
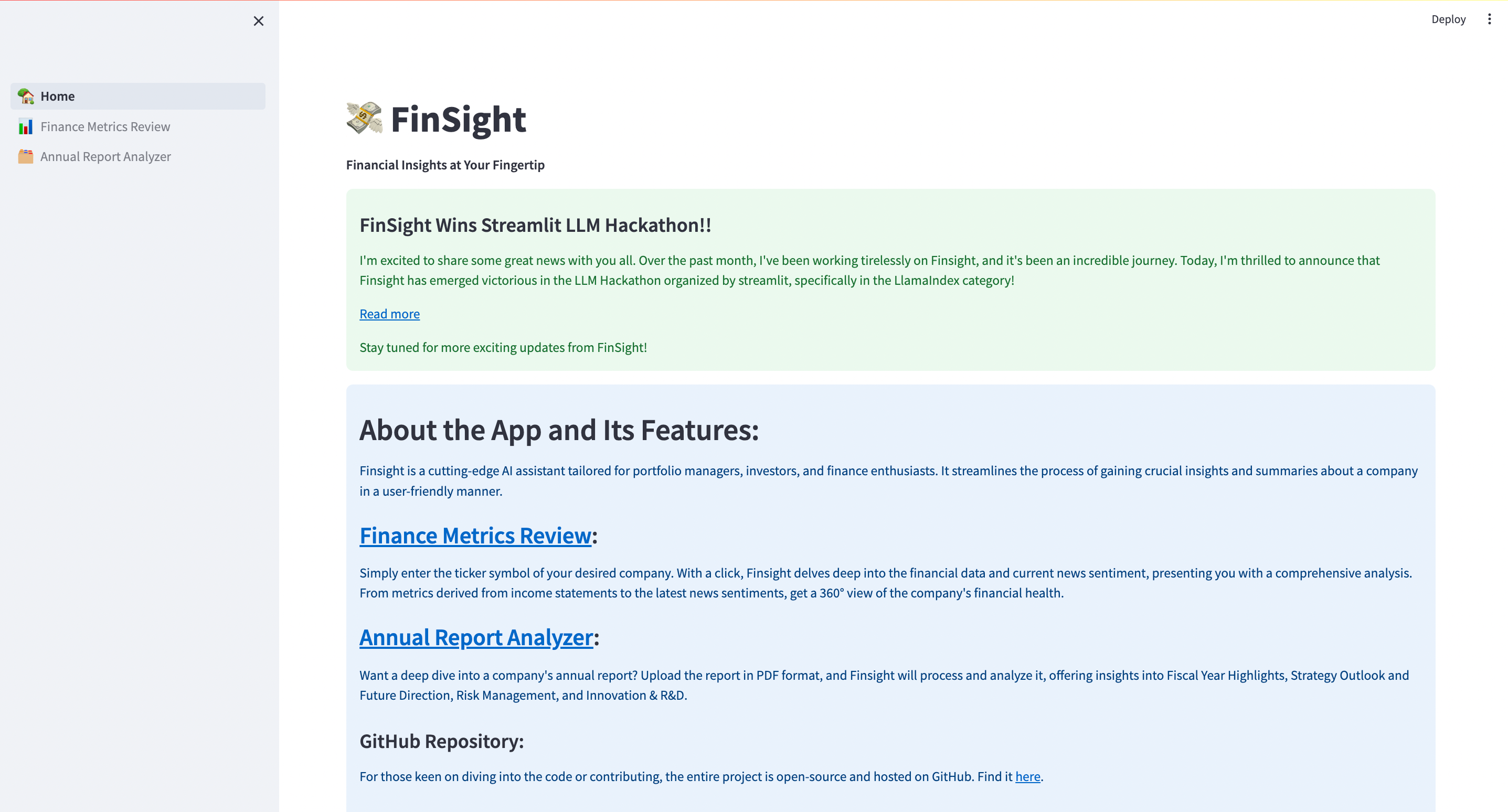
In this article, we’ll dive deep into the world of LLM app development and take a closer look at my journey of building the Streamlit LLM hackathon-winning app FinSight — Financial Insights At Your Fingertips. This article covers the entire process from ideation to execution, along with code snippets and snapshots.
Introduction
A use case for LLMs in finance
One fascinating use case for LLMs in finance is to use them on company annual reports (10-K form). These reports are publicly available information that pretty much every portfolio manager, financial analyst, and shareholder uses regularly to make informed decisions.
However reading, understanding, and assessing these reports, especially for multiple companies can be tedious and time-consuming. Hence, using LLMs on annual reports to extract insights and summarize would solve a lot of problems and save valuable time.
When the Streamlit LLM Hackathon was, announced I thought this was the best time to explore this idea. And that’s how FinSight came into existence.
How does FinSight work?

FinSight has two main features called Annual Report Analyzer and Finance Metric Review, but for this blog post, we will be concentrating on the former.
Annual Report Analyzer is a RAG(Retrieval Augmented Generation) based feature, which means that the LLM will be generating insights based on the information in a knowledge base (which in this case is a company’s annual report). Here’s how it works behind the scenes:

While this is a basic representation of the architecture, we will be doing a deep dive into the importance of each of these components and how they work.
Setup
In case you want to refer the code to the app: Repo
We will use LlamaIndex to build the knowledge base and to query it using an LLM (gpt-4 is the best suited). LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models.
For the front end, Streamlit is the most convenient tool to build and share web apps.
- Clone Repository
git clone https://github.com/vishwasg217/finsight.git
cd finsight
2. Setup Virtual Environment
# For macOS and Linux:
python3 -m venv venv
# For Windows:
python -m venv venv
3. Activate Virtual Environment
# For macOS and Linux:
source venv/bin/activate
# For Windows:
.\venv\Scripts\activate
4. Install Required Dependencies:
pip install -r requirements.txt
5. Set up the Environment Variables:
# create directory
mkdir .streamlit
# create toml file
touch .streamlit/secrets.toml
You can get your API keys here: AlphaVantage, OpenAI,
# Add the following API keys
av_api_key = "ALPHA_VANTAGE API KEY"
openai_api_key = "OPEN AI API KEY"
Document Loading, Indexing, and Storage
Although LlamaIndex has its own set of data connectors to read PDFs, we still
need to write a small function
process_pdf()to load the PDFs since we are doing it through
Streamlit.
from pypdf import PdfReader
from llama_index.schema import Document
def process_pdf(pdf):
file = PdfReader(pdf)
text = ""
for page in file.pages:
text += str(page.extract_text())
doc = Document(text=text)
return [doc]
The next step is to ingest, index, and store this document in a vector
database. In this case, we will use FAISS DB, as we require in an in-memory
vector database. FAISS is also very convenient to use. Hence, we write a
function called
get_vector_index()to do exactly that.
In case you’re interested in checking out other vector DB options, you read can this.
from llama_index.llms import OpenAI
from llama_index import VectorStoreIndex, ServiceContext, StorageContext
from llama_index.vector_stores import FaissVectorStore
def get_vector_index(documents):
llm = OpenAI(OPENAI_API_KEY)
faiss_index = faiss.IndexFlatL2(d)
vector_store = FaissVectorStore(faiss_index=faiss_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
service_context = ServiceContext.from_defaults(llm=llm)
index = VectorStoreIndex.from_documents(documents,
service_context=service_context,
storage_context=storage_context
)
return index
ServiceContext() and StorageContext() are used to
set the configurations for the vector store. Using
VectorStoreIndex.from_documents()
we ingest, index, and store the document as vector embeddings in the FAISS DB.
# Calling the functions through streamlit frontend
import streamlit as st
if "index" not in st.session_state:
st.session_state.index = None
if "process_doc" not in st.session_state:
st.session_state.process_doc = False
if st.sidebar.button("Process Document"):
with st.spinner("Processing Document..."):
documents = process_pdf(pdfs)
st.session_state.index = get_vector_index(documents)
st.session_state.process_doc = True
st.toast("Document Processsed!")
Query Tools and Engines
Now that we have our knowledge base ready, it’s time to build a mechanism to query it.
index = get_vector_index(documents)
engine = index.as_query_engine()
query = "How has Microsoft performed in this fiscal year?"
response = engine(query)
Ideally, the above code should have been enough to query and synthesize a response from the information in the vector DB. However, the response wouldn't be comprehensive and detailed enough, especially for such open-ended questions. We need to develop a better mechanism that allows us to break down a query into more detailed questions and retrieve context from multiple parts of the vector DB.
def get_query_engine(engine):
query_engine_tools = [
QueryEngineTool(
query_engine=engine,
metadata=ToolMetadata(
name="Annual Report",
description=f"Provides information about the company from its annual report.",
),
),
]
s_engine = SubQuestionQueryEngine.from_defaults(query_engine_tools=query_engine_tools)
return s_engine
index = get_vector_index(documents)
engine = index.as_query_engine()
s_engine = get_query_engine(engine)
Let’s break the above function down. The
QueryEngineTool module wraps around the engine and
helps provide context and metadata to the engine. This is especially useful
when you have more than one engine and you want to provide context to the LLM
as to which one to use for a given query.
Here’s what that would look like:
# example for multiple query engine tools
query_engine_tools = [
QueryEngineTool(
query_engine=sept_engine,
metadata=ToolMetadata(
name="sept_22",
description="Provides information about Uber quarterly financials ending September 2022",
),
),
QueryEngineTool(
query_engine=june_engine,
metadata=ToolMetadata(
name="june_22",
description="Provides information about Uber quarterly financials ending June 2022",
),
)
]You can read more about the tools available in LlamaIndex here.
However, we’re currently sticking to just one QueryEnginerTool for now.
The SubQuestionQueryEngine module breaks down a complex query
into many sub-questions and their target query engine for execution. After
executing all sub-questions, all responses are gathered and sent to a response
synthesizer to produce the final response. Using this module is essential
because generating insights from annual reports requires complex queries that
need to retrieve information from multiple nodes within the vector DB.

Prompt Engineering
Prompt engineering is essential to the entire process mainly for two reasons:
- To provide clarity to the agent as to what it needs to retrieve from the vector DB by writing precise and relevant queries
- And then control the quality of the output generated from the retrieved context by providing a structure and description for the output to be generated.
Both these points are handled by using
PromptTemplate and PydanticOutputParser module in
langchain .
Using the PydanticOutputParser we write the description for the
different sections of the insights to be generated. After having a few
conversations with finance experts, I concluded generating insights for these
4 sections: different sections: Fiscal Year Highlights, Strategic Outlook and
Future Direction, Risk Management, Innovation and R&D. Now let’s write the
pydantic class for these sections:
from pydantic import BaseModel, Field
class FiscalYearHighlights(BaseModel):
performance_highlights: str = Field(..., description="Key performance metrics and financial stats over the fiscal year.")
major_events: str = Field(..., description="Highlight of significant events, acquisitions, or strategic shifts that occurred during the year.")
challenges_encountered: str = Field(..., description="Challenges the company faced during the year and, if and how they managed or overcame them.")
class StrategyOutlookFutureDirection(BaseModel):
strategic_initiatives: str = Field(..., description="The company's primary objectives and growth strategies for the upcoming years.")
market_outlook: str = Field(..., description="Insights into the broader market, competitive landscape, and industry trends the company anticipates.")
class RiskManagement(BaseModel):
risk_factors: str = Field(..., description="Primary risks the company acknowledges.")
risk_mitigation: str = Field(..., description="Strategies for managing these risks.")
class InnovationRnD(BaseModel):
r_and_d_activities: str = Field(..., description="Overview of the company's focus on research and development, major achievements, or breakthroughs.")
innovation_focus: str = Field(..., description="Mention of new technologies, patents, or areas of research the company is diving into.")
Note: These sections and their description are for generic use cases. They can be changed to suit your particular needs.
These pydantic classes will provide the format and description for each section to the prompt. So let’s write a function that allows us to plug in any pydantic class to a prompt:
from langchain.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParser
prompt_template = """
You are given the task of generating insights for {section} from the annual report of the company.
Given below is the output format, which has the subsections.
Must use bullet points.
Always use $ symbol for money values, and round it off to millions or billions accordingly
Incase you don't have enough info you can just write: No information available
---
{output_format}
---
"""
def report_insights(engine, section, pydantic_model):
parser = PydanticOutputParser(pydantic_object=pydantic_model)
prompt_template = PromptTemplate(
template=prompt_template,
input_variables=["section"],
partial_variables={"output_format": parser.get_format_instructions()}
)
formatted_input = prompt_template.format(section=section)
response = engine.query(formatted_input)
parsed_response = parser.parse(response.response)
return parsed_response
PromptTemplate plugs in all the values such as
section and output_format into the prompt template.
PydanticOutputParser converts the pydantic class into a format
that is readable to the LLM. The response generated will be in string format,
hence we use the parser.parse() function to parse the response
and get a structured output.
# calling the function in streamlit frontend
if st.session_state.process_doc:
if st.button("Analyze Report"):
engine = get_query_engine(st.session_state.index.as_query_engine(similarity_top_k=3))
with st.status("**Analyzing Report...**"):
st.write("Fiscal Year Highlights...")
st.session_state.fiscal_year_highlights = report_insights(engine, "Fiscal Year Highlights", FiscalYearHighlights)
st.write("Strategy Outlook and Future Direction...")
st.session_state.strategy_outlook_future_direction = report_insights(engine, "Strategy Outlook and Future Direction", StrategyOutlookFutureDirection)
st.write("Risk Management...")
st.session_state.risk_management = report_insights(engine, "Risk Management", RiskManagement)
st.write("Innovation and R&D...")
st.session_state.innovation_and_rd = report_insights(engine, "Innovation and R&D", InnovationRnD)
# displaying the generated insights
if st.session_state.fiscal_year_highlights:
with tab1:
st.write("## Fiscal Year Highlights")
st.write("### Performance Highlights")
st.write(st.session_state.fiscal_year_highlights.performance_highlights)
st.write("### Major Events")
st.write(st.session_state.fiscal_year_highlights.major_events)
st.write("### Challenges Encountered")
st.write(st.session_state.fiscal_year_highlights.challenges_encountered)
st.write("### Milestone Achievements")
st.write(str(st.session_state.fiscal_year_highlights.milestone_achievements))
if st.session_state.strategy_outlook_future_direction:
with tab2:
st.write("## Strategy Outlook and Future Direction")
st.write("### Strategic Initiatives")
st.write(st.session_state.strategy_outlook_future_direction.strategic_initiatives)
st.write("### Market Outlook")
st.write(st.session_state.strategy_outlook_future_direction.market_outlook)
st.write("### Product Roadmap")
st.write(st.session_state.strategy_outlook_future_direction.product_roadmap)
if st.session_state.risk_management:
with tab3:
st.write("## Risk Management")
st.write("### Risk Factors")
st.write(st.session_state.risk_management.risk_factors)
st.write("### Risk Mitigation")
st.write(st.session_state.risk_management.risk_mitigation)
if st.session_state.innovation_and_rd:
with tab4:
st.write("## Innovation and R&D")
st.write("### R&D Activities")
st.write(st.session_state.innovation_and_rd.r_and_d_activities)
st.write("### Innovation Focus")
st.write(st.session_state.innovation_and_rd.innovation_focus)
You can find the complete code Annual Report Analyzer here
Upcoming Features
- Select and Store Insights: I’ve been working on a feature that allows the user to select any insight needed and also save it into the user’s account
- Adding more profession-specific insights: Currently, the insight works well for generic purposes. However, different professions use annual reports differently, so naturally I need to create a different set of insights based on the user’s use case.
-
PandasQueryEngineModule for querying financial statements: Using this module, the LLM will be able to extract better insights from financial statements which are typically in a structured format.
Conclusion
In summary, FinSight’s Annual Report Analyzer makes financial analysis easier and more insightful by harnessing the power of LLMs. It’s a valuable tool for portfolio managers, financial analysts, and shareholders, saving time and improving decision-making. While the core pipeline remains consistent, note that our deployed app code might evolve to incorporate upgrades and enhanced features, ensuring ongoing improvements.
Big thanks to LlamaIndex for helping me make FinSight a reality. No other framework is as advanced in making RAG-based tools.
If you like what you’ve read, please do leave a clap for me, and also show some love to FinSight. You can check out the GitHub repo here.