Building a robust question-answering assistant requires dynamically retrieving the most relevant information for each query. Sometimes a short snippet provides a complete answer, while other questions need the full context of an entire document (e.g. “Give me a summary of this book”).
For questions that fall into the latter category, top-k vector search falls short; rather than just retrieving the top-k chunks that match, you need to intentionally retrieve the entire document text and feed that into the context window of the LLM.
To address this, we’re excited to release file-level retrieval for LlamaParse, which is a separate retrieval API from our existing chunk-level retrieval capabilities. This retrieval interface then paves the way for us to build an agent that can dynamically route the question to the right retrieval interface depending on the properties of the question, which allows it to more robustly handle different user questions.

File-Level Retrieval
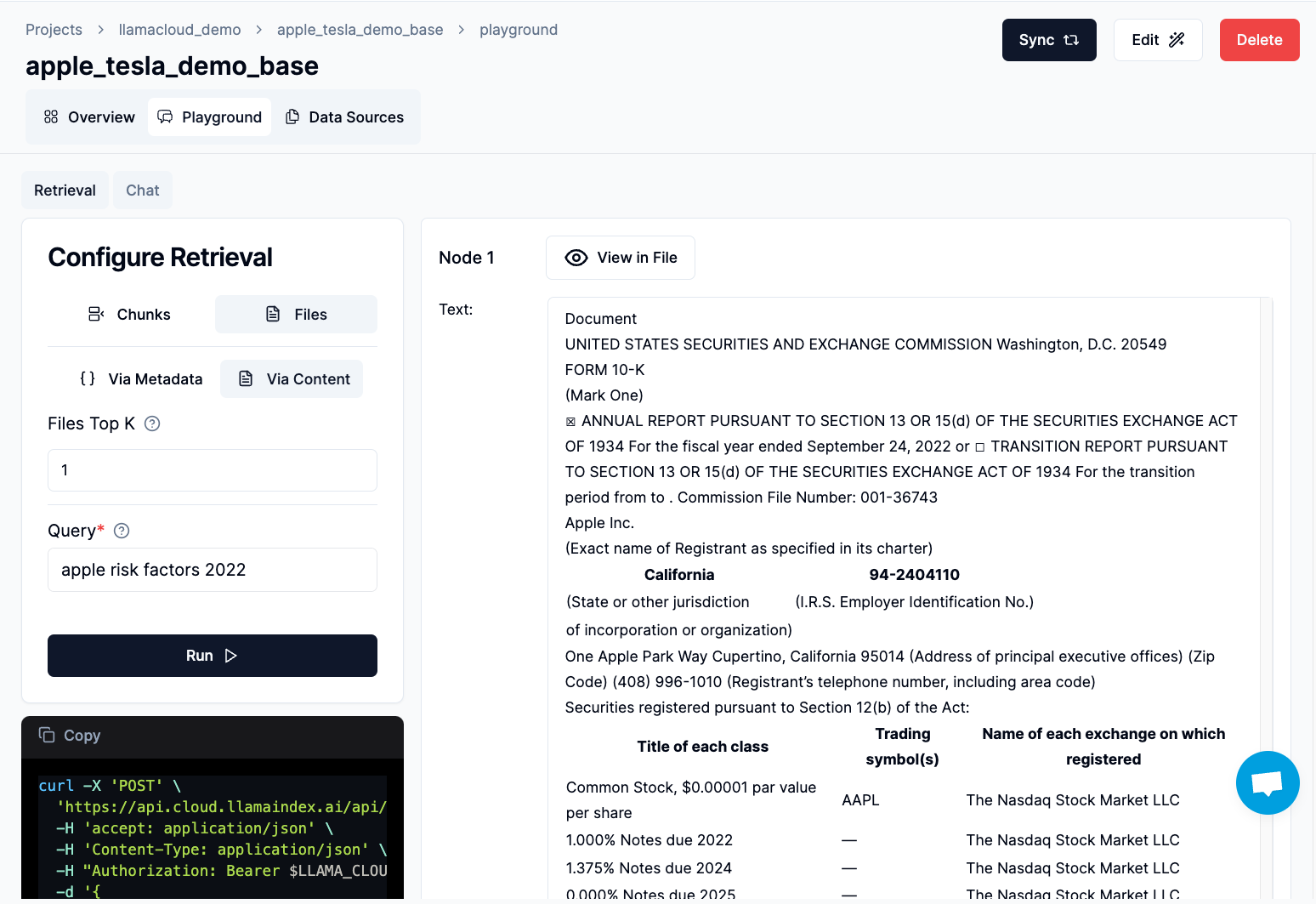
This method retrieves the full content of a document, such as an entire SEC 10K filing or an entire slide deck. There are two main ways to perform file-level retrieval:
- By Metadata: Selects files based on their metadata.
- By Content: Uses the document's content to determine the most relevant files.
The interface allows you to seamlessly toggle between retrieval modes, and adjust parameters like top-k results, and even filter by metadata when using file-level retrieval.
Building an Agent for Dynamic Retrieval
To demonstrate the power of dynamic retrieval, we've created a Jupyter notebook that guides you through building an agent capable of choosing between chunk-level and file-level retrieval based on the question at hand. Let's walk through the key steps:
- Defining Retrievers: We set up both chunk-level and file-level retrievers using LlamaParse's
as_retrievermethod. These can be converted into query engines that can synthesize an answer over retrieved context given a question.
python
# File-level retriever
doc_retriever = index.as_retriever(
retrieval_mode="files_via_content",
files_top_k=1
)
# Chunk-level retriever
chunk_retriever = index.as_retriever(
retrieval_mode="chunks",
rerank_top_n=5
)- Building the Agent: The heart of the notebook is the agent that decides which query tool to use. It analyzes the input question and chooses the appropriate retrieval method based on the tool description. In this section, we keep it simple - tell the agent to choose file-level retrieval if the question is more for “high-level summarization”, otherwise do chunk-level retrieval.
- Testing the Agent: Even with these basic tool prompts, our agent can already intelligently decide to perform file-level retrieval for more “summarization-esque” questions.
python
# uses chunk-level retrieval twice
response = agent.chat("Tell me the revenue for Apple and Tesla in 2021?")
print(response)
# uses file-level retrieval twice
response = agent.chat("How was Tesla doing generally in 2021 and 2022?")
print(response)- [Advanced] File-level Retrieval : The notebook also demonstrates how to set up more sophisticated file-level retrieval by inferring metadata filters and injecting few-shot examples of existing files, letting the agent better make a decision of file-level vs. chunk-level based on the actual files that have been uploaded instead of just a fixed prompt.
Build more Robust QA Interfaces Starting Today
LlamaParse's dynamic retrieval capabilities represent a significant step forward in building more intelligent and context-aware LLM applications. By offering the flexibility to choose between chunk-level and file-level retrieval, developers can create more nuanced and accurate systems that adapt to the specific needs of each query.
We encourage you to explore these new features in the LlamaParse UI and try out the notebook for yourself. As always, we're excited to see what you'll build with these enhanced retrieval capabilities!
Want to see what LlamaParse can do for you?
Come sign up on our waitlist for access. If you’re interested in chatting about enterprise plans, get in touch.
If you’ve gotten access to LlamaParse, check out our rich repository of demonstrations and examples on how to build different LLM application use cases.