

LlamaIndex is convinced of the potential and power of LLM-powered agents built with our frameworks, so we are thrilled to have collaborated with NVIDIA on the design and release of an NVIDIA AI Blueprint for a multi-agent system that researches, writes and refines blog posts on any topic using agentic-driven RAG. You can read the announcement or check out the blueprint. In this blog post, we’ll dive into the architecture of the multi-agent system defined by the blueprint, to explain what’s going on and how you can extend the system for your own purposes. You can also check out our video, where we go through the code of the blueprint step by step.
Overview
The blueprint defines a few things:
- A RAG pipeline that accepts an arbitrary set of documents, and embeds and indexes them for querying
- An agentic tool based on this pipeline that makes it possible for agents to query the RAG database
- A LlamaIndex Workflow that accepts an arbitrary set of tools, plus a query
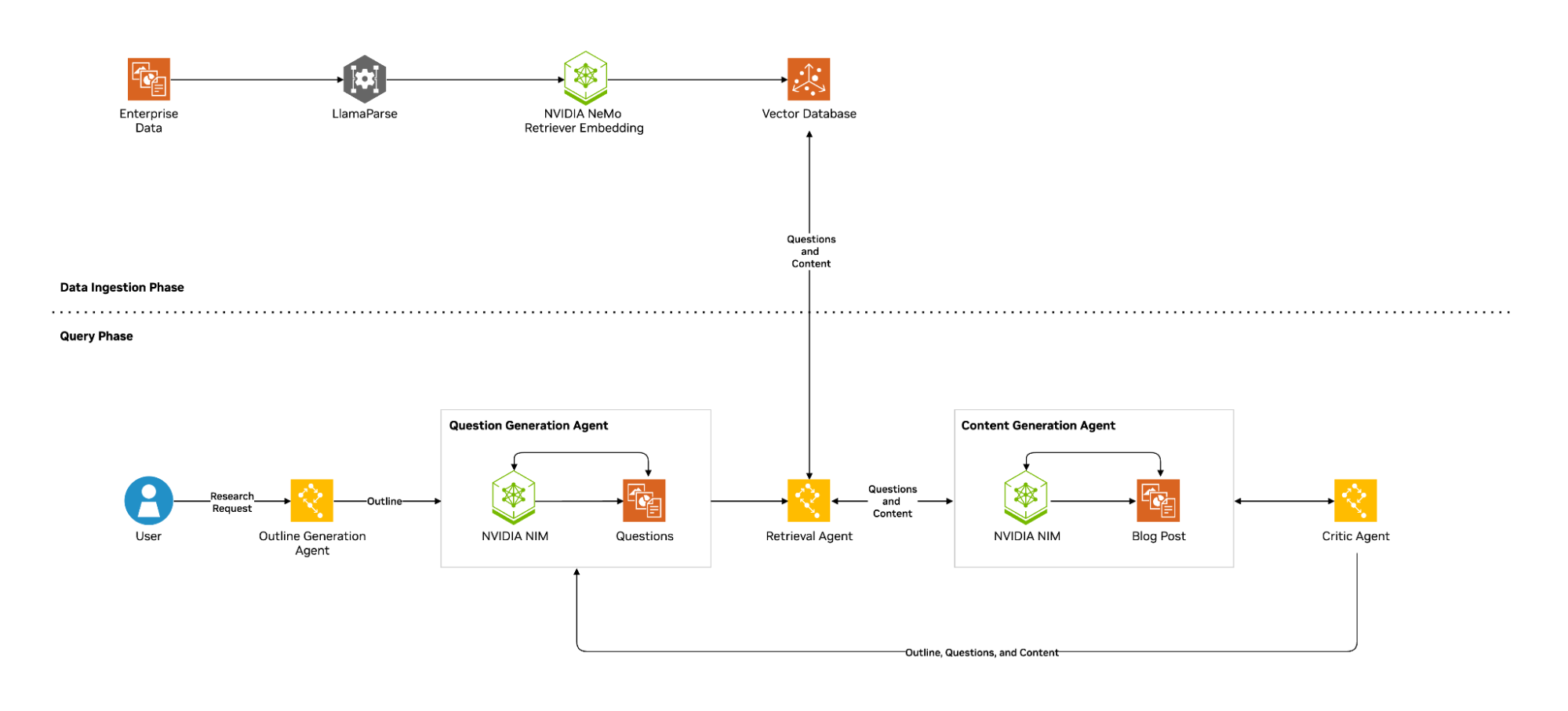
The Workflow is designed to take the query and use the tools given to it to write a blog post about that query. The way it does that is shown in the diagram below:
- First, using the query as a topic, an agent outlines what a blog post about that topic might look like
- A second agent reads the outline and creates a set of simple questions that would provide the facts necessary to write a blog post following that outline
- A third agent is repeatedly called to query the RAG database with the questions given, fetch relevant context, and generate answers to those questions
- A fourth agent is given the query, the outline, and the answers, and writes a blog post given all the facts available to it
- A fifth agent reviews the blog post against the original query and decides whether it is a comprehensive response to the question
- If the blog post is deemed of sufficient quality, it is output to the user
- If the blog post needs more work, the agent generates an additional set of questions to further flesh out the blog post
- These questions and answers are added to the original set and returned to the fourth agent, which will rewrite the blog post with this additional context and try again (a maximum of 3 times)

Architecture
This multi-agent system is designed from the ground up to use the NVIDIA NeMo Retriever embedding and Llama3.3-70b-Instruct LLM NVIDIA NIM microservices, which can be deployed on NVIDIA GPUs in workstations, data centers, or cloud environments. In the diagram below, you can see the two distinct phases of the system: set up and querying.

Getting set up
The core of any RAG-based system is data. In the set up phase, the provided documents are parsed by LlamaParse, our world-class document parsing system, which converts complex document formats like PDFs, Word documents, PowerPoints and spreadsheets into Markdown text that LLMs find easy to understand.
The parsed documents are then ingested into a vector store. This first takes the text of the documents and converts them into vectors using the NVIDIA NeMo Retriever embedding NIM microservice, then stores them in a vector store. In the blueprint, the vectors are simply persisted to disk; in production, you would use one of the dozens of vector stores supported by LlamaIndex and available on LlamaHub to persist and search these vectors.
This vector store is then instantiated as a query engine, a LlamaIndex abstraction that allows you to send a query to the vector store, retrieve chunks of data semantically relevant to that query, and then pass the query and the data as context to the LLM to answer the query. The LLM used in this case is Llama 3.3-70b from Meta, and is also available as an NVIDIA NIM microservice.
By using AI models packaged as NIM microservices, the system can achieve greater model performance and efficiency.
NIM microservices use pre-optimized inference engines like NVIDIA TensorRT and NVIDIA TensorRT-LLM, which are specifically tailored for low-latency, high-throughput inferencing on NVIDIA GPU systems.
NIM microservices help improve throughput. For example, running Meta Llama 3-8B as a NIM microservice produces up to 3x more generative AI tokens on accelerated infrastructure compared to deployment without.
This query engine is then further wrapped into a QueryEngineTool, an abstraction that allows agents built in LlamaIndex to query the RAG database and retrieve answers.
The query phase
In the query phase, the user passes an array of tools to the Workflow, along with their query. In the blueprint, we are passing only one tool, the query engine we created above. In production, you could pass multiple RAG databases, as well as tools that let you search the wider web for context.
The multi-agent Workflow then unfolds as described earlier:
- An outline is written
- Questions are formulated to satisfy the outline
- The questions are answered
- A blog post is written from the outline and the questions
- The blog post is critiqued for accuracy and thoroughness
- If it’s adequate it is output
- If it’s not, additional questions are generated and the process repeats
At each step, the agents are using an LLM NIM microservice. In the blueprint, they are all using the same Llama 3.3 model from Meta, but you could provide a different LLM for every phase, balancing quality with speed, or even fine-tuning a model to specialize at each task.
Enhancing and customizing your blueprint
As mentioned earlier, this blueprint is a jumping-off point for you to create your own multi-agent system. You will certainly want to substitute a production-ready vector store for the on-disk version in the blueprint, and you may want to use a variety of different models rather than Llama 3.3-70b for every task.
Other enhancements are possible at the cost of increasing the complexity and time the system takes. The current prompts limit the number of questions originally generated to 8, and the number of follow-up questions to 4. Increasing these limits could potentially improve the quality of the output at some cost in speed.
Another potential improvement is to take the reflection phase back to the outline step: given the facts the agent now knows about the topic, does the outline still make sense, or should it be refactored? You could get the LLM to generate a new outline and attempt to rewrite the blog post based on what it learned in the research phase.
Get started today!
The full code for the blueprint is available in the examples section of our documentation. We’re eager to see what use-cases you find for our agentic research system, and what extensions and enhancements you add. Get started with the blueprint on NVIDIA today!

