Introduction
LlamaIndex (GPT Index) offers an interface to connect your Large Language Models (LLMs) with external data. LlamaIndex provides various data structures to index your data, such as the list index, vector index, keyword index, and tree index. It offers both a high-level API and low-level API — the high-level API allows you to build a Question-Answering (QA) system in just five lines of code, whereas the lower-level API allows you to customize various aspects of retrieval and synthesis.
However, taking these systems into production requires careful evaluation of the performance of the overall system — the quality of the outputs given the inputs. Evaluation of retrieval-augmented generation can be challenging because the user would need to come up with a dataset of relevant questions for a given context. To overcome these obstacles, LlamaIndex provides Question Generation and label-free Evaluation modules.
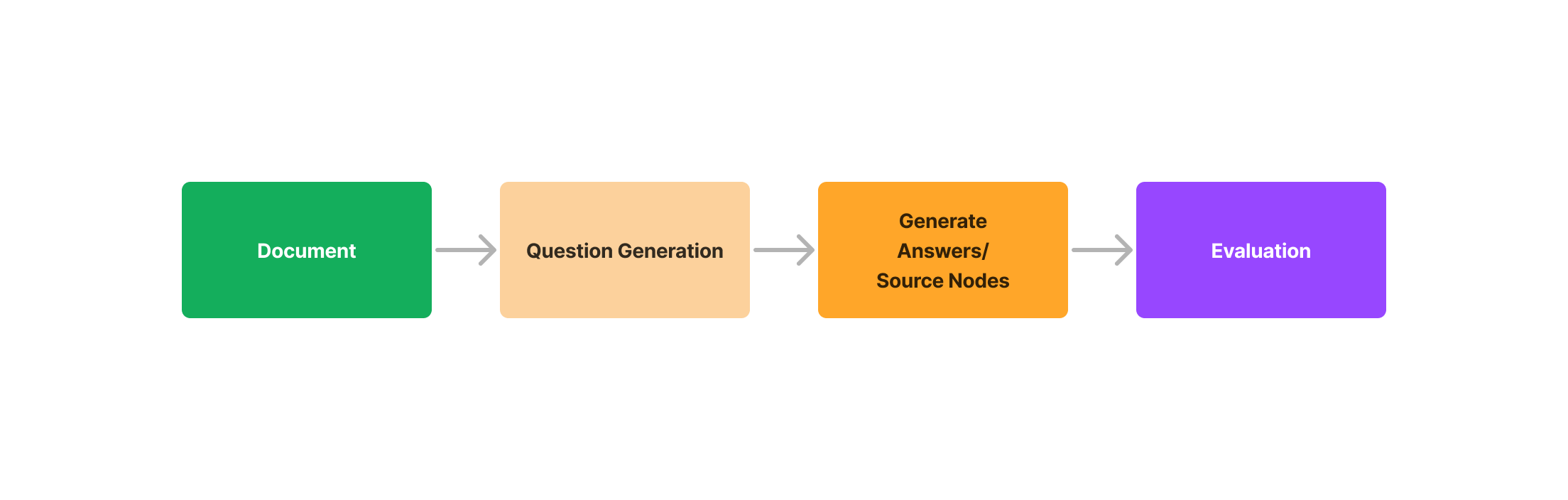
In this blog, we will discuss the three-step evaluation process using Question Generation and Evaluation modules:
- Question Generation from the document
- Generate answers/source nodes for questions using LlamaIndex QueryEngine abstractions, which manage the interaction between the LLM and data indices.
- Evaluate if the question (query), answer, and source nodes are matching/inline

1. Question Generation
It should be noted that this approach does not require ground-truth labels. The purpose of question generation is to generate an initial dataset of inputs over context that can be used to evaluate the question-answering system.
LlamaIndex offers the DataGenerator class, which generates questions from a given document using ListIndex. By default, it uses OpenAI ChatGPT (get-3.5-turbo) for question generation.
from llama_index.evaluation import DatasetGenerator
from llama_index import SimpleDirectoryReader
# Load documents
reader = SimpleDirectoryReader("./data")
documents = reader.load_data()
# Generate Question
data_generator = DatasetGenerator.from_documents(documents)
question = data_generator.generate_questions_from_nodes()
2. Generate Answers/Source Nodes (Context)
Using List Index, we generate answers and source nodes for the generated questions in the response object.
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader, load_index_from_storage, StorageContext
# load documents
documents = SimpleDirectoryReader('./data').load_data()
# Create Index
index = GPTVectorStoreIndex.from_documents(documents)
# save index to disk
index.set_index_id("vector_index")
index.storage_context.persist('storage')
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir='storage')
# load index
index = load_index_from_storage(storage_context, index_id="vector_index")
# Query the index
query_engine = index.as_query_engine(similarity_top_k=3)
response = query_engine.query(<Query>)
# Response object has both response and source nodes.3. Evaluation
The evaluation module can be used to answer the following three questions:
- Are the response generated and source nodes (context) matching? — Response + Source Nodes (Context)
- Are response generated, source nodes (context), and query matching? — Query + Response + Source Nodes (Context)
- Which source nodes of the retrieved source nodes are used to generate a response? — Query + Response + Individual Source Nodes (Context)
Evaluation can be done with some combination of the query, context, and response, combining these with LLM calls.
Response + Source Nodes (Context)
This function answers the question: Are the response generated and source nodes (context) matching?
The response object for a given query returns both the response and source nodes (context) with which it generated the response. We can now evaluate the response against the retrieved sources — without taking into account the query! This allows you to measure hallucination — if the response does not match the retrieved sources, this means that the model may be “hallucinating” an answer since it is not rooting the answer in the context provided to it in the prompt.
The result is a binary response — either “YES/NO”.
- YES — Response and Source Nodes (Context) are matching.
- NO — Response and Source Nodes (Context) are not matching.
from llama_index.evaluation import ResponseEvaluator
# build service context
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-4"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
# Build index and get response object
...
# define evaluator
evaluator = ResponseEvaluator(service_context=service_context)
# evaluate using the response object
eval_result = evaluator.evaluate(response)
Query + Response + Source Nodes (Context)
This function answers the question: Are response generated, source nodes (context), and query matching?
Often with the “Response + Source Nodes (Context)” approach, the response generated is in line with the source nodes but may not be the answer to the query. Therefore, considering the query along with the response and source nodes is a good approach for a more accurate analysis.
The goal is to determine if the response + source context answers the query. The result is a binary response — either “YES/NO”.
- YES — Query, Response, and Source Nodes (Context) are matching.
- NO — Query, Response, and Source Nodes (Context) are not matching.
from llama_index.evaluation import QueryResponseEvaluator
# build service context
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-4"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
# Build index and get response object
...
# define evaluator
evaluator = QueryResponseEvaluator(service_context=service_context)
# evaluate using the response object
eval_result = evaluator.evaluate(query, response)
Query + Response + Individual Source Nodes (Context)
This function answers the question: Which source nodes of the retrieved source nodes are used to generate a response?
Often in the real world, the source nodes can be nodes from different documents. In these cases, it’s important to understand which source nodes are relevant and show those documents to the users. This mode of evaluation will look at each source node and see if each source node contains an answer to the query.
from llama_index.evaluation import QueryResponseEvaluator
# build service context
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-4"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
# build index and get response object
...
# define evaluator
evaluator = QueryResponseEvaluator(service_context=service_context)
# evaluate using the response object
eval_result = evaluator.evaluate_source_nodes(response)
Google Colab notebook for Evaluating QA systems using LlamaIndex —
Conclusion
LlamaIndex provides a comprehensive solution for building and evaluating QA systems without the need for ground-truth labels. By using the Question Generation and Evaluation modules, you can ensure that your system is accurate and reliable, making it suitable for production environments.