builder tools — tools necessary to construct a RAG pipeline.
- The builder agent will use these tools to set the configuration state. At the end of the initial conversational flow these parameters are then used to initialize the RAG agent.
Let’s Walk through an Example!
Installation and Setup
Getting RAGs up and running is straightforward:
- Clone the RAGs project and navigate to the
ragsproject folder: https://github.com/run-llama/rags - Install the required packages:
pip install -r requirements.txt3. Launch the app:
streamlit run 1_🏠_Home.pyBuild the RAG Agent
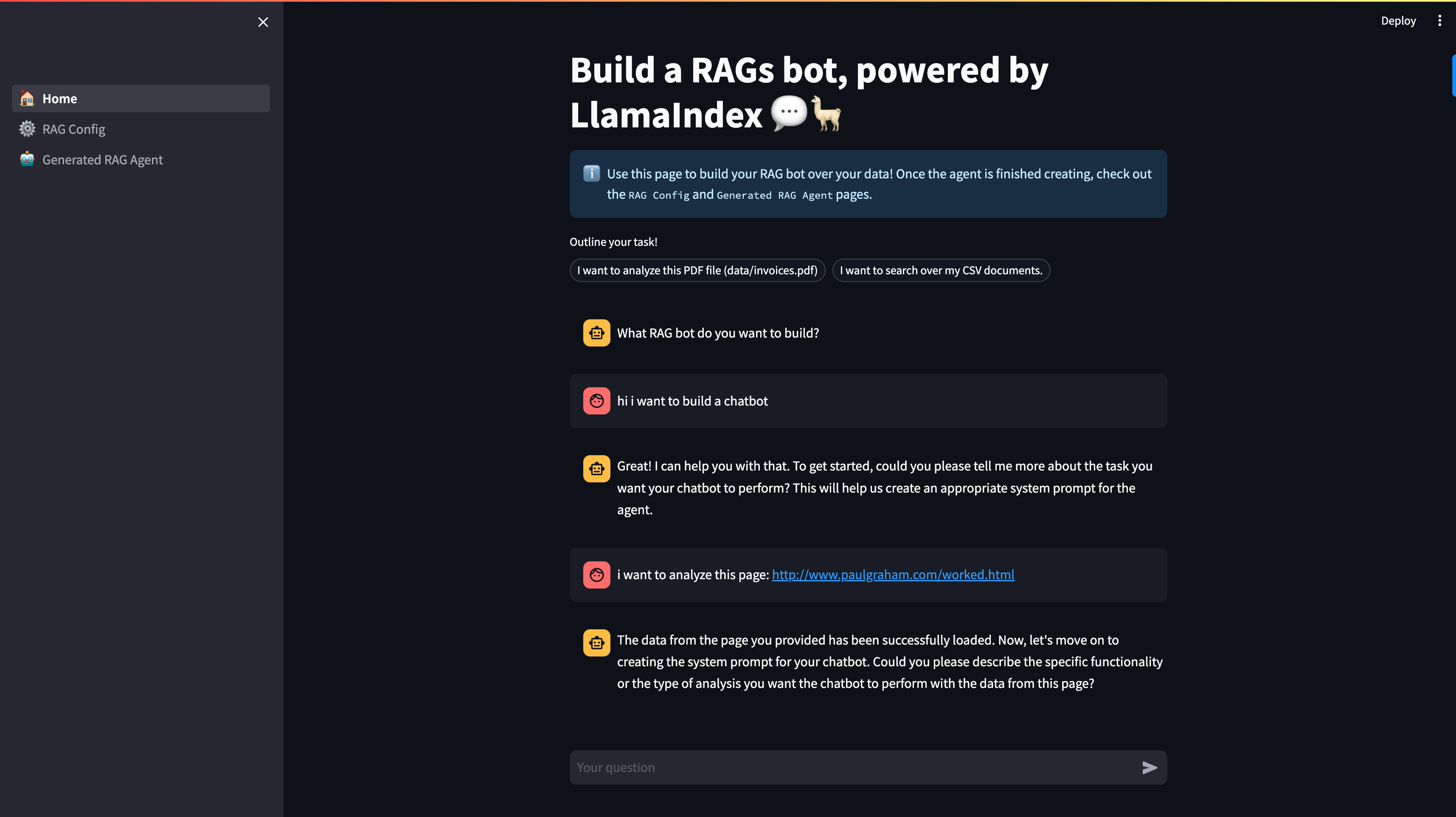
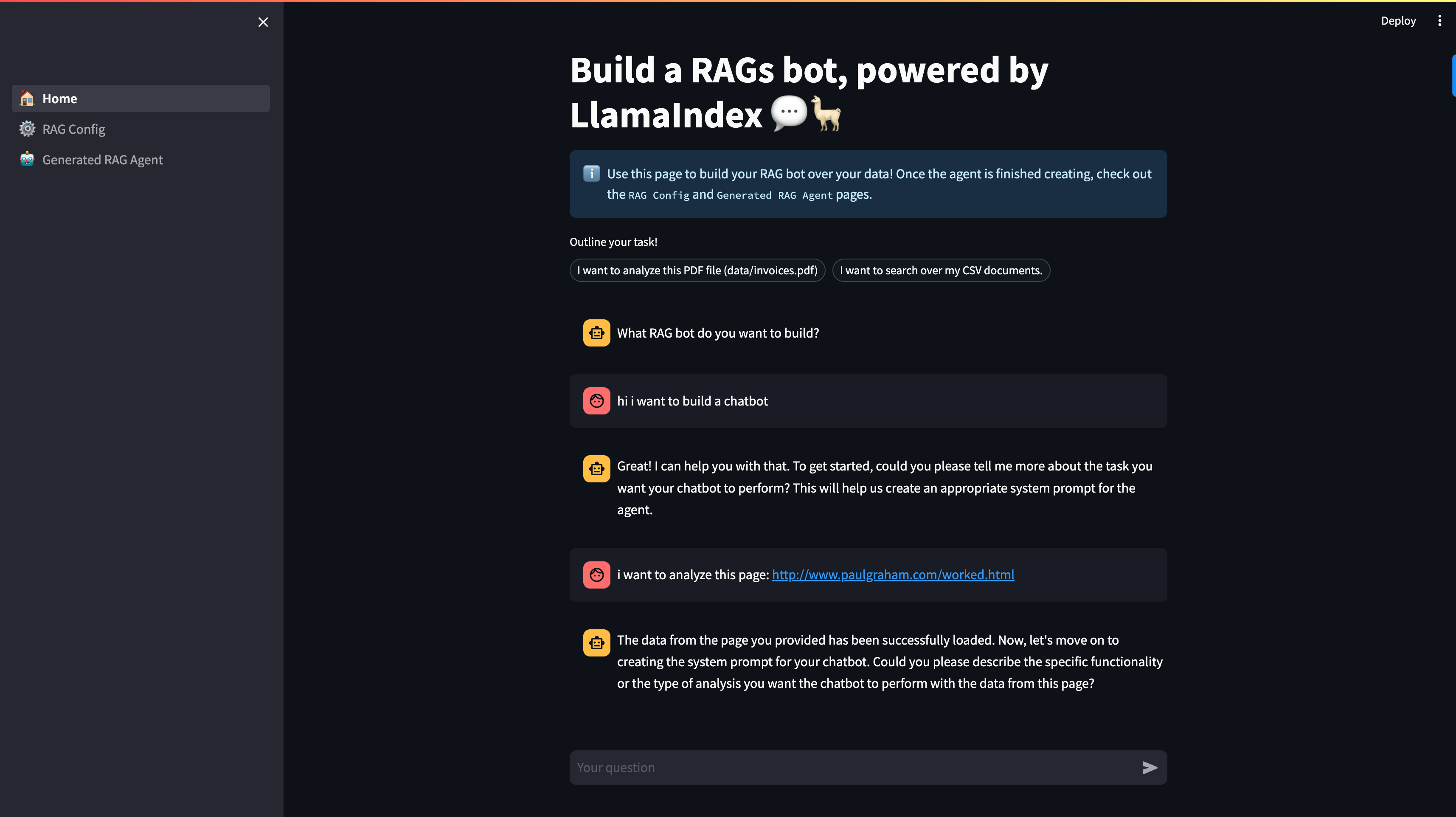
In the below diagram we show a sequence of commands to “build” a RAG pipeline.
- Say that you want to build a chatbot
- Define the dataset (here it’s a web page, can also be a local file)
- Define the task
- Define params (chunk size 512, top-k = 3)
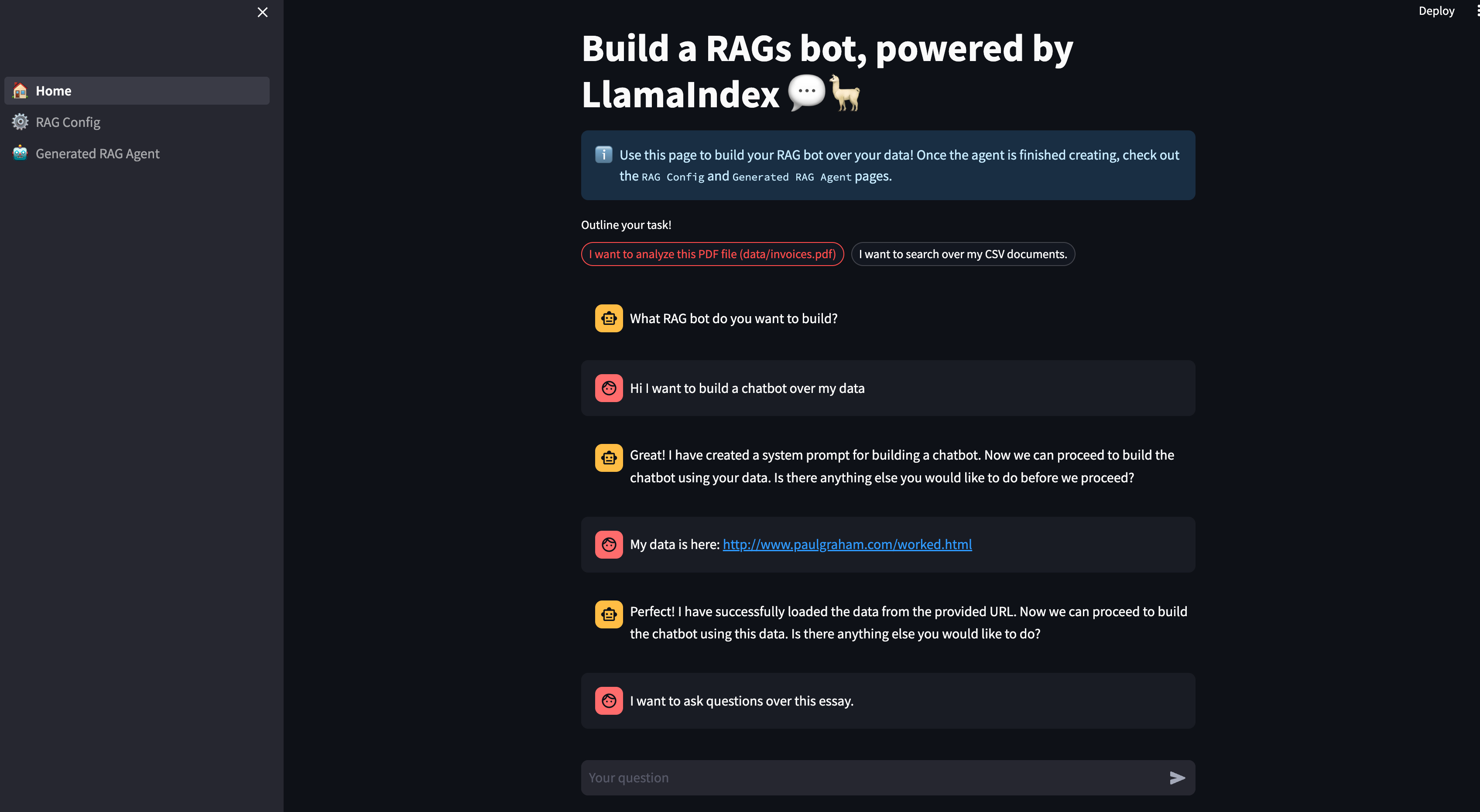
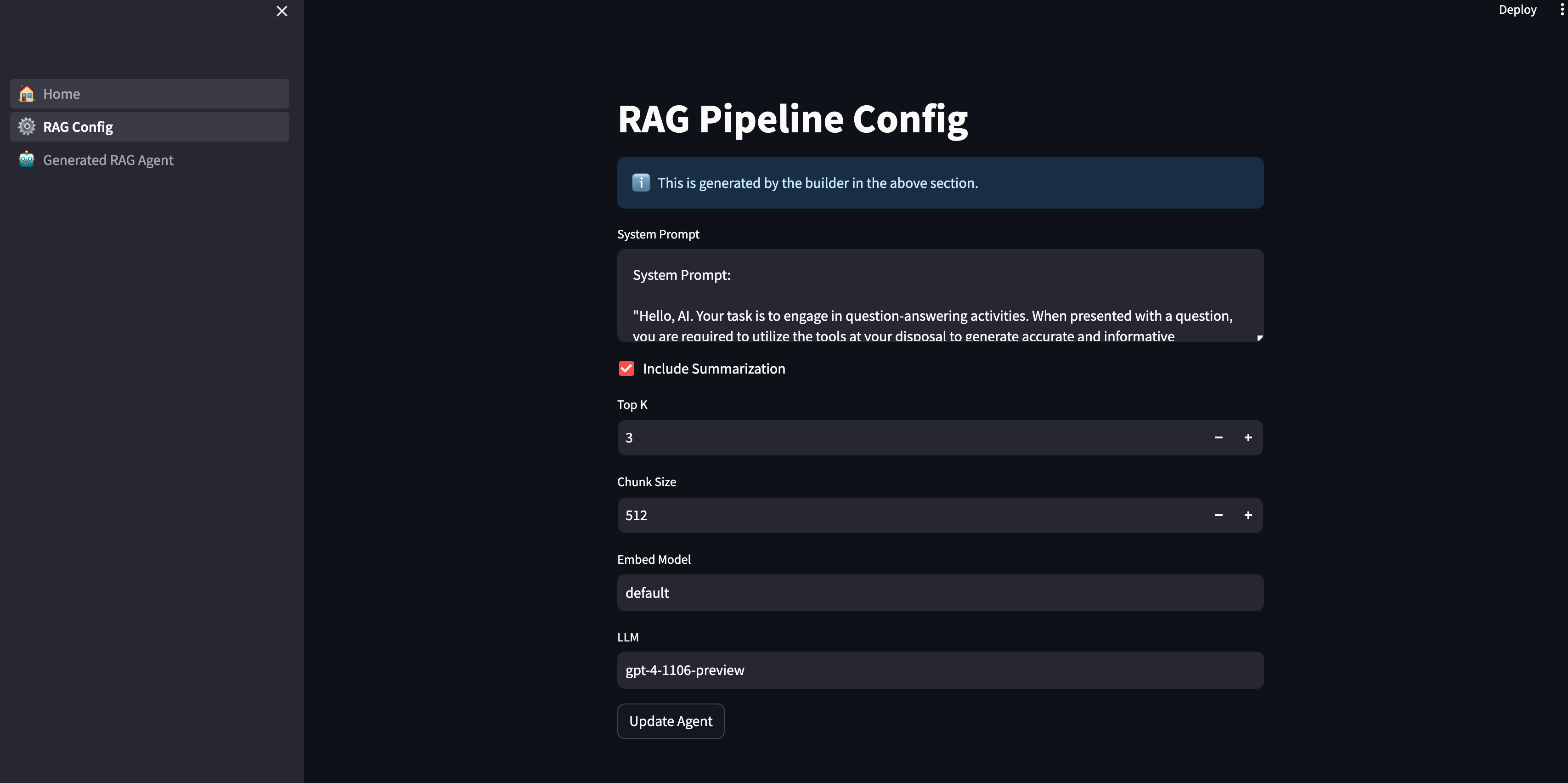
View the Configuration
We can see the generated configuration in the below page, and view/edit them as necessary!
E.g. we can set include_summarization to True.
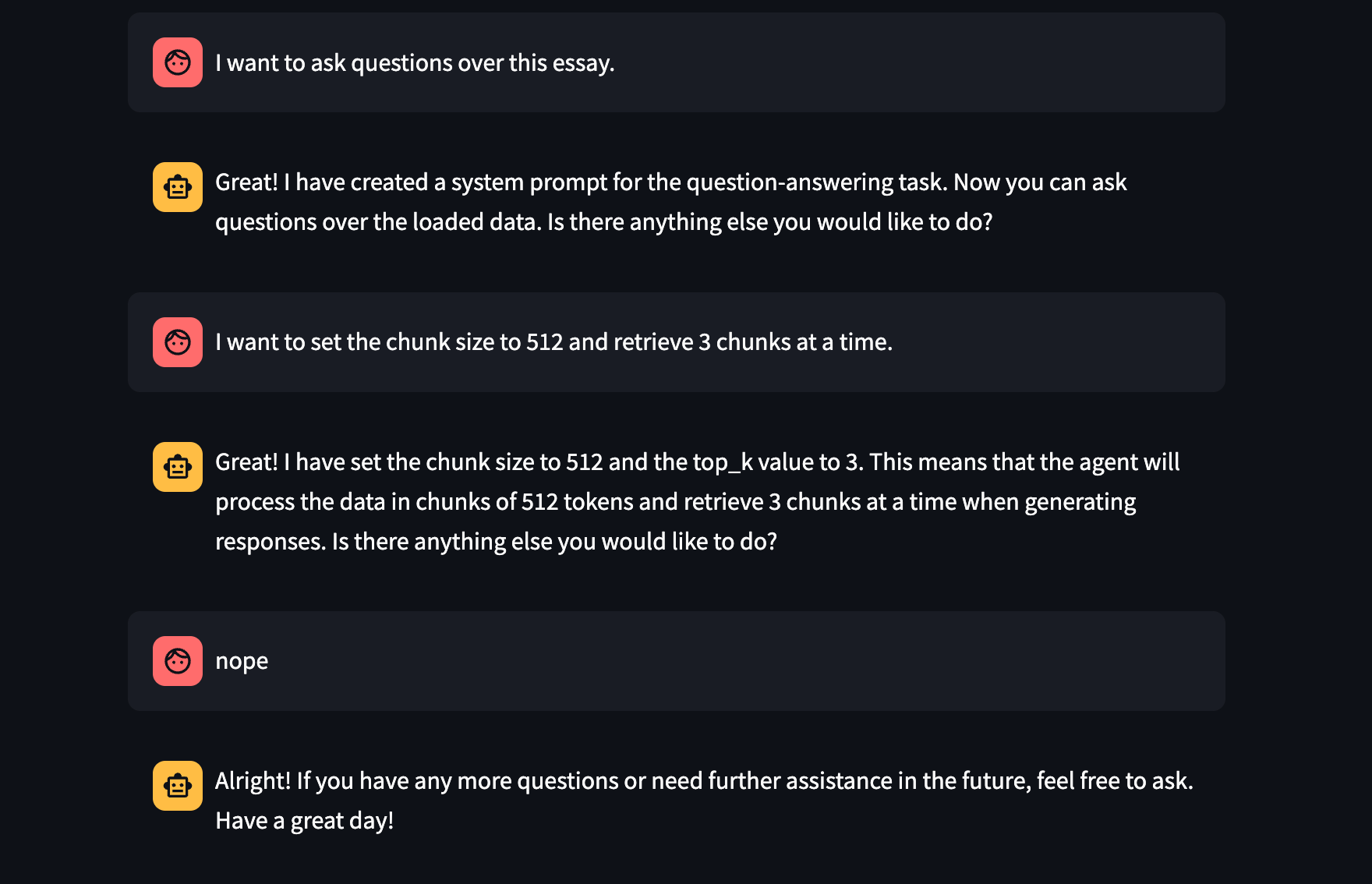
Test It Out
Now we can ask questions! We can ask both specific questions as well as summarization questions.
This uses both the vector search and summarization tools to answer the requisite questions.


Conclusion
In general RAGs is an initial take towards a world where LLM applications are built by and powered by natural language. Let us know your thoughts and feedback!
Resources
RAGs repo: https://github.com/run-llama/rags
Contributions and Support
We’re committed to improving and expanding RAGs. If you encounter any issues or have suggestions, feel free to file a Github issue or join our Discord community.


