

In this blog post, we introduce a brand new LlamaIndex data structure: a Document Summary Index. We describe how it can help offer better retrieval performance compared to traditional semantic search, and also walk through an example.
Background
One of the core use cases of Large Language Models (LLMs) is question-answering over your own data. To do this, we pair the LLM with a “retrieval” model that can perform information retrieval over a knowledge corpus, and perform response synthesis over the retrieved texts using the LLM. This overall framework is called Retrieval-Augmented Generation.
Most users building LLM-powered QA systems today tend to do some form of the following:
- Take source documents, split each one into text chunks
- Store text chunks in a vector db
- During query-time, retrieve text chunks by embedding similarity and/or keyword filters.
- Perform response synthesis
For a variety of reasons, this approach provides limited retrieval performance.
Limitations of Existing Approaches
There are a few limitations of embedding retrieval using text chunks.
- Text chunks lack global context. Oftentimes the question requires context beyond what is indexed in a specific chunk.
- Careful tuning of top-k / similarity score thresholds. Make the value too small and you’ll miss context. Make the value too big and cost/latency might increase with more irrelevant context.
- Embeddings don’t always select the most relevant context for a question. Embeddings are inherently determined separately between text and the context.
Adding keyword filters are one way to enhance the retrieval results. But that comes with its own set of challenges. We would need to adequately determine the proper keywords for each document, either manually or through an NLP keyword extraction/topic tagging model. Also we would need to adequately infer the proper keywords from the query.
Document Summary Index

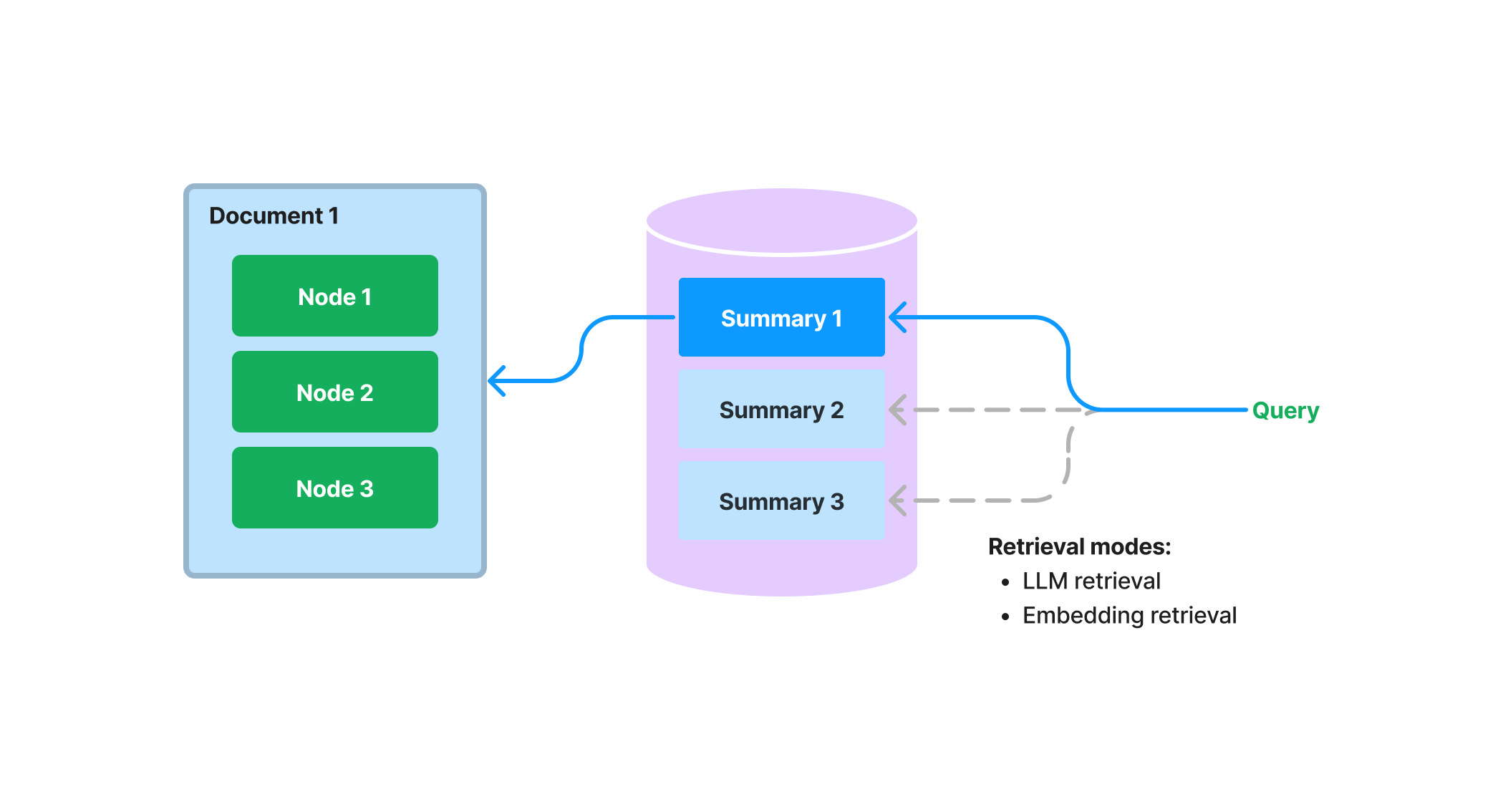
We propose a new index in LlamaIndex that will extract/index an unstructured text summary for each document. This index can help enhance retrieval performance beyond existing retrieval approaches. It helps to index more information than a single text chunk, and carries more semantic meaning than keyword tags. It also allows for a more flexible form of retrieval: we can do both LLM retrieval and embedding-based retrieval.
How It Works
During build-time, we ingest each document, and use a LLM to extract a summary from each document. We also split the document up into text chunks (nodes). Both the summary and the nodes are stored within our Document Store abstraction. We maintain a mapping from the summary to the source document/nodes.
During query-time, we retrieve relevant documents to the query based on their summaries, using the following approaches:
- LLM-based Retrieval: We present sets of document summaries to the LLM, and ask the LLM to determine which documents are relevant + their relevance score.
- Embedding-based Retrieval: We retrieve relevant documents based on summary embedding similarity (with a top-k cutoff).
Note that this approach of retrieval for document summaries (even with the embedding-based approach) is different than embedding-based retrieval over text chunks. The retrieval classes for the document summary index retrieve all nodes for any selected document, instead of returning relevant chunks at the node-level.
Storing summaries for a document also enables LLM-based retrieval. Instead of feeding the entire document to the LLM in the beginning, we can first have the LLM inspect the concise document summary to see if it’s relevant to the query at all. This leverages the reasoning capabilities of LLM’s which are more advanced than embedding-based lookup, but avoids the cost/latency of feeding the entire document to the LLM
Additional Insights
Document retrieval with summaries can be thought of as a “middle ground” between semantic search and brute-force summarization across all docs. We look up documents based on summary relevance with the given query, and then return all *nodes* corresponding to the retrieved docs.
Why should we do this? This retrieval method gives user more context than top-k over a text-chunk, by retrieving context at a document-level. But, it’s also a more flexible/automatic approach than topic modeling; no more worrying about whether your text has the right keyword tags!
Example
Let’s walk through an example that showcases the document summary index, over Wikipedia articles about different cities.
The rest of this guide showcases the relevant code snippets. You can find the full walkthrough here (and here’s the notebook link).
We can build the GPTDocumentSummaryIndex over a set of documents, and pass in a ResponseSynthesizer object to synthesize summaries for the documents.
from llama_index import (
SimpleDirectoryReader,
LLMPredictor,
ServiceContext,
ResponseSynthesizer
)
from llama_index.indices.document_summary import GPTDocumentSummaryIndex
from langchain.chat_models import ChatOpenAI
# load docs, define service context
...
# build the index
response_synthesizer = ResponseSynthesizer.from_args(response_mode="tree_summarize", use_async=True)
doc_summary_index = GPTDocumentSummaryIndex.from_documents(
city_docs,
service_context=service_context,
response_synthesizer=response_synthesizer
)Once the index is built, we can get the summary for any given document:
summary = doc_summary_index.get_document_summary("Boston")Next, let’s walk through an example LLM-based retrieval over the index.
from llama_index.indices.document_summary import DocumentSummaryIndexRetriever
retriever = DocumentSummaryIndexRetriever(
doc_summary_index,
# choice_select_prompt=choice_select_prompt,
# choice_batch_size=choice_batch_size,
# format_node_batch_fn=format_node_batch_fn,
# parse_choice_select_answer_fn=parse_choice_select_answer_fn,
# service_context=service_context
)
retrieved_nodes = retriever.retrieve("What are the sports teams in Toronto?")
print(retrieved_nodes[0].score)
print(retrieved_nodes[0].node.get_text())The retriever will retrieve a set of relevant nodes for a given index.Note that the LLM returns relevance scores in addition to the document text:
8.0
Toronto ( (listen) tə-RON-toh; locally [təˈɹɒɾ̃ə] or [ˈtɹɒɾ̃ə]) is the capital city of the Canadian province of Ontario. With a recorded population of 2,794,356 in 2021, it is the most populous city in Canada...We can also use the index as part of an overall query engine, to not only retrieve the relevant context, but also synthesize a response to a given question. We can do this through both the high-level API as well as lower-level API.
High-level API
query_engine = doc_summary_index.as_query_engine(
response_mode="tree_summarize", use_async=True
)
response = query_engine.query("What are the sports teams in Toronto?")
print(response)Lower-level API
# use retriever as part of a query engine
from llama_index.query_engine import RetrieverQueryEngine
# configure response synthesizer
response_synthesizer = ResponseSynthesizer.from_args()
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
# query
response = query_engine.query("What are the sports teams in Toronto?")
print(response)Next Steps
The approach of autosummarization over any piece of text is really exciting. We’re excited to develop extensions in two areas:
- Continue exploring autosummarization in different layers. Currently it’s at the doc-level, but what about summarizing a big text chunk into a smaller one? (e.g. a one-liner).
- Continue exploring LLM-based retrieval, which summarization helps to unlock.
Also we’re sharing the example guide/notebook below in case you missed it above:


