Summary
In this article, we showcase a powerful new query engine ( SQLAutoVectorQueryEngine ) in LlamaIndex that can leverage both a SQL database as well as a vector store to fulfill complex natural language queries over a combination of structured and unstructured data. This query engine can leverage the expressivity of SQL over structured data, and join it with unstructured context from a vector database. We showcase this query engine on a few examples and show that it can handle queries that make use of both structured/unstructured data, or either.
Check out the full guide here: https://gpt-index.readthedocs.io/en/latest/examples/query_engine/SQLAutoVectorQueryEngine.html.
Context
Data lakes in enterprises typically encompass both structured and unstructured data. Structured data is typically stored in a tabular format in SQL databases, organized into tables with predefined schemas and relationships between entities. On the other hand, unstructured data found in data lakes lacks a predefined structure and does not fit neatly into traditional databases. This type of data includes text documents, but also other multimodal formats such as audio recordings, videos, and more.
Large Language Models (LLMs) have the ability to extract insights from both structured and unstructured data. There have been some initial tooling and stacks that have emerged for tackling both types of data:
- Text-to-SQL (Structured data): Given a collection of tabular schemas, we convert natural language into a SQL statement which can then be executed against the database.
- Semantic Search with a Vector Database (Unstructured Data): Store unstructured documents along with their embeddings in a vector database (e.g. Pinecone, Chroma, Milvus, Weaviate, etc.). During query-time, fetch the relevant documents by embedding similarity, and then put into the LLM input prompt to synthesize a response.
Each of these stacks solves particular use cases.
Text-to-SQL Over Structured Data
In the structured setting, SQL is an extremely expressive language for operating over tabular data — in the case of analytics, you can get aggregations, join information across multiple tables, sort by timestamp, and much more. Using the LLM to convert natural language to SQL can be thought as a program synthesis “cheat code” — just let the LLM compile to the right SQL query, and let the SQL engine on the database handle the rest!
Use Case: Text-to-SQL queries are well-suited for analytics use cases where the answer can be found by executing a SQL statement. They are not suited for cases where you’d need more detail than what is found in a structured table, or if you’d need more sophisticated ways of determining relevance to the query beyond simple constructs like WHERE conditions.
Example queries suited for Text-to-SQL:
- “What is the average population of cities in North America”?
- “What are the largest cities and populations in each respective continent?”
Semantic Search over Unstructured Data
In the unstructured setting, the behavior for retrieval-augmented generation systems is to first perform retrieval and then synthesis. During retrieval, we first look up the most relevant documents to the query by embedding similarity. Some vector stores support being able to handle additional metadata filters for retrieval. We can choose to manually specify the set of required filters, or have the LLM “infer” what the query string and metadata filters should be (see our auto-retrieval modules in LlamaIndex or LangChain’s self-query module).
Use Case: Retrieval Augmented Generation is well suited for queries where the answer can be obtained within some sections of unstructured text data. Most existing vector stores (e.g. Pinecone, Chroma) do not offer a SQL-like interface; hence they are less suited for queries that involve aggregations, joins, sums, etc.
Example queries suited for Retrieval Augmented Generation
- “Tell me about the historical museums in Berlin”
- “What does Jordan ask from Nick on behalf of Gatsby?”
Combining These Two Systems
For some queries, we may want to make use of knowledge in both structured tables as well as vector databases/document stores in order to give the best answer to the query. Ideally this can give us the best of both worlds: the analytics capabilities over structured data, and semantic understanding over unstructured data.
Here’s an example use case:
- You have access to a collection of articles about different cities, stored in a vector database
- You also have access to a structured table containing statistics for each city.
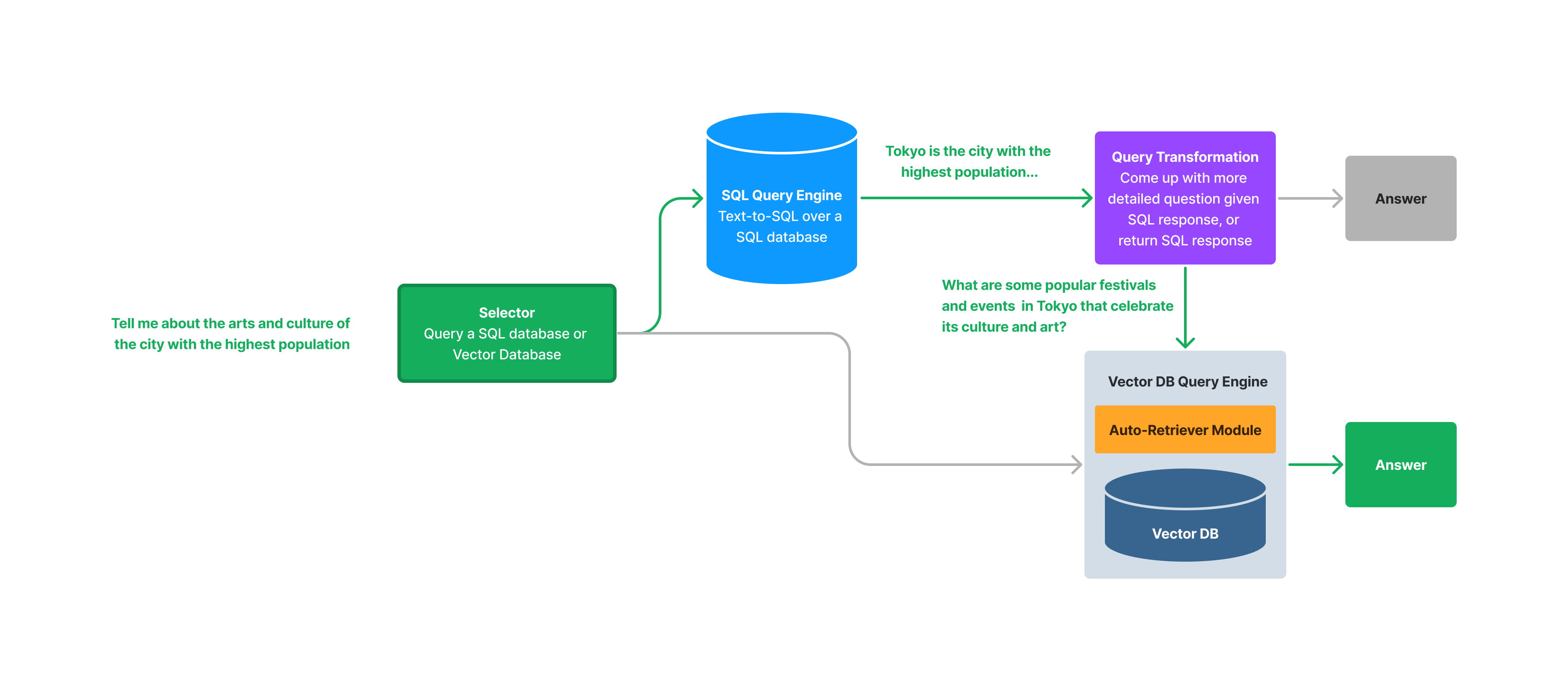
Given this data collection, let’s take an example query: “Tell me about the arts and culture of the city with the highest population.”
The “proper” way to answer this question is roughly as follows:
- Query the structured table for the city with the highest population.
SELECT city, population FROM city_stats ORDER BY population DESC LIMIT 1- Convert the original question into a more detailed question: “Tell me about the arts and culture of Tokyo.”
- Ask the new question over your vector database.
- Use the original question + intermediate queries/responses to SQL db and vector db to synthesize the answer.
Let’s think about some of the high-level implications of such a sequence:
- Instead of doing embedding search (and optionally metadata filters) to retrieve relevant context, we want to somehow have a SQL query as a first “retrieval” step.
- We want to make sure that we can somehow “join” the results from the SQL query with the context stored in the vector database. There is no existing language to “join” information between a SQL and vector database. We will have to implement this behavior ourselves.
- Neither data source can answer this question on its own. The structured table only contains population information. The vector database contains city information but no easy way to query for the city with the maximum population.
A Query Engine to Combine Structured Analytics and Semantic Search
We have created a brand-new query engine ( SQLAutoVectorQueryEngine ) that can query, join, sequence, and combine both structured data from both your SQL database and unstructured data from your vector database in order to synthesize the final answer.
The SQLAutoVectorQueryEngine is initialized through passing in a SQL query engine ( GPTNLStructStoreQueryEngine ) as well as a query engine that uses our vector store auto-retriever module ( VectorIndexAutoRetriever ). Both the SQL query engine and vector query engines are wrapped as “Tool” objects containing a name and description field.
Reminder: the
VectorIndexAutoRetrievertakes in a natural language query as input. Given some knowledge of the metadata schema of the vector database, the auto retriever first infers the other necessary query parameters to pass in (e.g. top-k value, and metadata filters), and executes a query against the vector database with all the query parameters.

During query-time, we run the following steps:
- A selector prompt (similarly used in our
RouterQueryEngine, see guide) first chooses whether we should query the SQL database or the vector database. If it chooses to use the vector query engine, then the rest of the function execution is the same as querying theRetrieverQueryEnginewithVectorIndexAutoRetriever. - If it chooses to query the SQL database, it will execute a text-to-SQL query operation against the database, and (optionally) synthesize a natural language output.
- A query transformation is run, to convert the original question into a more detailed question given the results from the SQL query. For instance if the original question is “Tell me about the arts and culture of the city with the highest population.”, and the SQL query returns Tokyo as the city with the highest population, then the new query is “Tell me about the arts and culture of Tokyo.” The one exception is if the SQL query itself is enough to answer the original question; if it is, then function execution returns with the SQL query as the response.
- The new query is then run through through the vector store query engine, which performs retrieval from the vector store and then LLM response synthesis. We enforce using a
VectorIndexAutoRetrievermodule. This allows us to automatically infer the right query parameters (query string, top k, metadata filters), given the result of the SQL query. For instance, with the example above, we may infer the query to be something likequery_str="arts and culture"andfilters={"title": "Tokyo"}. - The original question, SQL query, SQL response, vector store query, and vector store response are combined into a prompt to synthesize the final answer.
Taking a step back, here are some general comments about this approach:
- Using our auto-retrieval module is our way of simulating a join between the SQL database and vector database. We effectively use the results from our SQL query to determine the parameters to query the vector database with.
- This also implies that there doesn’t need to be an explicit mapping between the items in the SQL database and the metadata in the vector database, since we can rely on the LLM being able come up with the right query for different items. It would be interesting to model explicit relationships between structured tables and document store metadata though; that way we don’t need to spend an extra LLM call in the auto-retrieval step inferring the right metadata filters.
Experiments
So how well does this work? It works surprisingly well across a broad range of queries, from queries that can leverage both structured data and unstructured data to queries that are specific to a structured data collection or unstructured data collection.
Setup
Our experiment setup is very simple. We have a SQL table called city_stats which contains the city, population, and country of three different cities: Toronto, Tokyo, and Berlin.
We also use a Pinecone index to store Wikipedia articles corresponding to the three cities. Each article is chunked up and stored as a separate “Node” object; each chunk also contains a title metadata attribute containing the city name.
We then derive the VectorIndexAutoRetriever and RetrieverQueryEngine from the Pinecone vector index.
from llama_index.indices.vector_store.retrievers import VectorIndexAutoRetriever
from llama_index.vector_stores.types import MetadataInfo, VectorStoreInfo
from llama_index.query_engine.retriever_query_engine import RetrieverQueryEngine
vector_store_info = VectorStoreInfo(
content_info='articles about different cities',
metadata_info=[
MetadataInfo(
name='city',
type='str',
description='The name of the city'),
]
)
vector_auto_retriever = VectorIndexAutoRetriever(vector_index, vector_store_info=vector_store_info)
retriever_query_engine = RetrieverQueryEngine.from_args(
vector_auto_retriever, service_context=service_context
)You can also get the SQL query engine as follows
sql_query_engine = sql_index.as_query_engine()Both the SQL query engine and vector query engine can be wrapped as QueryEngineTool objects.
sql_tool = QueryEngineTool.from_defaults(
query_engine=sql_query_engine,
description=(
'Useful for translating a natural language query into a SQL query over a table containing: '
'city_stats, containing the population/country of each city'
)
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=query_engine,
description=f'Useful for answering semantic questions about different cities',
)Finally, we can define our SQLAutoVectorQueryEngine
query_engine = SQLAutoVectorQueryEngine(
sql_tool,
vector_tool,
service_context=service_context
)Results
We run some example queries.
Query 1
query_engine.query(
'Tell me about the arts and culture of the city with the highest population'
)Intermediate steps:

Final Response:
Tokyo is the city with the highest population, with 13.96 million people. It is a vibrant city with a rich culture and a wide variety of art forms. From traditional Japanese art such as calligraphy and woodblock prints to modern art galleries and museums, Tokyo has something for everyone. There are also many festivals and events throughout the year that celebrate the city's culture and art. Some popular festivals and events in Tokyo include the Sannō Festival at Hie Shrine, the Sanja Festival at Asakusa Shrine, and the biennial Kanda Festivals. These events often feature parades with elaborately decorated floats and thousands of people. Additionally, an enormous fireworks display over the Sumida River takes place annually on the last Saturday of July, attracting over a million viewers. During spring, when cherry blossoms bloom, many residents gather in Ueno Park, Inokashira Park, and the Shinjuku Gyoen National Garden for picnics under the blossoms.This query runs through the full flow of the SQLAutoVectorQueryEngine . It first queries the SQL database for the city with the highest population (“Tokyo”), and then queries the vector database with the new query. The results are combined into a final response.
Query 2
query_engine.query("Tell me about the history of Berlin")Intermediate Steps:

Final Response:
Berlin's history dates back to the early 13th century when it was founded as a small settlement. In 1618, the Margraviate of Brandenburg entered into a personal union with the Duchy of Prussia, and in 1701, they formed the Kingdom of Prussia with Berlin as its capital. The city grew and merged with neighboring cities, becoming a center of the Enlightenment under the rule of Frederick the Great in the 18th century.
The Industrial Revolution in the 19th century transformed Berlin, expanding its economy, population, and infrastructure. In 1871, it became the capital of the newly founded German Empire. The early 20th century saw Berlin as a hub for the German Expressionist movement and a major world capital known for its contributions to science, technology, arts, and other fields.
In 1933, Adolf Hitler and the Nazi Party came to power, leading to a decline in Berlin's Jewish community and the city's involvement in World War II. After the war, Berlin was divided into East and West Berlin, with the former under Soviet control and the latter under the control of the United States, United Kingdom, and France. The Berlin Wall was built in 1961, physically and ideologically dividing the city until its fall in 1989. Following the reunification of Germany in 1990, Berlin once again became the capital of a unified Germany and has since continued to grow and develop as a major global city.This query only requires the vector database and not the SQL database. The initial selector correctly identifies that we should just query the vector database and return the result.
Query 3
query_engine.query('Can you give me the country corresponding to each city?')Intermediate Steps

Final Response
Toronto is in Canada, Tokyo is in Japan, and Berlin is in Germany.This query can be answered by just querying the SQL database, it does not need additional information from the vector database. The query transform step correctly identifies “None” as the followup question, indicating that the original question has been answered.
Conclusion
So far, the stacks around LLMs + unstructured data and LLMs + structured data have largely been separate. We’re excited about how combining LLMs on top of both structured and unstructured data can unlock new retrieval/query capabilities in novel and interesting ways!
We’d love for you to try out the SQLAutoVectorQueryEngine and let us know what you think.
The full notebook walkthrough can be found in this guide (associated notebook).