

Co-authors:
- Prakul Agarwal — Senior Product Manager, Machine Learning at MongoDB
- Jerry Liu — co-founder at LlamaIndex
Update (6/22/2023): The preferred way to use LlamaIndex + MongoDB is now with our MongoDBAtlasVectorSearch class. Take a look at our guide here: https://gpt-index.readthedocs.io/en/latest/examples/vector_stores/MongoDBAtlasVectorSearch.html
Summary
Large Language Models (LLMs) like ChatGPT have revolutionized the way users can get answers to their questions. However, the “knowledge” of LLMs is restricted by what they were trained on, which for ChatGPT means publicly available information on the internet till September 2021. How can LLMs answer questions using private knowledge sources like your company’s data and unlock its true transformative power?
This blog will discuss how LlamaIndex and MongoDB can enable you to achieve this outcome quickly. The attached notebook provides a code walkthrough on how to query any PDF document using English queries.
Background
Traditionally, AI has been used to analyze data, identify patterns and make predictions based on existing data. The recent advancements have led to AI becoming better at generating new things (rather than just analyzing existing things). This is referred to as Generative AI. Generative AI is powered mainly by machine learning models called Large Language Models (LLM). LLMs are pre-trained on large quantities of publicly available text. There are various proprietary LLMs from companies like OpenAI, Cohere, AI21, as well as a lot of emerging open-source LLMs like Llama, Dolly, etc.
There are 2 main scenarios where the knowledge of LLMs falls short:
- Private data such as your company’s internal knowledge base spread across PDFs, Google Docs, Wiki pages, and applications like Salesforce and Slack
- Newer data than when the LLMs were last trained. Example question: Who is the most recent UK prime minister?
There are 2 main paradigms currently for extending the amazing reasoning and knowledge generation capabilities of LLMs: Model finetuning and in-context learning.
Model Finetuning can be more complex and expensive to operationalize. There are also some open questions like how to delete information from a fine-tuned model to ensure you comply with local laws (ex. GDPR in Europe), and for changing data you need to fine-tune again constantly.
In-context learning requires inserting the new data as part of the input prompts to the LLM. To perform this data augmentation in a secure, high performance and cost-effective manner is where tools like LlamaIndex and MongoDB Developer Data Platform can help.
Introduction to LlamaIndex
LlamaIndex provides a simple, flexible interface to connect LLMs with external data.
- Offers data connectors to various data sources and data formats (APIs, PDFs, docs, etc).
- Provides indices over the unstructured and structured data for use with LLMs.
- Structures external information so that it can be used with the prompt window limitations of any LLM.
- Exposes a query interface which takes in an input prompt and returns a knowledge-augmented output.
MongoDB as the Datastore
It is effortless to store the ingested documents (i.e. Node objects), index metadata, etc to MongoDB using the inbuilt abstractions in LlamaIndex. There is an option to store the “documents” as an actual collection in MongoDB using MongoDocumentStore. There is an option to persist the “Indexes” using the MongoIndexStore .
Storing LlamaIndex’s documents and indexes in a database becomes necessary in a couple of scenarios:
- Use cases with large datasets may require more than in-memory storage.
- Ingesting and processing data from various sources (for example, PDFs, Google Docs, Slack).
- The requirement to continuously maintain updates from the underlying data sources.
Being able to persist this data enables processing the data once and then being able to query it for various downstream applications.

MongoDB Atlas
MongoDB offers a free forever Atlas cluster in the public cloud service of your choice. This can be accomplished very quickly by following this tutorial. Or you can get started directly here.
Use of LLMs
LlamaIndex uses LangChain’s (another popular framework for building Generative AI applications) LLM modules and allows for customizing the underlying LLM to be used (default being OpenAI’s text-davinci-003 model). The chosen LLM is always used by LlamaIndex to construct the final answer and is sometimes used during index creation as well.
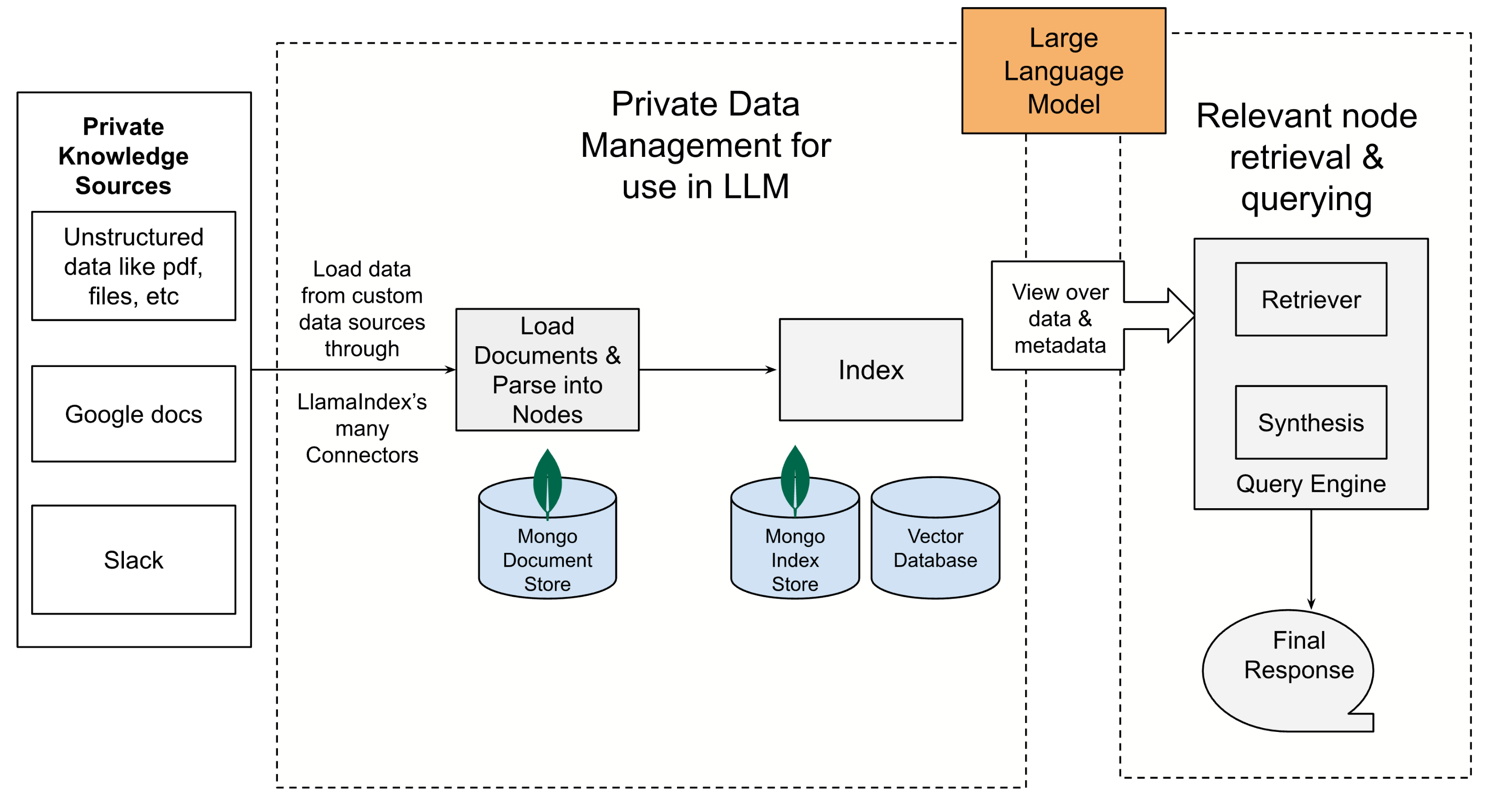
The workflow
- Connect private knowledge sources using LlamaIndex connectors (offered through LlamaHub).
- Load in the Documents. A Document represents a lightweight container around the data source.
- Parse the Documents objects into Node objects. Nodes represent “chunks” of source Documents (ex. a text chunk). These node objects can be persisted to a MongoDB collection or kept in memory.
- Construct Index from Nodes. There are various kinds of indexes in LlamaIndex like “List Index” (this stores nodes as Sequential chain), “Vector Store Index” (this stores each node and a corresponding embedding in a vector store). Depending on the type of Index, these indexes can be persisted into a MongoDB collection or a Vector Database.
- Finally query the index. This is where the the query is parsed, relevant Nodes retrieved through the use of indexes, and provided as an input to a “Large Language Model” (LLM). Different types of queries can use different indexes.

Getting questions answered over your private data
We want to query the “GPT-4 Technical Report” published by OpenAI in March 2023. This was a PDF document with 100 pages. This is a recent publication, so was not included as part of the original ChatGPT training data.
Here’s the summary of the various queries we can ask the PDF.
Query
“How does GPT4 do on the bar exam?”
Response
“GPT-4 performs well on the Uniform Bar Exam, with a score in the top 10% of test takers (Table 1, Figure 4).”
LLM token usage
Total embedding token usage: 18 tokens Total LLM token usage: 1889 tokens
Query
“How much better is GPT-4 in reducing hallucinations over GPT-3.5?”
Response
“GPT-4 improves on the latest GPT-3.5 model by 19 percentage points, with significant gains across all topics.”
Query
“What issues were observed after fine-tuning GPT-4 with RHLF??”
Response
“After fine-tuning GPT-4 with RHLF, issues observed included the model becoming overly cautious in certain ways, such as refusing innocuous requests and excessively hedging or “overrefusing”. Additionally, the model was still quite brittle and sometimes exhibited undesired behaviors based on prompts where instructions to labelers were underspecified.”
Query
“What is RBRM?”
Response
“RBRM stands for Rule-Based Reward Model. It is a technique used to provide an additional reward signal to the GPT-4 policy model during PPO fine-tuning on a subset of training prompts. The RBRM takes three things as input: the prompt (optional), the output from the policy model, and a human-written rubric (e.g., a set of rules in multiple-choice style) for how this output should be evaluated. The RBRM then classifies the output based on the rubric.”
The screenshots below show how the PDF document is converted into “LlamaIndex nodes” and “LlamaIndex indices” and persisted into MongoDB.


Relevant Resources
Further details can be found here. Also check out the reference notebook below!
Reading data from MongoDB: link
Various Indexes in LlamaIndex: link
Reference Notebook
https://colab.research.google.com/drive/1SNIeLW38Nvx6MtL3-_LPS2XTIzqD4gS6?usp=sharing


